因为毕业以及王者荣耀的的缘故,导致我在这三个月几乎都没有在看书和学习,这段时间估计也是我最长的假期之一了。当时在之前的博客中提到会分析JDK1.8中的HashMap实现,本篇现在还是兑现之前说过的话。
之前的篇章中介绍了JDK1.7-HashMap源码分析,之前的篇章中也提到过后来会进行1.8版本的分析现在我就进入1.8版本的分析。
版本变化
在JDK1.7中采用的是链表法解决Hash冲突。这么做的好处就是实现简单,但是弊端在于当冲突比较严重的时候,查询的性能可更会退化。最极端的情况下就退化成链表的查询了(当所有的数据都在一个集中的桶(slot)中)。
在JDK1.8中为了解决这个问题特地做了一些优化,其中最重要的特征就是关于红黑树的引入。
本章作为HashMap讲解的上半部分先着重讲解一下红黑树的实现,只有充分理解了红黑树,对于后面的分析才会更加顺利。
简单介绍红黑树:作为一种平衡的二叉查找树,其主要的优点就是“平衡“,即左右子树高度几乎一致,以此来防止树退化为链表,通过这种方式来保障查找的时间复杂度为log(n)。
具体关于红黑树的内容我相信谷歌会给你更丰富的内容。下面先主要提一下红黑树的特性:
- 节点是红色或黑色。
- 根是黑色。
- 所有叶子都是黑色(叶子是NIL节点)。
- 每个红色节点必须有两个黑色的子节点。(从每个叶子到根的所有路径上不能有两个连续的红色节点。)
- 从任一节点到其每个叶子的所有简单路径都包含相同数目的黑色节点。
HashMap种关于红黑树的实现
类定义
/**
* 树节点作为Entry的一种,方便作为普通的Node使用,其实就是比Node节点多了一个before指针和after指针记录插入顺序
*/
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V>
属性分析
TreeNode<K,V> parent; //指向父节点的指针
TreeNode<K,V> left; //指向左孩子的指针
TreeNode<K,V> right; //指向右孩子的指针
TreeNode<K,V> prev; //跟next属性相反的指向
boolean red;
我们知道红黑树是一种特殊的二叉查找树,所以插入操作的前半部分跟查找二叉树一样,都是找到目标位置然后进行插入操作。但是问题在于,基本插入操作完成之后可能破坏了红黑树原有的特性。所以就一定要有调整操作,使插入后的树依然满足红黑树的特性。调整操作分为两大部分:1.结构调整 2.颜色调整
结构调整
结构调整通常有两种方式:左旋,右旋。 我们先来看看左旋:
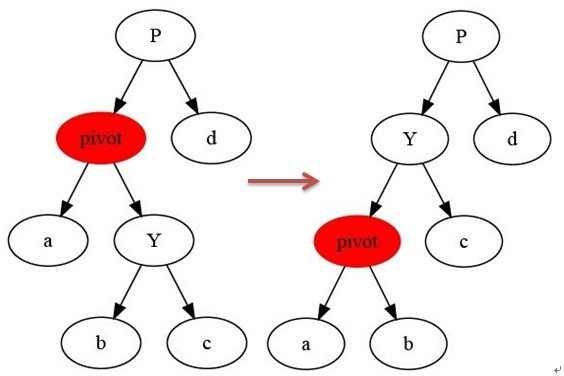
左旋的意义:不改变树的稳定性前提下,可以使左子树的深度加1,右子树的深度减1,通过这种做法来调整树的稳定性。
//流程详细变化参考下图(这里不做颜色的区分)
static <K,V> TreeNode<K,V> rotateLeft(TreeNode<K,V> root, TreeNode<K,V> p) {
//变量的命名非常讲究 : r:p的right节点,pp:p的parent节点,rl:p的右孩子的左孩子节点
TreeNode<K,V> r, pp, rl;
if (p != null && (r = p.right) != null) { //如果r为空则旋转没有意义
if ((rl = p.right = r.left) != null) //多个等号的连接操作从右往左看 rl可有可无
rl.parent = p;
if ((pp = r.parent = p.parent) == null)
(root = r).red = false; //根节点的话就设置为黑色
else if (pp.left == p) //判断p节点是左儿子还是右儿子
pp.left = r;
else
pp.right = r;
r.left = p;
p.parent = r;
}
return root;
}
这里根据上面的操作流程变化给出详细的结构变化图

//右旋跟左旋的操作完全堆成,只需要将左旋对应的方向切换一下就可以了。
static <K,V> TreeNode<K,V> rotateRight(TreeNode<K,V> root,
TreeNode<K,V> p) {
TreeNode<K,V> l, pp, lr;
if (p != null && (l = p.left) != null) {
if ((lr = p.left = l.right) != null)
lr.parent = p;
if ((pp = l.parent = p.parent) == null)
(root = l).red = false;
else if (pp.right == p)
pp.right = l;
else
pp.left = l;
l.right = p;
p.parent = l;
}
return root;
}
红黑树的核心操作就是两个,插入和删除。而这两个都是以左旋和右旋为基础进行操作的。下面我们来来HashMap中红黑树的插入操作
/**
* 红黑树的插入操作 红黑树是根据hash值来判断大小滴,切记!!
* 但是如果当前需要插入的类型和正在比较的节点的Key值是Comparable的话,就直接通过此接口比较,而不是用hash值
*/
final TreeNode<K,V> putTreeVal(HashMap<K,V> map, Node<K,V>[] tab,
int h, K k, V v) {
Class<?> kc = null;
boolean searched = false;
TreeNode<K,V> root = (parent != null) ? root() : this; //见下
for (TreeNode<K,V> p = root;;) {
int dir, ph;//dir:遍历的方向 -1:左孩子方向 1:右孩子方向 ph:p节点的hash值
K pk;
if ((ph = p.hash) > h)
dir = -1;
else if (ph < h)
dir = 1;
//本质上来说查找二叉树树不允许相同的key,所以如果key存在的话就直接返回当前节点.
//代表插入失败(插入失败并不代表HashMap在此就不会更新值,在调用方那里会做一定处理)
else if ((pk = p.key) == k || (pk != null && k.equals(pk)))
return p;
//comparableClassFor 尝试从对象x中找到一个Comparable<x.getClass()> 对象。
//在hash值相等的前提下,如果找不到可比较的对象或者比较结果相等
else if ((kc == null &&
(kc = comparableClassFor(k)) == null) ||
(dir = compareComparables(kc, k, pk)) == 0) {
if (!searched) {
TreeNode<K,V> q, ch;
searched = true;
//如果在p的左子树或者右子树中找到了目标元素
if (((ch = p.left) != null &&
(q = ch.find(h, k, kc)) != null) ||
((ch = p.right) != null &&
(q = ch.find(h, k, kc)) != null))
return q;
}
dir = tieBreakOrder(k, pk);
}
//上面的所有if-else判断都是在判断下一次进行遍历的方向,即dir
TreeNode<K,V> xp = p;
// 因为整个操作的外层是for循环,所以当下面的if判断进去之后就代表找到了目标操作元素,即xp
if ((p = (dir <= 0) ? p.left : p.right) == null) {
Node<K,V> xpn = xp.next;
TreeNode<K,V> x = map.newTreeNode(h, k, v, xpn);
if (dir <= 0)
xp.left = x;
else
xp.right = x;
xp.next = x; //因为TreeNode今后可能退化成链表,因此需要在这里维护链表的next属性
x.parent = x.prev = xp; //完成节点插入操作
if (xpn != null)
((TreeNode<K,V>)xpn).prev = x; //保证遍历顺序
//插入操作完成之后就要进行一定的调整操作了
//其实上面的插入操作核心跟二叉查找树的插入差不多,只不过多了一些Comparable的判断以及HashMap自身特性的维护
moveRootToFront(tab, balanceInsertion(root, x));
return null;
}
}
}
//获得本棵树的根节点
final TreeNode<K,V> root() {
//这里就是声明两个变量r(被初始化为this),p(没有初始化)不要被写法迷惑
for (TreeNode<K,V> r = this, p;;) {
if ((p = r.parent) == null)//沿着当前节点往上走
return r;
r = p;
}
}
/**
* 在红黑树中找到指定k的TreeNode
* 这里看起来情况很多是因为考虑了hash相同但是key值不同的情况,查找的最核心还是落在key值上,hash查找只是快而已
*/
final TreeNode<K,V> find(int h, Object k, Class<?> kc) {
TreeNode<K,V> p = this;
do {
int ph, dir; K pk;
TreeNode<K,V> pl = p.left, pr = p.right, q;
if ((ph = p.hash) > h)
p = pl;
else if (ph < h)
p = pr;
else if ((pk = p.key) == k || (k != null && k.equals(pk)))
return p;
//上面的三步都是正常的在二叉查找树中寻找对象的方法
//如果hash相等,但是内容却不相等
else if (pl == null)
p = pr;
else if (pr == null)
p = pl;
//如果可以根据compareTo进行比较的话就根据compareTo进行比较
else if ((kc != null ||
(kc = comparableClassFor(k)) != null) &&
(dir = compareComparables(kc, k, pk)) != 0)
p = (dir < 0) ? pl : pr;
//根据compareTo的结果在右孩子上继续查询
else if ((q = pr.find(h, k, kc)) != null)
return q;
//根据compareTo的结果在左孩子上继续查询
else
p = pl;
} while (p != null);
return null;
}
/**
* 当hash值相等但是不是Comparable时候使用 仅仅用作给一个全局的备选比较方案以保证一套统一的规则
*/
static int tieBreakOrder(Object a, Object b) {
int d;
//System.identityHashCode方法是Java根据对象在内存中的地址算出来的一个数值
if (a == null || b == null ||
(d = a.getClass().getName().
compareTo(b.getClass().getName())) == 0)
d = (System.identityHashCode(a) <= System.identityHashCode(b) ?
-1 : 1);
return d;
}
static <K,V> TreeNode<K,V> balanceInsertion(TreeNode<K,V> root,
TreeNode<K,V> x) {
x.red = true;
for (TreeNode<K,V> xp, xpp, xppl, xppr;;) {
//如果x节点就是根节点的话就直接涂黑 情况:图[1]
if ((xp = x.parent) == null) {
x.red = false;
return x;
}
//如果父节点是黑或者父节点的父节点是null(父节点就是根节点) 情况:图[2]
else if (!xp.red || (xpp = xp.parent) == null)
return root;
//如果xp是其父亲节点的左孩子
if (xp == (xppl = xpp.left)) {
//如果xp有兄弟节点并且兄弟节点是红色 图[3]
if ((xppr = xpp.right) != null && xppr.red) {
xppr.red = false;
xp.red = false;
xpp.red = true;
x = xpp;
}
else { 见图[4]
if (x == xp.right) {
root = rotateLeft(root, x = xp);
xpp = (xp = x.parent) == null ? null : xp.parent;
}
if (xp != null) {
xp.red = false;
if (xpp != null) {
xpp.red = true;
root = rotateRight(root, xpp);
}
}
}
}
else { //这里的代码跟上面的对称
if (xppl != null && xppl.red) {
xppl.red = false;
xp.red = false;
xpp.red = true;
x = xpp;
}
else {
if (x == xp.left) {
root = rotateRight(root, x = xp);
xpp = (xp = x.parent) == null ? null : xp.parent;
}
if (xp != null) {
xp.red = false;
if (xpp != null) {
xpp.red = true;
root = rotateLeft(root, xpp);
}
}
}
}
}
}
图1 注:下面所有图中100是我们要插入的目标节点

图2

图3 图中的节点仅仅代表整颗二叉树中的部分,200并不一定是根节点

图4 图中的节点仅仅代表整颗二叉树中的部分,200并不一定是根节点

/**
* 因为在上述的调整过程中可能会改变根节点,因此在调整后需要保证根节点处理table数组的第一个元素
*/
static <K,V> void moveRootToFront(Node<K,V>[] tab, TreeNode<K,V> root) {
int n;
if (root != null && tab != null && (n = tab.length) > 0) {
int index = (n - 1) & root.hash;
TreeNode<K,V> first = (TreeNode<K,V>)tab[index];
if (root != first) {
Node<K,V> rn;
tab[index] = root;
TreeNode<K,V> rp = root.prev;
//使rn和rp互相成为前后节点 为什么这么坐还不清楚
if ((rn = root.next) != null)
((TreeNode<K,V>)rn).prev = rp;
if (rp != null)
rp.next = rn;
//使root和first互相成为前后节点
if (first != null)
first.prev = root;
root.next = first;
root.prev = null;
}
assert checkInvariants(root);
}
}
至此,红黑树的构造过程就完成了。但是既然有构造,就有分解过程,当我们移除节点时候也需要调整树的结构和颜色。步骤跟上面的步骤比较接近,都是先调整结构然后调整颜色。因为对于红黑树的分析最主要的是需要考虑多种情况,情况比较复杂,因此在这里就不在一一写出来了(比较花时间)。
