一句话概括本文:
利用Excel存储爬到的抓取豆瓣音乐Top 250数据信息,还有读Excel。
引言:
失踪人口回归,最近比较迷茫,不知道是回头深究Android,还是继续
学Python,Android是旧爱,Python是新欢;Android应用层折腾来
折腾去,无非:改UI,写控件,换下库,换下架构...以前一直想着写
自己的项目,然后各种加东西优化,然后发现自己却没有了当年的热情,
唉!相比Python,随手就是一爬虫,批处理类的脚本,实用性高太多,
只是Python没有引路人,都是自己一点点摸索,见步走步吧!

之前在写爬小姐姐脚本时候,就遇到过一个如何存储爬取到数据的问题,
比如一个系列的套图链接应该放到特定的文件夹,我之前的操作都是
通过下面这样的格式写入到一个txt文件中:目录~链接
然后读取txt文件,获得字符串,然后通过split("~")来进行分隔,
split("~")[0]是目录,split("~")[1]是路径,挺low的,
如果是涉及到三个维度以上的再拼多一个~,在上上一节抓
半次元coser的时候就遇到一个恶心的问题,符号都他么被用了,
难以分隔,一个个特殊字符试,后面试到Θ才可以..
迫切需要一个东西来存我们抓取到的数据,当然最好用:数据库
但是考虑到学习成本(主要是我不熟!),先通过一个简单的东西存起来。

最简单的肯定是通过Excel表格啊,最直观了,非编程人员也能看懂!
不多说,开始本节内容~ 本节抓取例子:豆瓣音乐 Top 250
链接:https://music.douban.com/top250
1.编写抓数据脚本
依次校验:
- 1.数据能在Network选项卡找到,非JS动态加载,直接处理结果就好
- 2.点击第二页,选中XHR,没有东东,不是Ajax动态加载
链接规则:
第一页:https://music.douban.com/top250?start=0
第二页:https://music.douban.com/top250?start=25
第三页:https://music.douban.com/top250?start=50
链接规则显而易见,每25条一页,0,25,50,75...225
请求头:
就一个:Host:music.douban.com
模拟请求的套路摸清了,接下来就是处理网页拿到想要的数据了:
看下Element,不难发现数据都单独放在一个个table里:
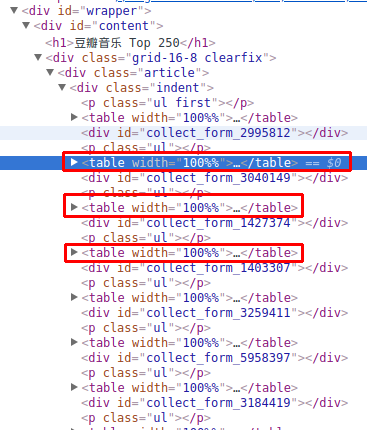
点开其中一个:
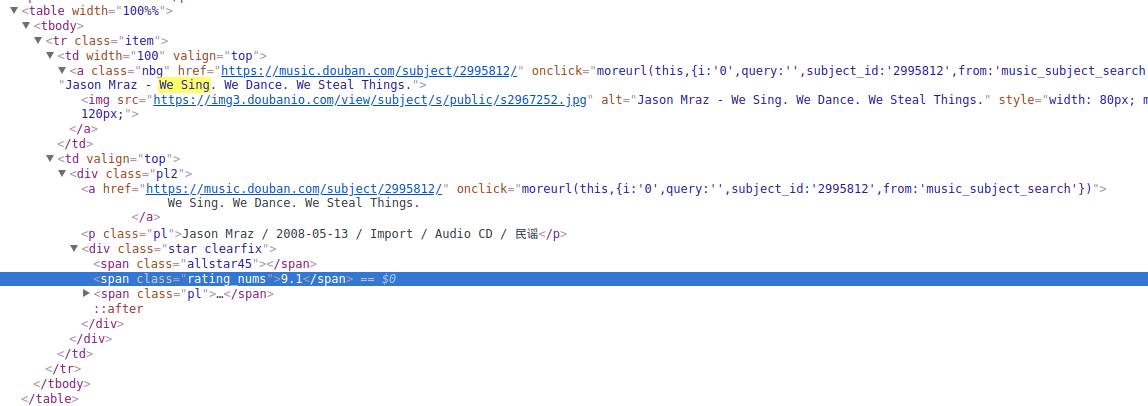
先捋下我们想采集到的数据:
图片链接,歌名,歌手,发行时间,分类,评分,评分人数,歌曲详情页
然后就是慢慢抠数据了,自己私下抠,不会抠找以前文章看,
这里直接给出代码:
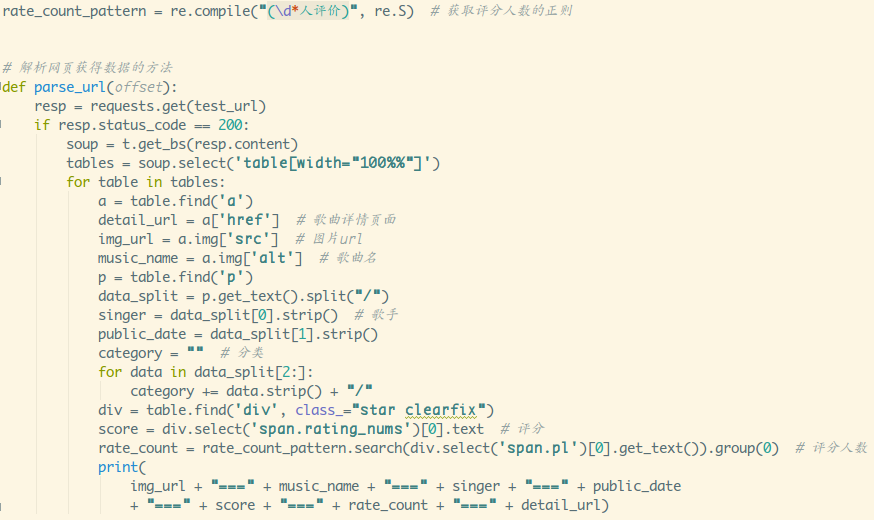
看下控制台打印出来的信息:

可以,没毛病,接下来看下怎么把数据写到excel表格里~
2.如何将数据写入到Excel中
Step 1:安装库,操作Excel,你需要两个库:xlwt(写Excel) 和 xlrd(读Excel)
命令行pip安装一波。
sudo pip3 install xlwt
sudo pip3 install xlrd
Step 2:熟悉几个基本函数
写入Excel:
-
xlwt.
Workbook():创建一个工作薄 - 工作薄对象.
add_sheet(cell_overwrite_ok=True):添加工作表,括号里是可选
参数,用于确认同一个cell单元是否可以重设值 - 工作表对象.
write(行号,列号,插入数据,风格),第四个参数可选
举个简单例子:插入这样的数据:
sheet.write(0,0,"姓名")
sheet.write(0,1,"学号")
sheet.write(1,0,"小猪")
sheet.write(1,1,"No1")
得到的表格:

- 工作薄对象.
save(Excel文件名):保存到Excel文件中
读取Excel:
- xlrd.
open_workbook():读取一个Excel文件获得一个工作薄对象 - 工作薄对象.
sheets()[0]:根据索引获得工作薄里的一个工作表 - 工作表对象.
nrows:获得行数 - 工作表对象.
ncols:获得列数 - 工作表对象.
row_values(pos):读取某一行的数据,返回结果是列表类型的
3.编写一个Excel协助类
基本语法了解得差不多了,接着我们来写一个工具类,来把我们爬虫
爬取到的数据写入到Excel表格里,四个方法:
style:根据传入的字体名称,高度,是否加粗,返回一个Style样式
__init__:完成Excel表的一些初始化操作,初始化表头
insert_data:把爬取到的数据插入到Excel里的方法
read_data:读取Excel里数据的方法
接着一步步来,先是style方法:

接着是__init__方法,判断Excel文件是否存在,不存在则新建并进行初始化

再接着是insert_data:
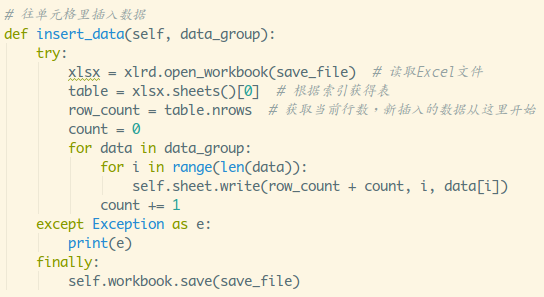
最后是read_data:

代码不算复杂,接着写下调用代码试试:
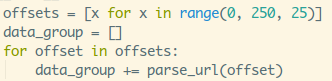
加一个打印data_group的方法,看下抓取的数据,运行下:
没毛病,圈住哪里[[,这里想表达结果是一个大列表嵌套多个列表!
再接着添加下述代码:

执行后可以看到,生成了一个dbyy.xlsx的文件,打开看看:
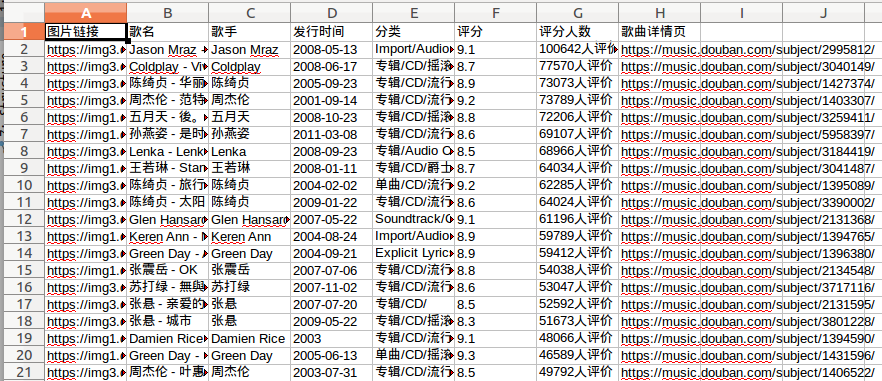
啧啧,写入成功,美滋滋!
再接着把无关代码注释掉,调用下读取Excel的方法:

读写都没问题,嘤嘤嘤~

4.小结
本节讲解了一波如何把爬取到的数据存到Excel表里,以及读取Excel表里的数据,
虽然没有数据库高端,但是比起之前用分隔符分隔多中类型的数据,用到的时候
split()好多了,而且非开发者也能直接看懂,除此之外,哪天说不定可以撩到
一些文员小姐姐(编写批处理Excel表的脚本),除此之外还可以做些词频统计类
的脚本玩玩,最后献上哲♂学启蒙老师照片来结束本节内容,愿天堂没有摔跤:

附:具体实现代码(其实都可以在https://github.com/coder-pig/ReptileSomething 找到)
import re
import requests
import xlwt
import xlrd
import tools as t
rate_count_pattern = re.compile("(\d*人评价)", re.S) # 获取评分人数的正则
base_url = 'https://music.douban.com/top250'
save_file = 'dbyy.xlsx'
# 解析网页获得数据的方法
def parse_url(offset):
resp = requests.get(base_url, params={'page': offset})
print("解析:" + resp.url)
result = []
if resp.status_code == 200:
soup = t.get_bs(resp.content)
tables = soup.select('table[width="100%%"]')
for table in tables:
a = table.find('a')
detail_url = a['href'] # 歌曲详情页面
img_url = a.img['src'] # 图片url
music_name = a.img['alt'] # 歌曲名
p = table.find('p')
data_split = p.get_text().split("/")
singer = data_split[0].strip() # 歌手
public_date = data_split[1].strip()
category = "" # 分类
for data in data_split[2:]:
category += data.strip() + "/"
div = table.find('div', class_="star clearfix")
score = div.select('span.rating_nums')[0].text # 评分
rate_count = rate_count_pattern.search(div.select('span.pl')[0].get_text()).group(0) # 评分人数
result.append([img_url, music_name, singer, public_date, category, score, rate_count, detail_url])
return result
class ExcelHelper:
def __init__(self):
if not t.is_dir_existed(save_file, mkdir=False):
# 1.创建工作薄
self.workbook = xlwt.Workbook()
# 2.创建工作表,第二个参数用于确认同一个cell单元是否可以重设值
self.sheet = self.workbook.add_sheet(u"豆瓣音乐Top 250", cell_overwrite_ok=True)
# 3.初始化表头
self.headTitles = [u'图片链接', u'歌名', u'歌手', u'发行时间', u'分类', u'评分', u'评分人数', u'歌曲详情页']
for i, item in enumerate(self.headTitles):
self.sheet.write(0, i, item, self.style('Monaco', 220, bold=True))
self.workbook.save(save_file)
# 参数依次是:字体名称,字体高度,是否加粗
def style(self, name, height, bold=False):
style = xlwt.XFStyle() # 赋值style为XFStyle(),初始化样式
font = xlwt.Font() # 为样式创建字体样式
font.name = name
font.height = height
font.bold = bold
return style
# 往单元格里插入数据
def insert_data(self, data_group):
try:
xlsx = xlrd.open_workbook(save_file) # 读取Excel文件
table = xlsx.sheets()[0] # 根据索引获得表
row_count = table.nrows # 获取当前行数,新插入的数据从这里开始
count = 0
for data in data_group:
for i in range(len(data)):
self.sheet.write(row_count + count, i, data[i])
count += 1
except Exception as e:
print(e)
finally:
self.workbook.save(save_file)
# 读取Excel里的数据
def read_data(self):
xlsx = xlrd.open_workbook(save_file)
table = xlsx.sheets()[0]
nrows = table.nrows # 行数
ncols = table.ncols # 列数
# 从第一行开始,0是表头
for i in range(1, nrows):
# 读取某行数据
row_value = table.row_values(i)
print(row_value)
if __name__ == '__main__':
offsets = [x for x in range(0, 250, 25)]
data_group = []
for offset in offsets:
data_group += parse_url(offset)
print(data_group)
excel = ExcelHelper()
excel.insert_data(data_group)
excel.read_data()
来啊,Py交易啊
想加群一起学习Py的可以加下,智障机器人小Pig,验证信息里包含:
Python,python,py,Py,加群,交易,屁眼 中的一个关键词即可通过;

验证通过后回复 加群 即可获得加群链接(不要把机器人玩坏了!!!)~~~
欢迎各种像我一样的Py初学者,Py大神加入,一起愉快地交流学♂习,van♂转py。

