Okio 源码分析
Okio , Java, Java IO
OkIo 是 OKHTTP 中使用的 一个 IO的框架,它主要是对Java的IO进行了一次封装!相比于Java IO它有更加简洁优雅的API,同时在性能和内存的消耗上也有一定优势。
首先了解几个类:
- Sink : 这个接口用于描述 OutputStream ,功能可以类比Java中的OutputStream
- Source : 这个接口用于描述 InputStream , 功能可以类比Java中的InputStream
- Okio : 这是个工具类,用于提供了 包装 生成 Sink 和 Source 的静态方法
- Buffer: 这是一个持有字节数组的类,可以看成Java中的byte[],但是它的实现比较有意思,后面会详细的介绍
我们来分析 一个 Sink 的写入行为:
// 获取 file 引用,如果文件就删除
File file = removeExistsFile();
// 获取一个 Sink 的 引用
Sink sink = Okio.sink(file); (#1)
// 构建一个 Buffer ,用于缓存我们写入的数据
Buffer buffer = new Buffer(); (#2)
buffer.writeUtf8("hello");
// 将缓存写到 sink 中
sink.write(buffer, buffer.size()); (#3)
sink.flush();
-
#1处 我们 通过静态方法 获取了 Sink 引用 , 进一步分析:
public static Sink sink(File file) throws FileNotFoundException {
if (file == null) throw new IllegalArgumentException("file == null");
return sink(new FileOutputStream(file));
}
public static Sink sink(OutputStream out) {
return sink(out, new Timeout());
}
private static Sink sink(final OutputStream out, final Timeout timeout) {
if (out == null) throw new IllegalArgumentException("out == null");
if (timeout == null) throw new IllegalArgumentException("timeout == null");
// 在这里 实例化 一个 Sink 对象 返回 ,其实这个Sink 就是 包装了 OutputStream
return new Sink() {
@Override public void write(Buffer source, long byteCount) throws IOException {
// 检查写入的字节数组的数据
checkOffsetAndCount(source.size, 0, byteCount);
while (byteCount > 0) {
// 检查是否超时
timeout.throwIfReached();
// 首先获取 将要写入的字节数组的 头Segment
Segment head = source.head;
// 取出 byteCount 和 头Segment 的可读区域的最小值
int toCopy = (int) Math.min(byteCount, head.limit - head.pos);
out.write(head.data, head.pos, toCopy);
head.pos += toCopy;
byteCount -= toCopy;
source.size -= toCopy;
// 如果 头Segment没有可读字节了,代表当前Segment被消费完毕,
// 将head从双向环形链表中移除,会移动head指向下一个Segment ,这样如果当head的Segment空间不足,下一次循环会将数据写到下一个head中 , 并且尝试使用 SegmentPool 回收 该Segment
if (head.pos == head.limit) {
source.head = head.pop();
SegmentPool.recycle(head);
}
}
}
@Override public void flush() throws IOException {
out.flush();
}
@Override public void close() throws IOException {
out.close();
}
@Override public Timeout timeout() {
return timeout;
}
@Override public String toString() {
return "sink(" + out + ")";
}
};
}
我们可以看出,上面的Sink 就是 对 OutputStream的一个包装,重点是这里的 write 方法,这里涉及到了 Buffer 的内部结构,从头部Segment开始不断的消费数据,然后将已经消费的数据,回收
-
#2中我们实例化了一个 Buffer ,并且在后面写入了一个UTF-8的字符串!这里我们来分析下Buffer的内部实现,这也是 Okio 最与众不同的地方:
/** 首先我们来看它的注释
* A collection of bytes in memory. (内存中字节的集合)
*
* <p><strong>Moving data from one buffer to another is fast.</strong> Instead
* of copying bytes from one place in memory to another, this class just changes
* ownership of the underlying byte arrays. )
* 它的移动数据从一个Buffer到另一个Buffer很快,这里使用的不是从一个Buffer拷贝内存到另一个,而是直接复用之前的内存片段,所以很快,也可以节省很多的内存分配,节省CPU时间(复制内存是需要CPU运算的)
*
*
* <p><strong>This buffer grows with your data.</strong> Just like ArrayList,
* each buffer starts small. It consumes only the memory it needs to.
* 可以自动的增长,如果使用Java的自己数组,要指定数组的大小,当原数组大小不足,就要自己手动的复制数据,Okio 已经帮我们做好了这些
*
* <p><strong>This buffer pools its byte arrays.</strong> When you allocate a
* byte array in Java, the runtime must zero-fill the requested array before
* returning it to you. Even if you're going to write over that space anyway.
* This class avoids zero-fill and GC churn by pooling byte arrays.
* Buffer的字节数组,是被池化的,当你申请一块Java的内存的时候,JVM会自动的初始化这块内存,会将字节数组填充为0,OKio里使用SegmentPool 池化管理 Buffer 的 Segment ,可以复用之前申请的内存
*/
Buffer 类的注释,已经比较详细的介绍了,Buffer的优点:
- 减少了,内存中不断Copy的成本,可以复用Segment
- 相比与原生Java,更容易使用的API(自动增长等)
再来介绍下Buffer类内部结构:
Segment head;
long size;
如上代码片段,Buffer中,只有两个类变量!head,用于指定 head 的Segment,size 用于指定Buffer的大小。
说这里,我们必须要详细的介绍下 Segment 这个类了!
Segment类正如它的名字,就是 byte 数组的片段,在Buffer中,使用 双向循环链表管理 Segment , 在SegmentPool中 使用一个单向链表管理Segment!
下面解释下Segment类中的字段:
// 指定一个Segment data 域的大小
static final int SIZE = 8192;
// Segment分享的阀值,超过这个大小的Segment,就不再使用复制的方法共享数据而是直 // 接共享Segment
static final int SHARE_MINIMUM = 1024;
// Segment的数据域,大小是上面的SIZE
final byte[] data;
// 读指针
int pos;
// 写指针
int limit;
// 一个Segment是否被分享,如果被分享了,那么一般来说它就不能够再被修改了
boolean shared;
// 表示这个Segment是否可以被修改!
boolean owner;
// next指针,指向下一个Segment,用于SegmentPool 链表 和 Buffer 中的双向循环链表
Segment next;
// prev 指针,指向双向链表中的上一个元素
Segment prev;
我们依次来讲讲 Segment的方法:
// 构造方法,默认大小为 SIZE 的data域,设置为修改,没有分享
Segment() {
this.data = new byte[SIZE];
this.owner = true;
this.shared = false;
}
// 构造方法,直接复用了data , 设置了 读写指针,不可修改,共享状态
Segment(byte[] data, int pos, int limit) {
this.data = data;
this.pos = pos;
this.limit = limit;
this.owner = false;
this.shared = true;
}
// 从一个旧的Segment中,直接复用数据域,相当于 浅拷贝一份原本的Segment,
// 并且将原来的Segment的状态改为分享
Segment(Segment shareFrom) {
this(shareFrom.data, shareFrom.pos, shareFrom.limit);
shareFrom.shared = true;
}
// 从双向循环链表中,移除当前的元素
// 如果当前为空则返回null
public @Nullable Segment pop() {
Segment result = next != this ? next : null;
prev.next = next;
next.prev = prev;
next = null;
prev = null;
return result;
}
// 向双向循环链表中插入数据
public Segment push(Segment segment) {
segment.prev = this;
segment.next = next;
next.prev = segment;
next = segment;
return segment;
}
// 这个方法,用于将当前的Segment 分割为两个Segment
// 前一个Segment大小为 [pos , pos + byteCount]
// 后一个Segment大小为 [pos + byteCount , limit)
// 这个用于将大的Segment ,分割成小的
public Segment split(int byteCount) {
if (byteCount <= 0 || byteCount > limit - pos) throw new IllegalArgumentException();
Segment prefix;
// 如果byteCount比较大,我们就不分了,直接复用当前的Segment
// byteCount 太大 复制的成本就比较大,需要内存
if (byteCount >= SHARE_MINIMUM) {
prefix = new Segment(this);
} else {
prefix = SegmentPool.take();
System.arraycopy(data, pos, prefix.data, 0, byteCount);
}
prefix.limit = prefix.pos + byteCount;
pos += byteCount;
prev.push(prefix);
return prefix;
}
// 用于将小的 Segment(单个Segment 的利用率 不足 50% ) ,合并成一个大的,
// 将原本小的 ,Segment 放入 Pool 中
public void compact() {
if (prev == this) throw new IllegalStateException();
if (!prev.owner) return; // Cannot compact: prev isn't writable.
// 算出当前的 已经使用的 大小
int byteCount = limit - pos;
// 要存放数据的Segment剩余的大小
int availableByteCount = SIZE - prev.limit + (prev.shared ? 0 : prev.pos);
// 如果没有足够的大小则,直接返回
if (byteCount > availableByteCount) return;
// 若果有足够的大小,则将当前Segment数据写到 prev 中
writeTo(prev, byteCount);
// 移除当前的Segment
pop();
// 回收 当前Segment
SegmentPool.recycle(this);
}
// 用于将当前的数据写到目标sink中
public void writeTo(Segment sink, int byteCount) {
if (!sink.owner) throw new IllegalArgumentException();
// 如果 目标Segment的剩余大小不足!
if (sink.limit + byteCount > SIZE) {
// 如果目标Segment被分享了,则原本数据不能修改,直接抛异常
if (sink.shared) throw new IllegalArgumentException();
// 如果目标Segment,没有共享
// 则尝试 抹去 pos之前的数据 , 再看大小够不够
if (sink.limit + byteCount - sink.pos > SIZE) throw new IllegalArgumentException();
// 如果够了的话,则将pos之前的数据抹去,
// 这里 就是将原本数据 的数据前移 pos 位
System.arraycopy(sink.data, sink.pos, sink.data, 0, sink.limit - sink.pos);
// 抹去原本的pos指针
sink.limit -= sink.pos;
sink.pos = 0;
}
// 目标大小必定是足够的,直接拷贝数据
System.arraycopy(data, pos, sink.data, sink.limit, byteCount);
// 移动 目标Segment的写指针
sink.limit += byteCount;
// 移动当前目标的读指针
pos += byteCount;
}
我们已经分析了,Segment 的字段和方法,很容易看出,Segment就是一段byte[]数组的管理的对象,不过有读指针和写指针,当需要复用内部的byte[]数组的时候,可以 直接分享 Segment 而不是 复制数据!
之前的Buffer的源码中,只有一个 head的 Segment 的字段,其实这个head就是双向数据链表的头部,Buffer中Segment组成了一个双向循环链表!以此来管理数据!当需要和别的Buffer共享内存片段的时候,我们不是自己复制字节数组,而是想办法去共享Segment!
Buffer 结构下图:
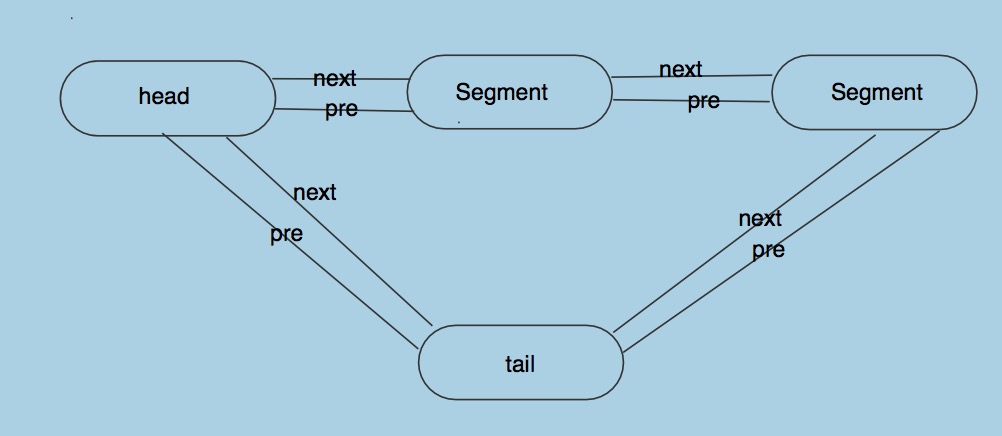
Buffer的head和其他的Segment,组成了一个环形的链表,head 的 pre就是 链表的尾结点
在看Buffer中是具体怎么使用 Segment之前,我们先看一下,SegmentPool是怎么管理,回收和复用Segment的,它的代码非常简单。
// 这个 SegmentPool代码很简洁
// 主要的思路就是使用 Segment中的next指针,构成一个单链表,管理和分配Segment
// 每次 申请一块Segment时候,先查看,缓存的队列是不是空的,空的话,就直接新建一个Segment返回
// 如果不为空,则清空原来的Segment的数据,返回缓存的Segment
final class SegmentPool {
/** The maximum number of bytes to pool. */
// TODO: Is 64 KiB a good maximum size? Do we ever have that many idle segments?
// 缓存的 Segment的最大的内存大小
static final long MAX_SIZE = 64 * 1024; // 64 KiB.
/** Singly-linked list of segments. */
// 缓存队列的 头部指针
static @Nullable Segment next;
/** Total bytes in this pool. */
// 缓存池中,缓存的字节数目
static long byteCount;
// 私有的构造方法,因为这个类不需要实例化
private SegmentPool() {
}
// 在 通过SegmentPool去获取一个Segment的实例,
// 如果,next 为 null 则表示队列为null(当前没有Segment被回收!),新建一个Segment返回
// next 不为空,则取队列的头Segment,next 移动到下一个元素
// byteCount 减去 Segment.SIZE
static Segment take() {
synchronized (SegmentPool.class) {
if (next != null) {
Segment result = next;
next = result.next;
result.next = null;
byteCount -= Segment.SIZE;
return result;
}
}
return new Segment(); // Pool is empty. Don't zero-fill while holding a lock.
}
// 回收方法
// 如果 回收的Segment的next 和 pre 不为空,或者 Segment 已经被分享是无法被回收的
static void recycle(Segment segment) {
if (segment.next != null || segment.prev != null) throw new IllegalArgumentException();
if (segment.shared) return; // This segment cannot be recycled.
synchronized (SegmentPool.class) {
// 如果 缓存的字节数的大小,大于 MAX_SZIE,则不缓存了
if (byteCount + Segment.SIZE > MAX_SIZE) return; // Pool is full.
byteCount += Segment.SIZE;
// 将新来的Segment插入到 队列的头部,并且清除 pos 和 limit
segment.next = next;
segment.pos = segment.limit = 0;
next = segment;
}
}
}
我们看到了 SegmentPool 是如何管理Segment的了,下面进入重点,Buffer的源码:
由于Buffer的代码量比较大,我们只看几个重要方法(在Sink和Source中,经常被使用的方法) !
// 将 Buffer 复制到 OutputStream 中!
public Buffer copyTo(OutputStream out, long offset, long byteCount) throws IOException {
if (out == null) throw new IllegalArgumentException("out == null");
checkOffsetAndCount(size, offset, byteCount);
if (byteCount == 0) return this;
// 找到开始写入的 Segment
Segment s = head;
for (; offset >= (s.limit - s.pos); s = s.next) {
offset -= (s.limit - s.pos);
}
// 将 数据 写到outputStream中
for (; byteCount > 0; s = s.next) {
int pos = (int) (s.pos + offset);
int toCopy = (int) Math.min(s.limit - pos, byteCount);
out.write(s.data, pos, toCopy);
byteCount -= toCopy;
offset = 0;
}
return this;
}
// 这个方法,将数据拷贝到,另一个 Buffer 中。
public Buffer copyTo(Buffer out, long offset, long byteCount) {
if (out == null) throw new IllegalArgumentException("out == null");
checkOffsetAndCount(size, offset, byteCount);
if (byteCount == 0) return this;
out.size += byteCount;
// Skip segments that we aren't copying from.
Segment s = head;
for (; offset >= (s.limit - s.pos); s = s.next) {
offset -= (s.limit - s.pos);
}
for (; byteCount > 0; s = s.next) {
// 直接新建一个 Segment 对象,这里复用了 原本的 Segment
Segment copy = new Segment(s);
copy.pos += offset;
copy.limit = Math.min(copy.pos + (int) byteCount, copy.limit);
// 如果 头 为空,则代表还没有数据,当前Segment直接作为 Head
if (out.head == null) {
out.head = copy.next = copy.prev = copy;
} else {
// 将Segment放入 双向循环链表中!
out.head.prev.push(copy);
}
byteCount -= copy.limit - copy.pos;
offset = 0;
}
return this;
}
我们再来看下,一个很重要的方法,这个方法里用到了 Segment 里的一些复杂的API:
// 这里源码中注释很长,我们直接,解释意思:
// 这个方法,将 source Segment写入到 当前 Segment中
// 这里也是 直接 复用 Segment的数据,而不是 Copy 数据!
// Buffer中,除了头结点和尾结点,其他结点的,数据域使用率,应该不低于50%
// 当我们 向一个 Buffer [91%, 61%] 中写入另一个Buffer [72%] 的时候
// 我们直接将72%的Segment , 放入 Buffer 队列中,得到新的 [91%, 61%, 72%] ,没有任何拷贝!
// 当我们有 [100%, 2%] , 写入 [99%, 3%] , 最终会是 [100%, 2%, 99%, 3%]
// 但是如果有 [100%, 40%] ,写入 [30%, 80%] ,最终会是 [100%, 70%, 80%]
// 也就是,如果相临近的两个Segment的和小于 100 %,则就会将他们压缩 (使用的Segment的 compact 方法)
// 有时候,我们可能会只写一部分 数据!例如,[92%, 82%] ,我们将他的前 30% 写入
// [51%, 91%],那么我们这时候,会将原来的[92%, 82%] , 分裂 [30%, 62%, 82%],
// 最终结果 是 [51%, 91%, 30%] (使用的Segment的 split 方法)
@Override public void write(Buffer source, long byteCount) {
if (source == null) throw new IllegalArgumentException("source == null");
if (source == this) throw new IllegalArgumentException("source == this");
checkOffsetAndCount(source.size, 0, byteCount);
while (byteCount > 0) {
// 如果byteCount 比较小,只涉及到 source Buffer的头Segment
if (byteCount < (source.head.limit - source.head.pos)) {
// 获取队列的尾部,双向循环队列,head的pre就是尾部
Segment tail = head != null ? head.prev : null;
// 如果我们 当前 Buffer的尾部 足够,则直接复制到数据到尾部!
if (tail != null && tail.owner
&& (byteCount + tail.limit - (tail.shared ? 0 : tail.pos) <= Segment.SIZE)) {
source.head.writeTo(tail, (int) byteCount);
source.size -= byteCount;
size += byteCount;
return;
} else {
// 如果当前的Buffer 的尾部空间不够,我们将 source 分开一部分!大小为 byteCount
source.head = source.head.split((int) byteCount);
}
}
// 剩下的 操作都是 跨越 source 中至少两个Segment的
Segment segmentToMove = source.head;
long movedByteCount = segmentToMove.limit - segmentToMove.pos;
// 直接 将 Head 从source中弹出!
source.head = segmentToMove.pop();
// 如果当前队列为空,则直接复用Head
if (head == null) {
head = segmentToMove;
head.next = head.prev = head;
} else {
//不为空则,将其写入到当前的尾部,并且尝试,压缩下,防止过多的零碎的Segment
Segment tail = head.prev;
tail = tail.push(segmentToMove);
tail.compact();
}
source.size -= movedByteCount;
size += movedByteCount;
byteCount -= movedByteCount;
}
}
我们已经了解了整个Buffer的内部结构,其核心就是使用Segment去分段的管理byte数组,然后尽量的复用Segment,而不是copy 字节数组,从而提高性能!
Okio 中还提供了一些,ByteString整个类,帮助我们做数据从byte数组的一些转换,如提供了 base64Url,和 utf8 等转换方法!
我们之前的例子,我们自己实例化了一个Buffer,然后用于缓存写入,最后,将整个Buffer写入到Sink中!其实Okio已经提供了包装类 RealBufferedSink
理解了上面的Buffer(OKio提供的独特的字节数组管理类)和Sink(对Java OutputStream 的包装!提供超时,以及写入Buffer等方法) ,再看这个类的时候,还是比较简单的。
RealBufferedSink:它就是一个 Buffer + Sink ,它的数据先写到 Buffer中,然后等到某个时候再写到Sink中,内部管理了一个Buffer,相当于提供了一个缓冲。
//将一个 buffer 写入到 Sink 中
@Override public void write(Buffer source, long byteCount)
throws IOException {
if (closed) throw new IllegalStateException("closed");
// 现将数据写入 缓冲的Buffer中
buffer.write(source, byteCount);
emitCompleteSegments();
}
@Override public BufferedSink emitCompleteSegments() throws IOException {
if (closed) throw new IllegalStateException("closed");
// completeSegmentByteCount 方法 ,返回 可以写入 sink 中的字节的数量
long byteCount = buffer.completeSegmentByteCount();
// sink 的 write ,我们在前面说过了哦(就是对OutputStream的包装)
if (byteCount > 0) sink.write(buffer, byteCount);
return this;
}
下面我们再来说下,OKio的 TimeOut :
TimeOut 正如它的名字,给我们一种设置超时的能力,后面我们将会看到它配合Sink或者Source使用
Timeout类的注释中有两点,我们需要特别的注意:
Timeouts:提供了,单次操作的最长时间限制,一般可以用于网络行为,远程调用等
Deadlines : 这次任务的最大用时限制,通过它可以设置这次任务的最大用时,一次任务,可能包括多次的单操作!
TimeOut类的三个字段
// 是否有 deadLine
private boolean hasDeadline;
// deadLine 的时间 (时间点)
private long deadlineNanoTime;
// timeout的时间 (一段时间,0代表无穷大)
private long timeoutNanos;
前面我们在分析Sink的源码中,发现 Sink的 write 方法中,每次都调用了 throwIfReached 方法:
public void throwIfReached() throws IOException {
if (Thread.interrupted()) {
throw new InterruptedIOException("thread interrupted");
}
//就是检查 当前是否到达 deadlineNanoTime ,如果到达了,就直接抛出异常
// 不过我们在Sink中,并没有设置deadlineNanoTime ,所以不会抛异常
if (hasDeadline && deadlineNanoTime - System.nanoTime() <= 0) {
throw new InterruptedIOException("deadline reached");
}
}
再看下TimeOut中最长的一个方法,用于同步等待任务的完成:
// 该方法,使用前必须已经获取 monitor 的内置锁了
public final void waitUntilNotified(Object monitor) throws InterruptedIOException {
try {
boolean hasDeadline = hasDeadline();
long timeoutNanos = timeoutNanos();
// 如果没有设置deadLineTime ,并且 timeout为0,那么无限的等待
if (!hasDeadline && timeoutNanos == 0L) {
monitor.wait(); // There is no timeout: wait forever.
return;
}
// 根据 deadLineTime 和 timeOut 计算出,要等待的时间
long waitNanos;
long start = System.nanoTime();
if (hasDeadline && timeoutNanos != 0) {
long deadlineNanos = deadlineNanoTime() - start;
waitNanos = Math.min(timeoutNanos, deadlineNanos);
} else if (hasDeadline) {
waitNanos = deadlineNanoTime() - start;
} else {
waitNanos = timeoutNanos;
}
long elapsedNanos = 0L;
if (waitNanos > 0L) {
long waitMillis = waitNanos / 1000000L;
// 等待
monitor.wait(waitMillis, (int) (waitNanos - waitMillis * 1000000L));
elapsedNanos = System.nanoTime() - start;
}
// 如果唤醒后发现,等待时间已经大于外滩Nanos了,那么直接抛出超时异常
if (elapsedNanos >= waitNanos) {
throw new InterruptedIOException("timeout");
}
} catch (InterruptedException e) {
throw new InterruptedIOException("interrupted");
}
}
除了上面的TimeOut , 还有一种 AsyncTimeout ,一般用在 Socket中:
// 实例化一个Sink,包装了 Socket的方法如下:
public static Sink sink(Socket socket) throws IOException {
if (socket == null) throw new IllegalArgumentException("socket == null");
// 构造 timeout
AsyncTimeout timeout = timeout(socket);
// new 一个 Sink 对象
Sink sink = sink(socket.getOutputStream(), timeout);
return timeout.sink(sink);
}
我们来看 AsyncTimeout 的内部实现:
其实在其内部,维护了一个 AsyncTimeout 的队列,并且它内部包装了 Sink 和 Source,然后对Sink和Source的操作,都添加了 enter ,使他们能够支持 TimeOut。
在 AsyncTimeout 内部还有一个 Watchdog 线程,这个线程一直在 检查 之前说到的AsyncTimeout内部队列中的AsyncTimeout,如果某个AsyncTimeout被检测出超时了,那么Watchdog线程就会调用它的 timedOut 方法!
我们再返回Okio类中,继续看之前的对Socket 的 Sink 的包装,这里主要的就是,构造了一个新的AsyncTimeout , 并且复写了timedOut方法。
private static AsyncTimeout timeout(final Socket socket) {
return new AsyncTimeout() {
@Override protected IOException newTimeoutException(@Nullable IOException cause) {
InterruptedIOException ioe = new SocketTimeoutException("timeout");
if (cause != null) {
ioe.initCause(cause);
}
return ioe;
}
// 复写了 timedOut , 这个方法是会被WatchDog 检测为超时时候调用
// 这里直接关闭Socket
@Override protected void timedOut() {
try {
socket.close();
} catch (Exception e) {
logger.log(Level.WARNING, "Failed to close timed out socket " + socket, e);
} catch (AssertionError e) {
if (isAndroidGetsocknameError(e)) {
// Catch this exception due to a Firmware issue up to android 4.2.2
// https://code.google.com/p/android/issues/detail?id=54072
logger.log(Level.WARNING, "Failed to close timed out socket " + socket, e);
} else {
throw e;
}
}
}
};
}
简单的使用 TimeOut:
File file = newFile("./test1.txt");
BufferedSink sink = Okio.buffer(Okio.sink(file));
sink.timeout().deadline(3, TimeUnit.SECONDS);
// 模拟 一次 耗时操作
Thread.sleep(3000);
Buffer wordBuffer = new Buffer().writeUtf8("hello");
sink.write(wordBuffer, wordBuffer.size());
sink.flush();
如上代码,我们设置了Sink的deadline时间,然后模拟了一次耗时操作,最后我们将会得到超时的异常
至此,我们的Okio源码分析,已经结束,回顾总结下:
- Okio 中的Sink 和 Source 就是 对Java的Output和Input流的包装!在这里整合了超时等机制。
- Okio 还提供了 Sink 和Source的缓存版本,
RealBufferedSink和RealBufferedSource他们内部使用Okio的Buffer 缓冲! - Okio的Buffer,内部使用Segment管理字节数组,当要将一个Buffer写入到另一个Buffer的时候,可以直接共享Segment,而不是拷贝内存数据!
- Okio提供了TimeOut,特别是 AsyncTimeout ,能够简单的帮助我们做超时处理
- Okio提供了相比与Java API 更加优雅好用的API!
我们 Okio 就分析到这里,后面我们会分析Okio在OkHttp中的使用,以及OkHttp的源码
