介绍
用到的开源组件及其版本如下:
- elasticsearch: 5.4.0
- logstash: 5.0
- kibana: 5.0
- docker(swarm): 17.03
为什么要用docker?
ELK如果直接在vm上安装的话,需要去考虑一些服务的编排以及配置一致性问题。后期运维的时候服务的升级和回滚都会比较麻烦。使用docker来搭建的话,就可以使用swarm这样的集群管理工具来对整个集群进行管理,会带来很多有利的特性。不过使用docker的时候会有一些其他需要解决的问题,后面会做说明。
环境搭建
目前ELK集群在AWS上搭建,AWS上有支持docker的AMI,但是此处为了和其他的子系统保持一致,使用redhat的AMI,为了使用docker,需要在每个vm上安装docker, 并组建docker swarm集群。具体的步骤如下,为了更自动地完成这部分工作,可以通过ansible等vm 配置工具来完成。这里只列出来需要执行的命令:
安装docker
添加yum 仓库并更新:
sudo yum-config-manager \
--add-repo \
https://download.docker.com/linux/centos/docker-ce.repo
sudo yum makecache fast
安装并启动docker:
sudo yum -y install docker-ce
sudo systemctl enable docker
sudo systemctl start docker
赋予aws用户使用docker的权限:
sudo usermod -aG docker ec2-user
在所有的elk集群的vm上执行上面的命令,可以通过如下命令验证docker是否已经安装好:
[ec2-user@ip-10-0-2-26 ~]$ docker --version
Docker version 17.03.1-ce, build c6d412e
另外,为了能在vm上运行elasticsearch,需要在每个vm上做如下修改:
sudo sysctl -w vm.max_map_count=262144
创建swarm cluster
在1.12之后的docker版本上,swarm已经集成在docker engine上了,也就是说只要安装了docker,就已经默认支持swarm了,不用再单独安装swarm,这样使用起来更方便。在新版本上的swarm被称做docker swarm mode. 后续我们用到的docker service 等命令都是只能使用在docker swarm mode下的,不支持standlone方式的swarm.
在任意一台vm上执行如下命令docker swarm init命令:
[ec2-user@ip-10-0-2-26 ~]$ docker swarm init
Swarm initialized: current node (809b4sngwmbnfdvxntiplw95x) is now a manager.
To add a worker to this swarm, run the following command:
docker swarm join \
--token SWMTKN-1-02jj7a820h9bxu9sw7jigku9j4hfmryb2md5oe1wugck7rkw8u-8mdgjxvuouq04ycz0jbeqiqc8 \
10.0.2.191:2377
To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions.
上面的命令创建了一个docker swarm cluster,并且该vm作为docker swarm manage的角色,每一个集群可以有一个或者多个manage,manage作为cluster的管理者,可以在上面执行很多管理操作。
将elk集群的其他vm加入swarm cluster,在其余的vm上执行如下命令:
docker swarm join \
--token SWMTKN-1-02jj7a820h9bxu9sw7jigku9j4hfmryb2md5oe1wugck7rkw8u-8mdgjxvuouq04ycz0jbeqiqc8 \
10.0.2.191:2377
创建好的集群,可以通过docker node ls来查看:
[ec2-user@ip-10-0-2-191 ~]$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
4t3tawqaq4v06fj2atdm36ofy * ip-10-0-2-191.ec2.internal Ready Active Leader
f0y7u7vo7oi9x0gp7cacf8dql ip-10-0-2-15.ec2.internal Ready Active
lrdl37bndm3tfu9my9o4x87tr ip-10-0-2-81.ec2.internal Ready Active
nev2gglqzv2izaeq5bzytnz28 ip-10-0-2-42.ec2.internal Ready Active Reachable
x5d5xevqjr94h75tgbo9a4eh5 ip-10-0-2-26.ec2.internal Ready Active
如上是一个5个node的swarm cluster,其中有3个worker,2个manager,其中一个manager作为leader,另外一个作为备份leader,这样,如果一个manager出现异常,另外一个manager可以作为leader继续工作,不会导致集群的崩溃。
部署elk集群
这里先将elk集群搭建起来,具体的技术细节和一些关键特性会在后面再做介绍。
创建docker network
这里不适用缺省的bridge网络,我们将elk集群放在一个隔离的网络里面,在swarm manager节点上通过docker命令新建一个网络:
docker network create --driver overlay --subnet 192.168.8.0/20 elknet
部署elasticsearch
1.创建本地目录用于存储数据
[ec2-user@ip-10-0-2-191 ~]$ mkdir es
[ec2-user@ip-10-0-2-191 ~]$ chmod 777 es
elasticsearch为了保存索引数据必须要永久化存储数据,docker本身并不支持数据的永久化存储,后续会对这部分做详细说明,这里的es目录属于用户ec2-user,而运行elasticsearch的是用户elasticsearch,因此需要将es的权限改成777或者666.
2.部署elasticsearch服务
docker service create --name es --network=elknet \
--mode global \
--mount type=bind,src=$PWD/es,dst=/usr/share/elasticsearch/data \
--env SERVICE_NAME=es \
--publish 9200:9200 \
--env discovery.zen.minimum_master_nodes=3 \
--env path.data=/usr/share/elasticsearch/data \
fangcha/swarm-elasticsearch
3.查看服务是否部署成功:
[ec2-user@ip-10-0-2-191 ~]$ docker service ls
ID NAME MODE REPLICAS IMAGE
8f8n4jo7lwkq es global 5/5 fangcha/swarm-elasticsearch:latest
[ec2-user@ip-10-0-2-191 ~]$ docker service ps es
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
3smu1yflqg4s es.f0y7u7vo7oi9x0gp7cacf8dql fangcha/swarm-elasticsearch:latest ip-10-0-2-15.ec2.internal Running Running about an hour ago
ob3ihbf3ot7d es.4t3tawqaq4v06fj2atdm36ofy fangcha/swarm-elasticsearch:latest ip-10-0-2-191.ec2.internal Running Running about an hour ago
p6jpwgh9bhjg es.x5d5xevqjr94h75tgbo9a4eh5 fangcha/swarm-elasticsearch:latest ip-10-0-2-26.ec2.internal Running Running about an hour ago
r2m39v5mm6fz es.x5d5xevqjr94h75tgbo9a4eh5 fangcha/swarm-elasticsearch:latest ip-10-0-2-42.ec2.internal Running Running about an hour ago
17e96lcjvgpm es.lrdl37bndm3tfu9my9o4x87tr fangcha/swarm-elasticsearch:latest ip-10-0-2-81.ec2.internal Running Running about an hour ago
从上面可以看出,我们在部署了5个elasticsearch的节点,服务已经部署成功了,服务的名称是es,后续可以通过这个名称来做负载均衡。现在可以通过curl命令验证elasticsearch节点的工作状态是否正常:
[ec2-user@ip-10-0-2-191 ~]$ curl 10.0.2.191:9200/_cat/nodes?v
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
192.168.0.8 10 91 0 0.00 0.02 0.05 mdi * 192.168.0.8
192.168.0.3 6 97 0 0.00 0.01 0.05 mdi - 192.168.0.3
192.168.0.4 6 97 0 0.02 0.03 0.05 mdi - 192.168.0.4
192.168.0.7 8 92 0 0.00 0.01 0.05 mdi - 192.168.0.7
192.168.0.5 11 93 0 0.05 0.04 0.05 mdi - 192.168.0.5
elasticsearch集群已经可以正常工作了。
部署logstash
在swarm manage节点上执行如下命令:
docker service create --name logshipper --network=elknet \
--replicas 2 \
--publish 514:10514 \
logstash -e 'input { syslog { port => 10514 } } output { elasticsearch { hosts => "es:9200" index => "syslog-msg"} }'
部署kibana
在swarm manage节点上执行如下命令:
docker service create --name kibana --network=elknet \
--replicas 1 \
--publish 5601:5601 \
--env ELASTICSEARCH_URL=http://es:9200 \
kibana
通过以上命令,一个有2个logstash节点、5个elasticsearch节点、1个kibana节点的elk集群就已经搭建成功了。查看整个服务的状态:
[ec2-user@ip-10-0-2-191 ~]$ docker service ls
ID NAME MODE REPLICAS IMAGE
8f8n4jo7lwkq es global 5/5 fangcha/swarm-elasticsearch:latest
n0i181kvsj3k kibana replicated 1/1 kibana:latest
s81iijgbv5gh logshipper replicated 2/2 logstash:latest
测试elk集群
以上搭建的集群是是通过514端口接收syslog消息,将接收到的消息发送给elasticsearch之后,kibana通过5601端口将syslog消息展示给用户。
在任意一台可以访问集群的计算机上执行如下命令:
root@zhbo-OptiPlex-9020:/home/zhbo# yes "test" | nc 52.176.215.132 514
52.176.215.132是集群中一台vm的public ip。我们可以通过elasticseach的api查看是否建立syslog-msg的索引:
[ec2-user@ip-10-0-2-191 ~]$ curl 10.0.2.191:9200/_cat/shards
.kibana 0 p STARTED 2 7.1kb 192.168.0.3 192.168.0.3
.kibana 0 r STARTED 2 7.1kb 192.168.0.4 192.168.0.4
syslog-msg 3 p STARTED 12516 595.2kb 192.168.0.3 192.168.0.3
syslog-msg 3 r STARTED 12516 595.2kb 192.168.0.4 192.168.0.4
syslog-msg 2 r STARTED 12503 597.7kb 192.168.0.5 192.168.0.5
syslog-msg 2 p STARTED 12503 597.7kb 192.168.0.7 192.168.0.7
syslog-msg 1 p STARTED 12370 591.6kb 192.168.0.5 192.168.0.5
syslog-msg 1 r STARTED 12370 591.6kb 192.168.0.7 192.168.0.7
syslog-msg 4 p STARTED 12445 586.3kb 192.168.0.8 192.168.0.8
syslog-msg 4 r STARTED 12445 586.3kb 192.168.0.4 192.168.0.4
syslog-msg 0 r STARTED 12395 589.6kb 192.168.0.3 192.168.0.3
syslog-msg 0 p STARTED 12395 589.6kb 192.168.0.8 192.168.0.8
从上面可以看出已经收到测试消息,并分成5片分别存储在不同的节点上。elk集群搭建成功。
关键特性
负载均衡
docker swarm mode 内置了负载均衡器,所以此处不需要再通过haproxy或者nginx做负载均衡。docker swarm mode的负载均衡是通过routing mesh来实现的。这里引用docker官方文档中的一个图做说明:

Docker Engine swarm mode makes it easy to publish ports for services to make them available to resources outside the swarm. All nodes participate in an ingress routing mesh. The routing mesh enables each node in the swarm to accept connections on published ports for any service running in the swarm, even if there’s no task running on the node. The routing mesh routes all incoming requests to published ports on available nodes to an active container.
In order to use the ingress network in the swarm, you need to have the following ports open between the swarm nodes before you enable swarm mode:
- Port 7946 TCP/UDP for container network discovery.
- Port 4789 UDP for the container ingress network.
You must also open the published port between the swarm nodes and any external resources, such as an external load balancer, that require access to the port.
如上图所示,swarm集群作为一个整体对外提供服务,对集群中任何一个节点的访问,都会根据相应的端口信息,路由到可用的容器上执行相关操作。如elk集群中logstash有2个节点,对外监听514端口,则访问swarm cluster中的任意一台vm的514端口,都会被路由到2个可用的logstash节点中的一个。达到负载分担的效果。
弹性伸缩
docker swarm对服务的弹性伸缩支持得很好,尤其是对于无状态的服务。只需要一条命令就可以支持弹性伸缩了。如:将logstash的服务有2个节点扩展到3个几点,在swarm manage节点上执行如下命令:
[ec2-user@ip-10-0-2-191 ~]$ docker service scale logshipper=3
logshipper scaled to 3
[ec2-user@ip-10-0-2-191 ~]$ docker service ls
ID NAME MODE REPLICAS IMAGE
8f8n4jo7lwkq es global 5/5 fangcha/swarm-elasticsearch:latest
n0i181kvsj3k kibana replicated 1/1 kibana:latest
s81iijgbv5gh logshipper replicated 3/3 logstash:latest
[ec2-user@ip-10-0-2-191 ~]$ docker service ps logshipper
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
xix4cretis74 logshipper.1 logstash:latest ip-10-0-2-81.ec2.internal Running Running 18 hours ago
d09u1h44exuv logshipper.2 logstash:latest ip-10-0-2-42.ec2.internal Running Running 18 hours ago
e5gl09fymz9u logshipper.3 logstash:latest ip-10-0-2-26.ec2.internal Running Running 30 seconds ago
将logstash服务的节点数缩减为2个,也是很容易的:
[ec2-user@ip-10-0-2-191 ~]$ docker service scale logshipper=2
logshipper scaled to 2
[ec2-user@ip-10-0-2-191 ~]$ docker service ps logshipper
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
xix4cretis74 logshipper.1 logstash:latest ip-10-0-2-81.ec2.internal Running Running 18 hours ago
d09u1h44exuv logshipper.2 logstash:latest ip-10-0-2-42.ec2.internal Running Running 18 hours ago
注意:这里进行服务扩展时,服务的参数会在新建的节点上执行,所以在创建服务的时候需要根据服务的特点合理的规划服务和服务的参数,最好是使用节点无关的参数。
服务发现
这里主要分为两部分来说明:服务间发现和服务内发现。在elk集群中都用到了这两个功能,logstash和es,kibana和es之间的交互要用到服务间发现。es本身就是一个集群,内部不同节点间是服务内发现。
服务间发现
docker swarm的架构决定了它非常适合做服务间发现,docker本身内置了dns的服务,可以将服务名称解析为对应的ip地址。
在上面部署elk集群的时候,logstash为了将日志发送给es,需要知道es的集群的访问地址,当时部署时候的命令如下:
docker service create --name logshipper --network=elknet \
--replicas 2 \
--publish 514:10514 \
logstash -e 'input { syslog { port => 10514 } } output { elasticsearch { hosts => "es:9200" index => "syslog-msg"} }'
直接用es:9200就可以指代es集群的地址了,这里es就是es集群的服务名称。事实上在elknet内部,通过dig tasks.es +short就可以找到所有运行es服务的node的ip地址。所以,对于服务间发现,docker swarm天然支持得很好,不需要做额外的工作,每个服务都可以通过服务名称进行访问。
但是docker swarm mode对于服务内发现支持得并不好,这是由于docker swarm本身的特点决定的。docker swarm将所有的集群作为一个整体来看,所有的node除了manage和worker的区分之外,没有其他的区分了。这种特性在不需要关心节点的状态的情况下,非常有用,如logstash就很适应这种情况。但是对于某些需要关注不同node状态的服务,或者说启动参数和节点有关的服务,这时候就有一些问题,比如elasticsearch。
服务内发现
elasticsearch节点分为master节点、data节点、ingress节点、tribe节点。正常es集群的建立方式是先启动一个或者多个master节点,通过network.publish_host(transport.publish_host)配置集群内通信的ip地址。然后其他的节点通过discovery.zen.ping.unicast.hosts配置集群的host(一般是master节点的network.publish_host)来加入es集群。
如果简单地通过docker service来创建es服务,则无法为master节点(master节点为了组成集群,也需要互相知道彼此的地址)和data节点分别配置不同的而且有关联的参数。有几种方式解决这个问题,这里结合docker swarm内置的dns解析功能,通过脚本的方式解决es之间的服务发现的问题。
这里需要新建一个elasticsearch的docker image,Dockerfile和全部的脚本可以参考github上如下路径的实现:
https://github.com/riverbaby/docker-swarm-elasticsearch
通过上述的Dockerfile生成的镜像可以在docker hub上的如下位置找到:
https://hub.docker.com/r/fangcha/swarm-elasticsearch/
使用这里的镜像就可以通过docker swarm mode建立es的集群了。对具体的实现细节感兴趣可以参考上面的两个链接。
服务回滚和升级
服务的回滚和升级可以通过docker service update来实现。docker swarm支持很多服务和升级的配置,缺省情况下,在服务回滚和升级的时候,会逐个将服务的节点shutdown,然后更换为新的服务节点,直到所有的节点全部替换完毕。
对于该功能的详细实现,可以查看如下链接:
https://docs.docker.com/engine/swarm/swarm-tutorial/rolling-update/
永久存储
docker本身是不支持永久存储的,也就是说当前正在运行的容器如果重启之后,先前的数据会丢失。对于单个docker实例,可以通过-v参数将host的存储路径映射到docker容器中,这样,需要永久化存储的数据就会被存储到host中。
elk集群中es的数据是需要永久存储的,有两个思路:
其一
使用公共的存储路径,将所有的节点的数据存储到这个公共的存储路径这里。这样再创建service的时候,只需要制定一个公共的volume就可以了。docker支持创建和使用这样的路径。这里以aws的EBS存储为例,具体的命令和步骤如下:
1.安装rexray plugin,在所有的vm上执行如下命令:
docker plugin install rexray/ebs \
REXRAY_PREEMPT=true \
EBS_ACCESSKEY=×× \
EBS_SECRETKEY=××
其中EBS_ACCESSKEY和EBS_SECRETKEY是AWS的访问凭据。
2. 创建docker volume,在docker manage上执行如下命令:
docker volume create -d rexray/ebs --name esdisk --opt=size=50
3.可以通过docker volume查看创建的volume卷,这里创建的volume,也可以通过aws的网页页面的volume栏查看。
4.创建服务,指定数据存储的位置为esdisk volume:
docker service create --name esmaster --network=elknet \
--replicas 5 \
--mount type=volume,source=esdisk,target=/usr/share/elasticsearch/data,volume-driver=rexray/ebs \
--env SERVICE_NAME=esmaster \
--env discovery.zen.minimum_master_nodes=3 \
--env path.data=/usr/share/elasticsearch/data \
fangcha/swarm-elasticsearch
如上,就可以通过公用的存储位置来存储整个集群的数据了。但是这种方式存储的时候,需要注意master节点和data节点的数据一致性的问题。目前在使用的时候还存在一些问题,es的官网上也不建议通过共享数据路径的方式存储es的数据,本身es集群就是通过在不同的位置存储数据的备份来达到数据的高可靠性的,如果共享了同一个位置,后续该volume发生问题的时候则所有数据都会出异常。这个后续需要再研究看看如何实现。
其二
在每个节点有独立的存储路径来存储数据。这样是符合elasticsearch的要求的,但是对于docker swarm来说这样的实现并不好,因为需要考虑每个node的存储路径,而且swarm并不能保证一个服务重启之后还在原来的vm上。一个解决方式是通过global mode来启动服务:
- global mode的服务会在每个vm上启动服务
- es服务通过bind的mount方式在每个vm上mount一个local路径,local路径需要提起创建好,local路径是host的路径,以后的数据都存储在host上了。
- 服务重启的时候可以直接从每个节点上恢复出来数据。
- 后续如果将es的节点功能独立出来(如单独的master节点、data节点等),则可以通过lable的方式将vm打上标签,然后在启动服务的时候分别启动master服务,data服务,通过filter指定服务在指定label的节点上启动。只要保证不同功能的节点不共用相同的路径即可。
目前的采取了“其二”的实现方式。
跨数据中心部署和访问
在实际的使用过程中,有可能数据被存储在不同的数据中心中,这时候需要能跨数据中心访问数据。es提供了相关的特性支持这种跨数据中心的操作。此时的部署架构图如下:
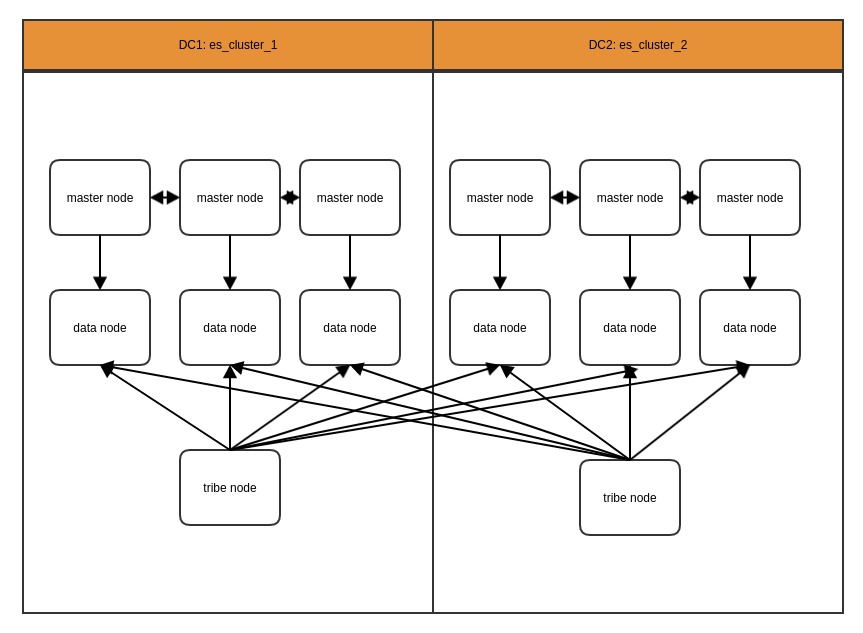
通过在DC边缘部署tribe节点,tribe节点绑定到不同DC的es cluster中,则可以通过tribe节点访问不同的数据中心的数据。
