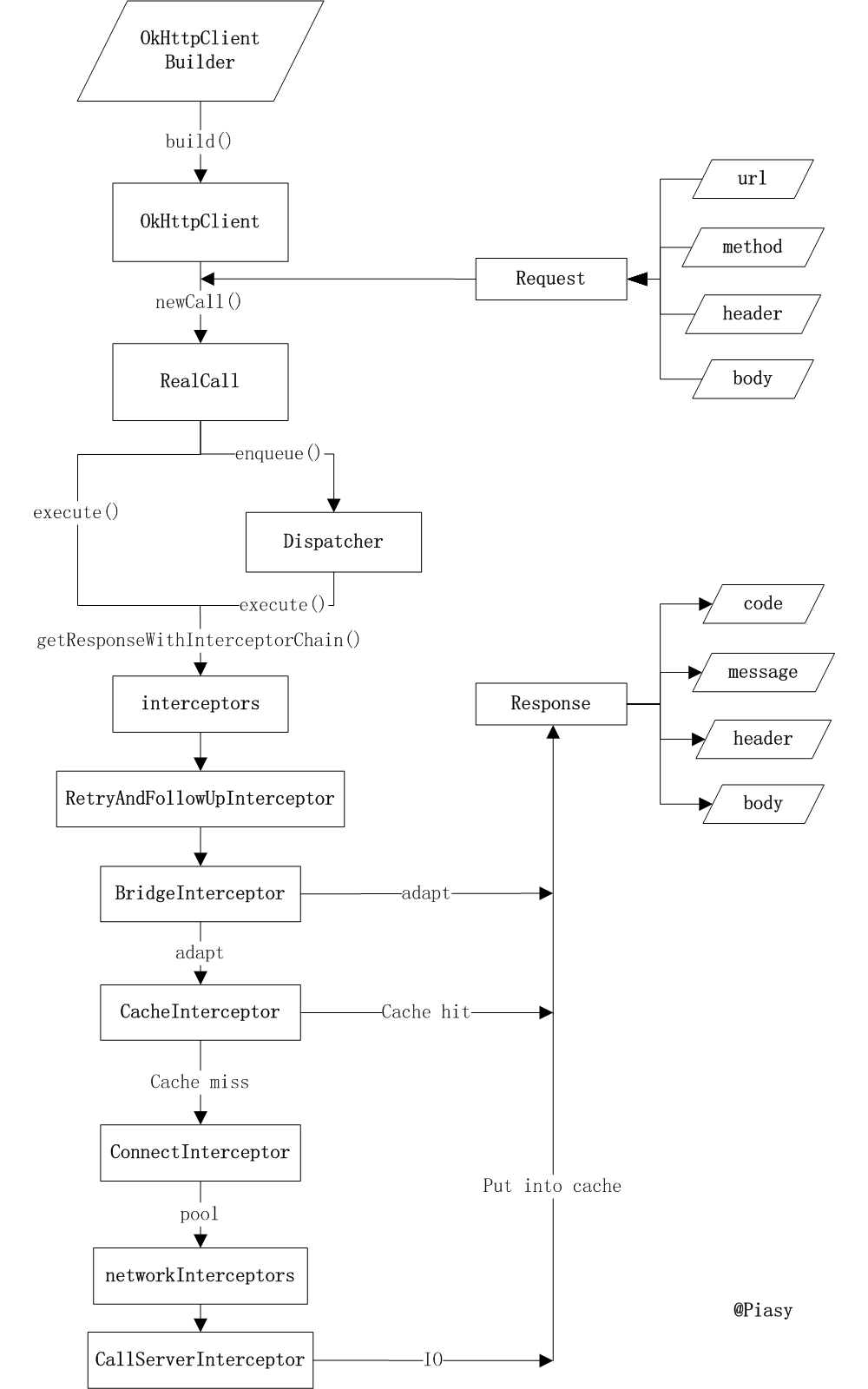
OkHttp解析系列
OkHttp解析(一)从用法看清原理
OkHttp解析(二)网络连接
OkHttp解析(三)关于Okio
认识使用
一系列是对OkHttp的源码解析,就从大家使用方法入手
常用方法
OkHttpClient okHttpClient = new OkHttpClient.Builder().connectTimeout(10, TimeUnit.SECONDS) .cookieJar(new CookieJar() {
@Override
public void saveFromResponse(HttpUrl url, List<Cookie> cookies)
{
//...
}
@Override
public List<Cookie> loadForRequest(HttpUrl url) {
//...
return null;
}
}).build();
Request request = new Request.Builder().url("www.baidu.com").build();
Call call = okHttpClient.newCall(request);
//异步
call.enqueue(new Callback() {
@Override
public void onFailure(Call call, IOException e) {
}
@Override
public void onResponse(Call call, Response response) throws IOException {
}
});
//同步
try {
Response response = call.execute();
} catch (IOException e) {
e.printStackTrace();
}
可以看到常用的用法,是创建OKHttpClient对象,构建请求Request,请求调用Call,而Call里面对应有同步异步两种方法,同步下则要在线程中去进行。这就是大家常用的方法,我们先来看看OkHttpClient
OkHttpClient
我们先看注释说明
/**
* Factory for {@linkplain Call calls}, which can be used to send HTTP requests and read their responses.
OkHttpClient算是执行调用请求Call的工厂,这个工厂将会被用来发送Http请求和读取他们的返回
*
* ...
*
* <p>OkHttp performs best when you create a single {@code OkHttpClient} instance and reuse it for all of your HTTP calls. This is because each client holds its own connection pool and thread pools. Reusing connections and threads reduces latency and saves memory. Conversely, creating a client for each request wastes resources on idle pools.
这里强调OkHttp的使用最好创建一个单例OkHttpClient实例,并且重复使用。这是因为每一个Client都有自己的一个连接池connection pool和线程池thread pools。重用这些连接池和线程池可以减少延迟和节约内存。
*
...
*
* <p>Or use {@code new OkHttpClient.Builder()} to create a shared instance with custom settings:
* <pre> {@code
* 创建实例说明,可以看到是通过Builder模式创建的
* // The singleton HTTP client.
* public final OkHttpClient client = new OkHttpClient.Builder()
* .addInterceptor(new HttpLoggingInterceptor())
* .cache(new Cache(cacheDir, cacheSize))
* .build();
* }</pre>
*
* <h3>Customize your client with newBuilder()</h3>
*
* 可以调用newBuilder方法来定制自己的client,调用后创建的client会保存上次的连接池和线程池以及之前一些配置
* <p>You can customize a shared OkHttpClient instance with {@link #newBuilder()}. This builds a client that shares the same connection pool, thread pools, and configuration. Use the builder methods to configure the derived client for a specific purpose.
*
* <p>This example shows a call with a short 500 millisecond timeout: <pre> {@code
*
* OkHttpClient eagerClient = client.newBuilder()
* .readTimeout(500, TimeUnit.MILLISECONDS)
* .build();
* Response response = eagerClient.newCall(request).execute();
* }</pre>
*
* ...
*/
OkHttpClient算是执行调用请求Call的工厂,这个工厂将会被用来发送Http请求和读取他们的返回这里强调OkHttp的使用最好创建一个单例OkHttpClient实例,并且重复使用。这是因为每一个Client都有自己的一个连接池connection pool和线程池thread pools。重用这些连接池和线程池可以减少延迟和节约内存。
我们看下里面的源码,由于使用Builder,看OkHttpClient的也就相当于看Builder
public static final class Builder {
Dispatcher dispatcher; //调度器,里面包含了线程池和三个队列(readyAsyncCalls:保存等待执行的异步请求
Proxy proxy; //代理类,默认有三种代理模式DIRECT(直连),HTTP(http代理),SOCKS(socks代理),这三种模式,折腾过科学上网的或多或少都了解一点吧。
List<Protocol> protocols; //协议集合,协议类,用来表示使用的协议版本,比如`http/1.0,`http/1.1,`spdy/3.1,`h2等
List<ConnectionSpec> connectionSpecs; //连接规范,用于配置Socket连接层。对于HTTPS,还能配置安全传输层协议(TLS)版本和密码套件
final List<Interceptor> interceptors = new ArrayList<>(); //拦截器,用来监听请求
final List<Interceptor> networkInterceptors = new ArrayList<>();
ProxySelector proxySelector; //代理选择类,默认不使用代理,即使用直连方式,当然,我们可以自定义配置,以指定URI使用某种代理,类似代理软件的PAC功能。
CookieJar cookieJar; //Cookie的保存获取
Cache cache; //缓存类,内部使用了DiskLruCache来进行管理缓存,匹配缓存的机制不仅仅是根据url,而且会根据请求方法和请求头来验证是否可以响应缓存。此外,仅支持GET请求的缓存。
InternalCache internalCache; //内置缓存
SocketFactory socketFactory; //Socket的抽象创建工厂,通过`createSocket来创建Socket
。
SSLSocketFactory sslSocketFactory; //安全套接层工厂,HTTPS相关,用于创建SSLSocket。一般配置HTTPS证书信任问题都需要从这里着手。对于不受信任的证书一般会提示javax.net.ssl.SSLHandshakeException异常。
CertificateChainCleaner certificateChainCleaner; //证书链清洁器,HTTPS相关,用于从[Java]的TLS API构建的原始数组中统计有效的证书链,然后清除跟TLS握手不相关的证书,提取可信任的证书以便可以受益于证书锁机制。
HostnameVerifier hostnameVerifier; //主机名验证器,与HTTPS中的SSL相关,当握手时如果URL的主机名不是可识别的主机,就会要求进行主机名验证
CertificatePinner certificatePinner; // 证书锁,HTTPS相关,用于约束哪些证书可以被信任,可以防止一些已知或未知的中间证书机构带来的攻击行为。如果所有证书都不被信任将抛出SSLPeerUnverifiedException异常。
Authenticator proxyAuthenticator; //身份认证器,当连接提示未授权时,可以通过重新设置请求头来响应一个新的Request。状态码401表示远程服务器请求授权,407表示代理服务器请求授权。该认证器在需要时会被RetryAndFollowUpInterceptor触发。
Authenticator authenticator;
ConnectionPool connectionPool; //连接池
Dns dns;
boolean followSslRedirects; //是否遵循SSL重定向
boolean followRedirects; //是否重定向
boolean retryOnConnectionFailure; //失败是否重新连接
int connectTimeout; //连接超时
int readTimeout; //读取超时
int writeTimeout; //写入超时
...
}
注释中说明的很清楚了
可以看到在OkHttpClient这里就设置了这么多的字段,常用的读写时间,延迟请求,缓存都在这里设置了。
看下构造器的赋值
public Builder() {
dispatcher = new Dispatcher();
protocols = DEFAULT_PROTOCOLS; //默认支持的协议
connectionSpecs = DEFAULT_CONNECTION_SPECS; //默认的连接规范
proxySelector = ProxySelector.getDefault(); //默认的代理选择器,直连
cookieJar = CookieJar.NO_COOKIES; //默认不进行管理Cookie
socketFactory = SocketFactory.getDefault();
hostnameVerifier = OkHostnameVerifier.INSTANCE; //主机验证
certificatePinner = CertificatePinner.DEFAULT; //证书锁,默认不开启
proxyAuthenticator = Authenticator.NONE; //默认不进行授权
authenticator = Authenticator.NONE;
connectionPool = new ConnectionPool(); //连接池
dns = Dns.SYSTEM;
followSslRedirects = true;
followRedirects = true;
retryOnConnectionFailure = true;
//超时时间
connectTimeout = 10_000;
readTimeout = 10_000;
writeTimeout = 10_000;
}
Dispatcher
它是一个异步请求执行政策,当我们用OkHttpClient.newCall(request)进行execute/enenqueue时,实际是将请求Call放到了Dispatcher中,okhttp使用Dispatcher进行线程分发,它有两种方法,一个是普通的同步单线程;另一种是使用了队列进行并发任务的分发(Dispatch)与回调。另外,在Dispatcher中每一个请求都是使用 ExecutorService 来执行的。
public final class Dispatcher {
private int maxRequests = 64; //最大并发数为64,同时请求
private int maxRequestsPerHost = 5; //每个主机的最大请求数为5
private Runnable idleCallback; //闲置接口
/** Executes calls. Created lazily. */
private ExecutorService executorService; //线程池
//缓存好的异步调用,都是放在队列里保存
private final Deque<AsyncCall> readyAsyncCalls = new ArrayDeque<>();
//运行中的异步调用,都是放在队列里保存
private final Deque<AsyncCall> runningAsyncCalls = new ArrayDeque<>();
//运行中的同步调用,都是放在队列里保存
private final Deque<RealCall> runningSyncCalls = new ArrayDeque<>();
...
}
前面说到,当我们用OkHttpClient.newCall(request)进行execute/enqueue时,实际是将请求Call放到了Dispatcher中。
我们先看回之前的用法
Call call = okHttpClient.newCall(request);
//异步
call.enqueue(new Callback() {
@Override
public void onFailure(Call call, IOException e) {
}
@Override
public void onResponse(Call call, Response response) throws IOException {
}
});
//同步
try {
Response response = call.execute();
} catch (IOException e) {
e.printStackTrace();
}
通过调用okHttpClient.newCall将请求Request构造成Call,进行发起请求。
@Override public Call newCall(Request request) {
return new RealCall(this, request);
}
newCall这里则是创建了一个RealCall对象
Call
首先对于Call,大家比较熟悉,它是一个接口,定义了各种Http连接请求的方法
public interface Call {
Request request();
...
Response execute() throws IOException;
void enqueue(Callback responseCallback);
void cancel();
boolean isExecuted();
boolean isCanceled();
interface Factory {
Call newCall(Request request);
}
}
可以通过request()方法获取自己的请求体,调用enqueue发起异步请求,调用execute发起同步请求
RealCall
RealCall则是Call的实现类
final class RealCall implements Call {
private final OkHttpClient client;
private final RetryAndFollowUpInterceptor retryAndFollowUpInterceptor;
// Guarded by this.
private boolean executed;
/** The application's original request unadulterated by redirects or auth headers. */
Request originalRequest;
protected RealCall(OkHttpClient client, Request originalRequest) {
this.client = client;
this.originalRequest = originalRequest;
this.retryAndFollowUpInterceptor = new RetryAndFollowUpInterceptor(client);
}
@Override public Request request() {
return originalRequest;
}
@Override public Response execute() throws IOException {
synchronized (this) {
if (executed) throw new IllegalStateException("Already Executed");
executed = true;
}
try {
client.dispatcher().executed(this);
Response result = getResponseWithInterceptorChain();
if (result == null) throw new IOException("Canceled");
return result;
} finally {
client.dispatcher().finished(this);
}
}
@Override public void enqueue(Callback responseCallback) {
synchronized (this) {
if (executed) throw new IllegalStateException("Already Executed");
executed = true;
}
client.dispatcher().enqueue(new AsyncCall(responseCallback));
}
...
}
RealCall中实现了Execute和enqueue等方法。而在RealCall的execute和enqueue方法中都调用到了dispatcher.enqueue/execute。
我们先看下同步方法RealCall.execute
@Override public Response execute() throws IOException {
synchronized (this) {
if (executed) throw new IllegalStateException("Already Executed");
executed = true;
}
try {
client.dispatcher().executed(this);
Response result = getResponseWithInterceptorChain();
if (result == null) throw new IOException("Canceled");
return result;
} finally {
client.dispatcher().finished(this);
}
}
同步方法中做了4件事
- 检查这个 call 是否已经被执行了,每个 call 只能被执行一次,如果想要一个完全一样的 call,可以利用
call#clone方法进行克隆。 - 利用
client.dispatcher().executed(this)来进行实际执行,dispatcher是刚才看到的OkHttpClient.Builder的成员之一,它的文档说自己是异步 HTTP 请求的执行策略,现在看来,同步请求它也有掺和。 - 调用
getResponseWithInterceptorChain()函数获取 HTTP 返回结果,从函数名可以看出,这一步还会进行一系列“拦截”操作。 - 最后还要通知
dispatcher自己已经执行完毕。
dispatcher 这里我们不过度关注,在同步执行的流程中,涉及到 dispatcher 的内容只不过是告知它我们的执行状态,比如开始执行了(调用 executed),比如执行完毕了(调用 finished),在异步执行流程中它会有更多的参与。
这里同步请求,只是把当前请求添加到队列而已
synchronized void executed(RealCall call) {
runningSyncCalls.add(call);
}
真正发出网络请求,解析返回结果的,还是 getResponseWithInterceptorChain,这个下面说,最后再调用了dispatch.finish方法
private <T> void finished(Deque<T> calls, T call, boolean promoteCalls) {
int runningCallsCount;
Runnable idleCallback;
synchronized (this) {
if (!calls.remove(call)) throw new AssertionError("Call wasn't in-flight!");
if (promoteCalls) promoteCalls();
runningCallsCount = runningCallsCount();
idleCallback = this.idleCallback;
}
if (runningCallsCount == 0 && idleCallback != null) {
idleCallback.run();
}
}
private void promoteCalls() {
if (runningAsyncCalls.size() >= maxRequests) return; // Already running max capacity.
if (readyAsyncCalls.isEmpty()) return; // No ready calls to promote.
for (Iterator<AsyncCall> i = readyAsyncCalls.iterator(); i.hasNext(); ) {
AsyncCall call = i.next();
if (runningCallsForHost(call) < maxRequestsPerHost) {
i.remove();
runningAsyncCalls.add(call);
executorService().execute(call);
}
if (runningAsyncCalls.size() >= maxRequests) return; // Reached max capacity.
}
}
在finish方法中,会把当前请求从running队列中移除,然后把缓存队列的请求添加到running队列。
接下来看下异步请求
RealCall.enqueue
@Override public void enqueue(Callback responseCallback) {
synchronized (this) {
if (executed) throw new IllegalStateException("Already Executed");
executed = true;
}
client.dispatcher().enqueue(new AsyncCall(responseCallback));
}
先判断当前Call是否在执行,再调用dispatch.enqueue方法
synchronized void enqueue(AsyncCall call) {
if (runningAsyncCalls.size() < maxRequests && runningCallsForHost(call) < maxRequestsPerHost) {
runningAsyncCalls.add(call);
executorService().execute(call);
} else {
readyAsyncCalls.add(call);
}
}
方法中,这里先有个判断,如果当前运行的异步请求队列长度小于最大请求数,也就是64,并且主机的请求数小于每个主机的请求数也就是5,则把当前请求添加到 运行队列,接着交给线程池ExecutorService处理,否则则放置到readAsyncCall进行缓存,等待执行。
可以看到同步与异步一点区别就是,异步的执行交给了线程池去操作。
我们看下OkHttp里面的线程池ExecutorService
public synchronized ExecutorService executorService() {
if (executorService == null) {
executorService = new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>(), Util.threadFactory("OkHttp Dispatcher", false));
}
return executorService;
}
这里则是通过ThreadPoolExecutor来创建线程池
参数说明如下:
int corePoolSize: 最小并发线程数,这里并发同时包括空闲与活动的线程,如果是0的话,空闲一段时间后所有线程将全部被销毁。
int maximumPoolSize: 最大线程数,当任务进来时可以扩充的线程最大值,当大于了这个值就会根据丢弃处理机制来处理
long keepAliveTime: 当线程数大于
corePoolSize时,多余的空闲线程的最大存活时间,类似于HTTP中的Keep-aliveTimeUnit unit: 时间单位,一般用秒
BlockingQueue<Runnable> workQueue: 工作队列,先进先出,可以看出并不像Picasso那样设置优先队列。
ThreadFactory threadFactory: 单个线程的工厂,可以打Log,设置
Daemon(即当JVM退出时,线程自动结束)等
可以看出,在Okhttp中,构建了一个阀值为[0, Integer.MAX_VALUE]的线程池,它不保留任何最小线程数,随时创建更多的线程数,当线程空闲时只能活60秒,它使用了一个不存储元素的阻塞工作队列,一个叫做"OkHttp Dispatcher"的线程工厂。
也就是说,在实际运行中,当收到10个并发请求时,线程池会创建十个线程,当工作完成后,线程池会在60s后相继关闭所有线程。
添加到线程池后就交给ThreadPoolExecutor去调用,最终则是调用到我们的请求AsyncCall的execute方法。回看上面的代码,异步请求中,我们传递了个Callback接口进来,而在RealCall的enqueue方法中,Callback回调接口被封装到AsyncCall中,而AsyncCall继承与NamedRunnable,而NamaedRunnable则实现了Runnable方法。
AsyncCall
AsyncCall继承于NamedRunnable,而NamaedRunnable则实现了Runnable方法
final class AsyncCall extends NamedRunnable {
private final Callback responseCallback;
private AsyncCall(Callback responseCallback) {
super("OkHttp %s", redactedUrl().toString());
this.responseCallback = responseCallback;
}
String host() {
return originalRequest.url().host();
}
Request request() {
return originalRequest;
}
RealCall get() {
return RealCall.this;
}
@Override protected void execute() {
boolean signalledCallback = false;
try {
Response response = getResponseWithInterceptorChain();
if (retryAndFollowUpInterceptor.isCanceled()) {
signalledCallback = true;
responseCallback.onFailure(RealCall.this, new IOException("Canceled"));
} else {
signalledCallback = true;
responseCallback.onResponse(RealCall.this, response);
}
} catch (IOException e) {
if (signalledCallback) {
// Do not signal the callback twice!
Platform.get().log(INFO, "Callback failure for " + toLoggableString(), e);
} else {
responseCallback.onFailure(RealCall.this, e);
}
} finally {
client.dispatcher().finished(this);
}
}
}
可以看到在它的构造器中,Callback就是我们设置的创建的,带有onFail和onResponse方法。
而线程池中最终调用到的则是我们的Runnable。
这里通过
Response response = getResponseWithInterceptorChain();
方法来进行连接访问,这里跟同步请求一样。最后根据返回值调用callback.onFailure/onResponse
我们关键还是看OkHttp如何连接返回的,我们看下这个方法
private Response getResponseWithInterceptorChain() throws IOException {
// Build a full stack of interceptors.
List<Interceptor> interceptors = new ArrayList<>();
interceptors.addAll(client.interceptors());
interceptors.add(retryAndFollowUpInterceptor);
interceptors.add(new BridgeInterceptor(client.cookieJar()));
interceptors.add(new CacheInterceptor(client.internalCache()));
interceptors.add(new ConnectInterceptor(client));
if (!retryAndFollowUpInterceptor.isForWebSocket()) {
interceptors.addAll(client.networkInterceptors());
}
interceptors.add(new CallServerInterceptor(
retryAndFollowUpInterceptor.isForWebSocket()));
Interceptor.Chain chain = new RealInterceptorChain(
interceptors, null, null, null, 0, originalRequest);
return chain.proceed(originalRequest);
}
可以看到这里全都是关于Interceptor拦截器的使用
Interceptor
/**
* Observes, modifies, and potentially short-circuits requests going out and the corresponding
* responses coming back in. Typically interceptors add, remove, or transform headers on the request
* or response.
*/
public interface Interceptor {
Response intercept(Chain chain) throws IOException;
interface Chain {
Request request();
Response proceed(Request request) throws IOException;
Connection connection();
}
}
Interceptor 是 OkHttp 最核心的一个东西,不要误以为它只负责拦截请求进行一些额外的处理(例如 cookie),实际上它把实际的网络请求、缓存、透明压缩等功能都统一了起来,每一个功能都只是一个 Interceptor,它们再连接成一个 Interceptor.Chain,环环相扣,最终圆满完成一次网络请求。
从 getResponseWithInterceptorChain 函数我们可以看到,Interceptor.Chain 的分布依次是:
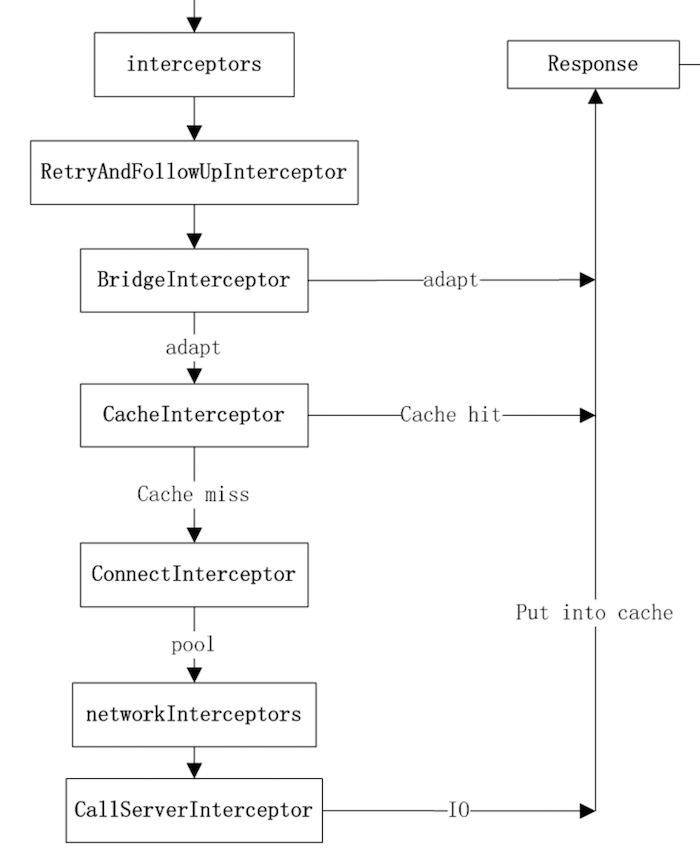
在配置
OkHttpClient时设置的interceptors;负责失败重试以及重定向的
RetryAndFollowUpInterceptor;负责把用户构造的请求转换为发送到服务器的请求、把服务器返回的响应转换为用户友好的响应的
BridgeInterceptor;负责读取缓存直接返回、更新缓存的
CacheInterceptor;负责和服务器建立连接的
ConnectInterceptor;配置
OkHttpClient时设置的networkInterceptors;负责向服务器发送请求数据、从服务器读取响应数据的
CallServerInterceptor。
[责任链模式]在这个 Interceptor 链条中得到了很好的实践
在这里,位置决定了功能,最后一个 Interceptor 一定是负责和服务器实际通讯的,重定向、缓存等一定是在实际通讯之前的。
对于把 Request 变成 Response 这件事来说,每个 Interceptor 都可能完成这件事,所以我们循着链条让每个 Interceptor 自行决定能否完成任务以及怎么完成任务(自力更生或者交给下一个Interceptor)。这样一来,完成网络请求这件事就彻底从 RealCall 类中剥离了出来,简化了各自的责任和逻辑。
讲解其他拦截器前,先认识几个类
HttpStream
public interface HttpStream {
//超时渐渐
int DISCARD_STREAM_TIMEOUT_MILLIS = 100;
//返回一个output stream(如果RequestBody可以转为流)
Sink createRequestBody(Request request, long contentLength);
//写入请求头
void writeRequestHeaders(Request request) throws IOException;
// Flush the request
void finishRequest() throws IOException;
//读取请求头
Response.Builder readResponseHeaders() throws IOException;
//返回ResponseBody
ResponseBody openResponseBody(Response response) throws IOException;
void cancel();
}
可以看到HttpStream是一个接口,里面提供了很多类似的流操作,比如Sink。
而HttpStream对应的实现类有Http1xStream、Http2xStream。分别对应HTTP/1.1、HTTP/2和SPDY协议。我们可以大约知道,通过writeRequestHeaders开始写入请求头到服务器,createRequestBody用于获取写入流来写入请求体。readResponseHeaders用于读取响应头,openResponseBody用于打开一个响应体。关于相应实现的源码这里就不分析了,比较简单,无非就是读写操作。
StreamAllocation
流分配器,该类用于协调连接、流和请求三者之间的关系。通过调用newStream可以获取一个HttpStream实现
public HttpStream newStream(OkHttpClient client, boolean doExtensiveHealthChecks) {
//获取设置的超时时间
int connectTimeout = client.connectTimeoutMillis();
int readTimeout = client.readTimeoutMillis();
int writeTimeout = client.writeTimeoutMillis();
boolean connectionRetryEnabled = client.retryOnConnectionFailure();
try {
RealConnection resultConnection = findHealthyConnection(connectTimeout, readTimeout,
writeTimeout, connectionRetryEnabled, doExtensiveHealthChecks);
HttpStream resultStream;
if (resultConnection.framedConnection != null) {
resultStream = new Http2xStream(client, this, resultConnection.framedConnection);
} else {
resultConnection.socket().setSoTimeout(readTimeout);
resultConnection.source.timeout().timeout(readTimeout, MILLISECONDS);
resultConnection.sink.timeout().timeout(writeTimeout, MILLISECONDS);
resultStream = new Http1xStream(
client, this, resultConnection.source, resultConnection.sink);
}
synchronized (connectionPool) {
stream = resultStream;
return resultStream;
}
} catch (IOException e) {
throw new RouteException(e);
}
}
可以看到在newStream这里,通过RealConnection建立Socket连接,接着获取连接对应的流。
而在RealConnection的connectSocket方法中
private void connectSocket(int connectTimeout, int readTimeout) throws IOException {
Proxy proxy = route.proxy();
Address address = route.address();
rawSocket = proxy.type() == Proxy.Type.DIRECT || proxy.type() == Proxy.Type.HTTP
? address.socketFactory().createSocket()
: new Socket(proxy);
rawSocket.setSoTimeout(readTimeout);
try {
Platform.get().connectSocket(rawSocket, route.socketAddress(), connectTimeout);
} catch (ConnectException e) {
throw new ConnectException("Failed to connect to " + route.socketAddress());
}
source = Okio.buffer(Okio.source(rawSocket));
sink = Okio.buffer(Okio.sink(rawSocket));
}
可以看到Socket和Okio的连接使用
重试与重定向拦截器 RetryAndFollowUpInterceptor
用来实现重试和重定向功能
@Override public Response intercept(Chain chain) throws IOException {
Request request = chain.request();
streamAllocation = new StreamAllocation(
client.connectionPool(), createAddress(request.url()));
int followUpCount = 0;
Response priorResponse = null;
while (true) {
if (canceled) {
streamAllocation.release();
throw new IOException("Canceled");
}
Response response = null;
boolean releaseConnection = true;
try {
response = ((RealInterceptorChain) chain).proceed(request, streamAllocation, null, null);
releaseConnection = false;
} catch (RouteException e) {
// The attempt to connect via a route failed. The request will not have been sent.
if (!recover(e.getLastConnectException(), true, request)) throw e.getLastConnectException();
releaseConnection = false;
continue;
} catch (IOException e) {
// An attempt to communicate with a server failed. The request may have been sent.
if (!recover(e, false, request)) throw e;
releaseConnection = false;
continue;
} finally {
// We're throwing an unchecked exception. Release any resources.
if (releaseConnection) {
streamAllocation.streamFailed(null);
streamAllocation.release();
}
}
// Attach the prior response if it exists. Such responses never have a body.
if (priorResponse != null) {
response = response.newBuilder()
.priorResponse(priorResponse.newBuilder()
.body(null)
.build())
.build();
}
//获取重定向信息
Request followUp = followUpRequest(response);
if (followUp == null) {
if (!forWebSocket) {
streamAllocation.release();
}
return response;
}
closeQuietly(response.body());
if (++followUpCount > MAX_FOLLOW_UPS) {
streamAllocation.release();
throw new ProtocolException("Too many follow-up requests: " + followUpCount);
}
if (followUp.body() instanceof UnrepeatableRequestBody) {
throw new HttpRetryException("Cannot retry streamed HTTP body", response.code());
}
//判断是否需要重定向
if (!sameConnection(response, followUp.url())) {
streamAllocation.release();
streamAllocation = new StreamAllocation(
client.connectionPool(), createAddress(followUp.url()));
} else if (streamAllocation.stream() != null) {
throw new IllegalStateException("Closing the body of " + response
+ " didn't close its backing stream. Bad interceptor?");
}
request = followUp;
priorResponse = response;
}
}
RetryAndFollowUpInterceptor在intercept()中首先从client取得connection pool,用所请求的URL创建Address对象,并以此创建StreamAllocation对象。
Address描述某一个特定的服务器地址。StreamAllocation对象则用于分配一个到特定的服务器地址的流HttpStream,这个HttpStream可能是从connection pool中取得的之前没有释放的连接,也可能是重新分配的。RetryAndFollowUpInterceptor这里算是为后面的操作准备执行条件StreamAllocation。
随后利用Interceptor链中后面的Interceptor来获取网络响应。并检查是否为重定向响应。若不是就将响应返回,若是则做进一步处理。
对于重定向的响应,RetryAndFollowUpInterceptor.intercept()会利用响应的信息创建一个新的请求。并检查新请求的服务器地址与老地址是否相同,若不相同则会根据新的地址创建Address对象及StreamAllocation对象。
RetryAndFollowUpInterceptor对重定向的响应也不会无休止的处理下去,它处理的最多的重定向级数为20次,超过20次时,它会抛异常出来。
RetryAndFollowUpInterceptor通过followUpRequest()从响应的信息中提取出重定向的信息,接着通过sameConnection来判断是否需要重定向连接
RetryAndFollowUpInterceptor主要做了
创建StreamAllocation,以此传入到后续的Interceptor中
处理重定向的Http响应
桥接拦截器 BridgeInterceptor
@Override public Response intercept(Chain chain) throws IOException {
Request userRequest = chain.request();
Request.Builder requestBuilder = userRequest.newBuilder();
RequestBody body = userRequest.body();
if (body != null) {
MediaType contentType = body.contentType();
if (contentType != null) {
requestBuilder.header("Content-Type", contentType.toString());
}
long contentLength = body.contentLength();
if (contentLength != -1) {
requestBuilder.header("Content-Length", Long.toString(contentLength));
requestBuilder.removeHeader("Transfer-Encoding");
} else {
requestBuilder.header("Transfer-Encoding", "chunked");
requestBuilder.removeHeader("Content-Length");
}
}
...
List<Cookie> cookies = cookieJar.loadForRequest(userRequest.url());
if (!cookies.isEmpty()) {
requestBuilder.header("Cookie", cookieHeader(cookies));
}
if (userRequest.header("User-Agent") == null) {
requestBuilder.header("User-Agent", Version.userAgent());
}
Response networkResponse = chain.proceed(requestBuilder.build());
HttpHeaders.receiveHeaders(cookieJar, userRequest.url(), networkResponse.headers());
Response.Builder responseBuilder = networkResponse.newBuilder()
.request(userRequest);
if (transparentGzip
&& "gzip".equalsIgnoreCase(networkResponse.header("Content-Encoding"))
&& HttpHeaders.hasBody(networkResponse)) {
GzipSource responseBody = new GzipSource(networkResponse.body().source());
Headers strippedHeaders = networkResponse.headers().newBuilder()
.removeAll("Content-Encoding")
.removeAll("Content-Length")
.build();
responseBuilder.headers(strippedHeaders);
responseBuilder.body(new RealResponseBody(strippedHeaders, Okio.buffer(responseBody)));
}
return responseBuilder.build();
}
可以看到在BridgeInterceptor中,主要用于用于完善请求头,比如Content-Type、Content-Length、Host、Connection、Accept-Encoding、User-Agent等等,这些请求头不用用户一一设置,如果用户没有设置该库会检查并自动完善。此外,这里会进行加载和回调cookie。
缓存拦截器 CacheInterceptor
@Override public Response intercept(Chain chain) throws IOException {
//根据Request获取缓存中的Response
Response cacheCandidate = cache != null
? cache.get(chain.request())
: null;
long now = System.currentTimeMillis();
//根据请求头获取用户指定的缓存策略,并根据缓存策略来获取networkRequest,cacheResponse。
CacheStrategy strategy = new CacheStrategy.Factory(now, chain.request(), cacheCandidate).get();
Request networkRequest = strategy.networkRequest;
Response cacheResponse = strategy.cacheResponse;
...
//如果不需要网络则直接返回从缓存中读取的Response
if (networkRequest == null) {
return cacheResponse.newBuilder()
.cacheResponse(stripBody(cacheResponse))
.build();
}
Response networkResponse = null;
try {
networkResponse = chain.proceed(networkRequest);
}
...
// If we have a cache response too, then we're doing a conditional get.
if (cacheResponse != null) {
if (validate(cacheResponse, networkResponse)) {
Response response = cacheResponse.newBuilder()
.headers(combine(cacheResponse.headers(), networkResponse.headers()))
.cacheResponse(stripBody(cacheResponse))
.networkResponse(stripBody(networkResponse))
.build();
networkResponse.body().close();
// Update the cache after combining headers but before stripping the
// Content-Encoding header (as performed by initContentStream()).
cache.trackConditionalCacheHit();
cache.update(cacheResponse, response);
return response;
} else {
closeQuietly(cacheResponse.body());
}
}
Response response = networkResponse.newBuilder()
.cacheResponse(stripBody(cacheResponse))
.networkResponse(stripBody(networkResponse))
.build();
if (HttpHeaders.hasBody(response)) {
CacheRequest cacheRequest = maybeCache(response, networkResponse.request(), cache);
response = cacheWritingResponse(cacheRequest, response);
}
return response;
}
缓存拦截器,首先根据Request中获取缓存的Response,然后根据用于设置的缓存策略来进一步判断缓存的Response是否可用以及是否发送网络请求。如果从网络中读取,此时再次根据缓存策略来决定是否缓存响应。
这块代码比较多,但也很直观,主要涉及 HTTP 协议缓存细节的实现,而具体的缓存逻辑 OkHttp 内置封装了一个 Cache 类,它利用 DiskLruCache,用磁盘上的有限大小空间进行缓存,按照 LRU 算法进行缓存淘汰,这里也不再展开。
我们可以在构造 OkHttpClient 时设置 Cache 对象,在其构造函数中我们可以指定目录和缓存大小:
public Cache(File directory, long maxSize);
而如果我们对 OkHttp 内置的 Cache 类不满意,我们可以自行实现 InternalCache 内置缓存接口,在构造OkHttpClient 时进行设置,这样就可以使用我们自定义的缓存策略了。
建立连接 ConnectInterceptor
@Override public Response intercept(Chain chain) throws IOException {
RealInterceptorChain realChain = (RealInterceptorChain) chain;
Request request = realChain.request();
StreamAllocation streamAllocation = realChain.streamAllocation();
// We need the network to satisfy this request. Possibly for validating a conditional GET.
boolean doExtensiveHealthChecks = !request.method().equals("GET");
HttpStream httpStream = streamAllocation.newStream(client, doExtensiveHealthChecks);
RealConnection connection = streamAllocation.connection();
return realChain.proceed(request, streamAllocation, httpStream, connection);
}
可以看到,在ConnectInterceptor获取到StreamAllocation,而StreamAllocation的创建则是在 RetryAndFollowUpInterceptor重定向拦截器这里。
接着调用到了streamAllocation.newStream,前面介绍到,在newStream方法中会通过RealConnection建立与服务器之间的连接
实际上建立连接就是创建了一个 HttpCodec 对象,它将在后面的步骤中被使用,那它又是何方神圣呢?它是对 HTTP 协议操作的抽象,有两个实现:Http1Codec 和 Http2Codec,顾名思义,它们分别对应 HTTP/1.1 和 HTTP/2 版本的实现。
在 Http1Codec 中,它利用 Okio 对 Socket 的读写操作进行封装,Okio 以后有机会再进行分析,现在让我们对它们保持一个简单地认识:它对 java.io 和 java.nio 进行了封装,让我们更便捷高效的进行 IO 操作。
发送和接收数据 CallServerInterceptor
@Override public Response intercept(Chain chain) throws IOException {
HttpStream httpStream = ((RealInterceptorChain) chain).httpStream();
StreamAllocation streamAllocation = ((RealInterceptorChain) chain).streamAllocation();
Request request = chain.request();
long sentRequestMillis = System.currentTimeMillis();
httpStream.writeRequestHeaders(request);
if (HttpMethod.permitsRequestBody(request.method()) && request.body() != null) {
Sink requestBodyOut = httpStream.createRequestBody(request, request.body().contentLength());
BufferedSink bufferedRequestBody = Okio.buffer(requestBodyOut);
request.body().writeTo(bufferedRequestBody);
bufferedRequestBody.close();
}
httpStream.finishRequest();
Response response = httpStream.readResponseHeaders()
.request(request)
.handshake(streamAllocation.connection().handshake())
.sentRequestAtMillis(sentRequestMillis)
.receivedResponseAtMillis(System.currentTimeMillis())
.build();
if (!forWebSocket || response.code() != 101) {
response = response.newBuilder()
.body(httpStream.openResponseBody(response))
.build();
}
if ("close".equalsIgnoreCase(response.request().header("Connection"))
|| "close".equalsIgnoreCase(response.header("Connection"))) {
streamAllocation.noNewStreams();
}
int code = response.code();
if ((code == 204 || code == 205) && response.body().contentLength() > 0) {
throw new ProtocolException(
"HTTP " + code + " had non-zero Content-Length: " + response.body().contentLength());
}
return response;
}
我们抓住主干部分:
- 向服务器发送 request header;
- 如果有 request body,就向服务器发送;
- 读取 response header,先构造一个 Response 对象;
- 如果有 response body,就在 3 的基础上加上 body 构造一个新的 Response 对象;
CallServerInterceptor首先将http请求头部发给服务器,如果http请求有body的话,会再将body发送给服务器,继而通过httpStream.finishRequest()结束http请求的发送。
请求完成之后,我们就可以从 Response 对象中获取到响应数据了,包括 HTTP status code,status message,response header,response body 等。这里 body 部分最为特殊,因为服务器返回的数据可能非常大,所以必须通过数据流的方式来进行访问(当然也提供了诸如 string() 和 bytes() 这样的方法将流内的数据一次性读取完毕),而响应中其他部分则可以随意获取。
响应 body 被封装到 ResponseBody 类中,该类主要有两点需要注意:
- 每个 body 只能被消费一次,多次消费会抛出异常;
- body 必须被关闭,否则会发生资源泄漏;
小结
RetryAndFollowUpInterceptor : 创建StreamAllocation对象,处理http的重定向,出错重试。对后续Interceptor的执行的影响:修改request及StreamAllocation。
BridgeInterceptor:补全缺失的一些http header,Cookie设置。对后续Interceptor的执行的影响:修改request。
CacheInterceptor:处理http缓存。对后续Interceptor的执行的影响:若缓存中有所需请求的响应,则后续Interceptor不再执行。
ConnectInterceptor:借助于前面分配的StreamAllocation对象建立与服务器之间的连接(具体建立是在newStream方法中),并选定交互所用的协议是HTTP 1.1还是HTTP 2。对后续Interceptor的执行的影响:创建了httpStream和connection。
CallServerInterceptor:处理IO,与服务器进行数据交换。对后续Interceptor的执行的影响:为Interceptor链中的最后一个Interceptor,没有后续Interceptor。
在文章最后我们再来回顾一下完整的流程图: