介绍 Python 相关工具,工作流程和测试框架。
引言
接续着之前的文章 (虽然隔得比较久...),本文继续介绍以 Windows 平台为背景的 Python 开发相关的工具。希望能对你有所帮助。另外很多东西本文都是延续之前那篇,有这里没仔细讲的东西那都在之前的文章里。
Python 大家族
首先得提一下 Python 语言和 Python 实现之间的关系。计算机语言本身可以说是一个规范,一个很好的例子就是 Scheme。R5RS 就是 Scheme 语言的一个规范文档,这里基本上规定了语言的规则,语法等方方面面。但是光有文档肯定还是不行的,所以就会有人根据语言的规范来实现一个能用的语言编译器或者解释器。对于 Python 来说,其语言的规范在文档里的 The Python Language Reference。而我们常用的 Python 常常被称为 CPython,这是官方提供的,也是使用最广泛的一个实现。事实上 Python 作为一个流行的语言还有着很多不同的实现。下面会介绍一些其他的 Python 实现,和一些 Python 衍生的语言。
PyPy
如果你经常关注 Python 相关的新闻那你一定看到过 PyPy。概括的讲它的目标是实现一个与 Python 完全兼容但速度要快很多的 Python 实现。在官方提供的评测页面中,你可以看到现在 PyPy 比 CPython 要快5倍左右。然而它自身也有一个很麻烦的问题就是 PyPy 不兼容 C 扩展,这也是它一直以来难以得到普及的一个原因。
对于我等一般用户来说,PyPy 已经算是相当成熟了。现在的 PyPy 2.0 是一个与 Python 2.7 兼容的版本,其中绝大部分标准库的内容都是可以使用的,而且大部分纯 Python 库也没有问题。官方现在提供包括 Windows 的各种版本的包裹下载。你可以自己尝试下使用 PyPy 有没有使你的程序跑的更快。如果可以的话那你就完全不费力气的获得了性能的提升,这也是 PyPy 项目吸引人的地方之一。
另一方面 PyPy 本身也提供了一套开发语言解释器的框架。官方博客有一篇文章介绍了如何编写一个简单 Brainfuck 解释器。
IronPython
IronPython 是微软 .Net 平台上的一个 Python 实现。事实上这基本上算是来自微软的一个开源项目,其所使用的 DLR 也是 .Net 4.0 中一个新的重要功能。
由于工作的原因我之前试着用了下 IronPython,感觉真是...惊呆了。如果试过在 C/C++ 项目中嵌入 Lua 或者其他脚本语言的经验,你会觉的要能让他正常的跑起来其实还是挺难的。起码你自己要处理将 C 的函数或者 C++ 的 Class 暴露到脚本语言中,处理脚本中的异常等等。总之就是挺麻烦。
但如果是用 IronPython 那基本上那你要操心的事情就非常少了。像 Class 都可以直接暴露给 IronPython,C# 可以直接接到 IronPython 中的异常,也可以很容易的取得 IronPython 中的值或者 Class。而且 IronPython 可以很简单的使用 .Net 中的类,事实上你都可以用 IronPython 来写 WinForms 程序。总而言之,就是太方便了。
在效率方面的话其实 IronPython 跟 CPython 没有太大区别。但是如果你是 .Net 开发者的话一定得看看 IronPython。说不定就有机会用到。
相对于 .Net 平台,在 Java 上也有对应的 Jython 项目。不过这个我完全没有用过所以没什么可以说的。
Cython
"在Python中性能不够的地方,你可以用C语言来重写从而提升效率" - 我估计你应该在哪里看到过类似的说法。但这个到底应该怎么做呢? 要用 C 语言来重写 Python 模块说实话是个挺麻烦的事情。好消息是 Cython 就是针对这个问题的一个项目。Cython 提供了一个类似 Python 的强类型语言,Cython 可以将其编译为 C 的代码,然后你可以很轻松的将其编译成 Python 的 C 扩展 .pyd 文件。pyd 文件在 Windows 下其实就是 dll,如果使用 Cython 的话你就可以省去很多麻烦的事情。
但是坏消息是所有扯到 C 语言的东西在 Windows 上都显得非常麻烦。Cython 的配置也相对比较复杂。好消息是你还是可以通过安装超牛逼的 PythonXY 来把所有事情都搞定。
跟目标 Cython 类似的,调用 C/C++ 原生代码扩展的框架还有 cffi, swig 以及标准库中的 ctypes。
Windows 上同时安装 Python3 和 Python2
到 2014 年初,Python3 发布已经整整五年了。虽然用的人不多,但现在的情况是大部分流行的纯 Python 的库,特别是 Web 相关的基本都有了 Python3 的版本。毕竟现在 2.x 系列版本已经停止了新功能的开发,而 Python 3 虽然没有什么大的变动,但一直在加入一些有意思的库和新功能。现在 Python 3 已经即将发布 3.4 版本,是时候开始试试了。
但是现实生活总是这么残酷,你不太可能立马卸载掉系统上的 Python 2 换上新的。在 Linux 下很多发行版提供了额外的 Python 3 包裹,可以用 python3 来调用就很方便。事实上在 Windows 上也可以,只是需要很多手动操作而且会有莫名的问题。现在 Python 3.3 版本为 Windows 特地加入了一个 Launcher,让 2.x 和 3.x 在 Windows 上并存变得非常简单。
安装 Python 3.3+
首先,下载 Python 3.3 以上的版本进行安装。过程中需要注意在配置界面,取消掉 "Register Extensions" 和 "Add python.exe to Path" 两个选项,这样就不会影响到你系统中的 Python 2.x。
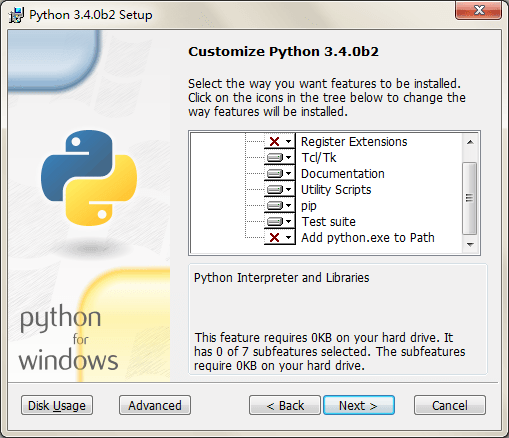
完成安装之后,会有 py.exe 和 pyw.exe 两个可执行文件被拷贝到你的 Windows 目录下,它们总是默认在 Path 上的,所以可以直接在命令行里被调用。之后你就可以用 py 来选择你要使用的 Python 版本
py -2 # 运行 Python 2.x
py -3 # 运行 Python 3.x
py -2.7 # 运行某个指定的版本
更棒的是,py.exe 可以解析你运行的程序第一行的 #! (shebang)。这个在 Windows 下其实是不管用的,但是 py.exe 会根据里面写的内容来运行对应的版本:
# 以下都要写在程序第一行,Linux 系统是会真正的读取这一行的内容来找 runtime
# 用 Python 3 执行
#!python3
# 用 Python 2 执行
#!python2
# 可以写成 Linux 常见的形式,这样也有效而且可以方便跨平台
#!/usr/bin/python3
但有一个比较麻烦的问题是,Python 3 安装目录下的 Scripts 文件夹,也就是存放各种库的可执行文件的文件夹,默认不会被放到 Path 上,而且就算你手动放上去偶尔也会弄混。好在 py.exe 在 '-3' 后面的参数都会正常的传给真正运行的 Python 解析器。利用这一点我们可以不需要额外配置,就调用到库的脚本。
python -m
相信很多人应该用过这个东西,Python 很多标准库都提供这样的调用方式来实现一些简单的命令行功能。Python 3 现在自带 pip。比如我们想使用 Python 3 的 pip 来安装别的库,我们可以这样:
py -3 -m pip install bottle
跟你预料的一样,这样就可以了。当然你可以用个 .bat 文件来把这些包裹起来并放在 Path 上,一个简单的例子,把下面的内容写到一个叫 pip3.bat 的文件里:
@echo off
py -3 -m pip %*
并放到 Path 上,就可以方便调用了。其中 %* 负责传递所有的命令行参数。
实际上 python -m 可以用的东西还真的挺多,这里给出一个不完全的列表:
# 缩进输出 JSON
echo {"hey" : "kid"} | python -m json.tool
# 简单的执行时间测量
python -m timeit [ix*ix for ix in range(100)]
# 简单的 Profiling
python -m cProfile myscript.py
# 比较两个文件夹的区别
python -m filecmp path/to/a path/to/b
# base64 转换
echo foo bar | python -m base64
# 调用默认浏览器打开一个新标签页
python -m webbrowser -t http://google.com
# 生成程序文档
python -m pydoc myscript.py
# 类似 nose 的自动搜索 unittest
python -m unittest discover
# 调用 pdb 执行代码
python -m pdb myscript.py
安装 IPython
IPython 2.0 最近发布了,采用了新的 wheel 格式来打包二进制,然后使得在 Windows 上的安装变得非常简单。运行:
py -3 -m pip install ipython
然后如果你已经把 C:\Python3x\Scripts 放到 PATH 上了后,直接运行 ipython3 就好了。
我的 Python 开发流程
我一直觉得我的 Python 使用情况应该很有代表性。我经常写独立的脚本或者几个文件一起组成一个小的程序,没有正式的写过要给别人用的库。所以我在做 Python 开发的时候大多数时候都是写几行跑一下,大部分时间在跑程序。我自觉地找到了一个感觉非常好的开发流程,这里简单的介绍一下,希望能对你有帮助。
I P Y T H O N
现在我做任何 Python 相关的东西都离不开 IPython 了。虽然没有用到任何里面向科学计算的高端的功能,但是就算是日常开发我感觉 IPython 也能带来极大的效率提升。而 IPython 也是我在 Python 开发上完全放弃 IDE 的原因。用 IPython 加上你最喜欢的文本编辑器,感觉就像能飞起来!
IPython 和 Python 自带的 repl 比起来就像是 Windows 上的 cmd 和 Linux 下的 bash 之间的区别。IPython 不需要任何配置就可以进行 tab 键补全,按上下选取历史命令(甚至支持 Ctrl + R!),和 pdb 有非常完美的集成。
一个实际的例子
这里以一个简单的例子来讲解一下上面描述的是怎样的一个情况。我们要写一个可以将简单的数据表达式,类似 1 + (2 - 3) * 456 解析成树的 Pratt Parser。首先我们需要一个 lexer 把每个 token 解析出来,那么最开始的代码就是:
# simple math expression parser
def lexer(s):
'''token generator, yields a list of tokens'''
yield s
if __name__ == '__main__':
for token in lexer("1 + (2 - 3) * 456"):
print token
明显这个没有任何意义,但现在程序已经有足够的东西能够跑起来。我们把这个程序存为 expr.py,开启一个命令行窗口,运行 ipython 然后像这样执行它:
$ ipython
IPython 0.13.1 -- An enhanced Interactive Python.
? -> Introduction and overview of IPython's features.
...
In [1]: run expr.py
1 + (2 - 3) * 456
在 IPython 里面用 run 跑的好处有很多,首先是你在程序执行完毕后整个程序的状态,比如最后全局变量的值,你写的函数这些你都是可以随便执行的!同样的你可以在 IPython 里面保存一些用来测试的常量,每次用 run 跑的话新的程序会被重新载入,你可以这样方便的测试每个函数,有一个非常动态的环境来调试你的程序:
In [2]: print token # 注意这里 token 就是 __main__ 里面的那个 token 的值
1 + (2 - 3) * 456
In [3]: print list(lexer('1+2+3')) # 可以运行你写的函数
['1+2+3']
然后按照之前的想法,我们尝试把这个 lexer 写出来。在这个过程中,IPython 可以用来查看函数的文档,测试如何调用某些函数,看看返回值是什么样子等等,还是跟上面的说的一样,我们有一个动态的环境可以真真正正的执行程序,你可以在把代码写到你珍贵的主程序之前就有机会运行它,这样你可以更确认你的代码能正常工作:
In [4]: s = "foo" # 忘记判断字符串是数字的函数的名字了,用一个字符串试试看
In [5]: s.is # 开头大概是 is,这里按下 tab 键 IPython 会帮我们补全
s.isalnum s.isalpha s.isdigit s.islower s.isspace s.istitle
In [6]: s.isdigit? # 结果是 isdigit,在表达式后加上问号并回车查看文档
Type: builtin_function_or_method
String Form:<built-in method isdigit of str object at 0x1264f08>
Docstring:
S.isdigit() -> bool
Return True if all characters in S are digits
and there is at least one character in S, False otherwise.
In [8]: s.isdigit() # 调用试试看
Out[8]: False
In [9]: 'f' in 'foo' # 试试字符串能不能用 in 来判断
Out[9]: True
确认了各个步骤以后,我们把 lexer 的代码填起来。我们为了节省纵向的空间我们把很多东西写在一行里面:
# simple math expression parser (broken lexer)
def lexer(s):
'''token generator'''
ix = 0
while ix < len(s):
if s[ix].isspace(): ix += 1
if s[ix] in "+-*/()":
yield s[ix]; ix += 1
if s[ix].isdigit():
jx = ix + 1
while jx < len(s) and s[jx].isdigit(): jx += 1
yield s[ix:jx]; ix = jx
else:
raise Exception("invalid char at %d: '%s'" % (ix, s[ix]))
yield ""
if __name__ == '__main__':
print list(lexer("1 + (2 - 3) * 456"))
看起来不错,我们还是在 IPython 里执行试试,结果发现程序抛出了一个异常:
In [6]: run expr.py
------------------------------------------------------------------
Exception Traceback (most recent call last)
py/expr.py in <module>()
18
19 if __name__ == '__main__':
---> 20 print list(lexer("1 + (2 - 3) * 456"))
py/expr.py in lexer(s)
13 yield s[ix:jx]; ix = jx
14 else:
---> 15 raise Exception("invalid character at ...))
16 yield ""
17
Exception: invalid character at 3: ' '
嗯?好像程序里已经处理了空格的情况。怎么会这样?不知道你碰到异常的时候一般都怎么办。你可能会选择到处添加 print,用 IDE 断点调试。其实这种情况用 pdb 是很明智的选择,在 IPython 里我们可以非常轻松的使用它。
In [13]: pdb # 开启 pdb ,这样在异常的时候我们会自动的 break 到异常处
Automatic pdb calling has been turned ON
In [14]: run expr.py
-----------------------------------------------------------------
Exception: invalid character at 3: ' '
> py/expr.py(15)lexer()
14 else:
---> 15 raise Exception("invalid char at ...))
16 yield ""
ipdb> print ix # 这里我们可以执行任何 Python 的代码
3
ipdb> whatis ix # 也可以用 pdb 提供的命令,输入 help 可以查看所有命令
<type 'int'>
通过方便的调试和仔细检查代码,我们发现是没有正确的使用 elif 造成了问题!(我知道这个过程不是太符合情理...)。把代码里的后面的几个 if 都换成 elif 以后我们发现结果基本上是对的了。我们可以马上再跑几个类似的例子,确认不同的输入是否都有比较好的结果:
In [18]: run expr.py # 这次差不多对了,我们可以试试几个别的例子
['1', '+', '(', '2', '-', '3', ')', '*', '456', '']
In [19]: print list(lexer("1*123*87-2*5"))
['1', '*', '123', '*', '87', '-', '2', '*', '5', '']
# 跟在 shell 里面一样,你可以用上下来选取之前的记录,然后简单的修改再重新执行。
# 记得每次 run 后你的函数都是最新版本,你可以很简单的用重复的数据来测试你的函数
# IPython 甚至还实现了 Ctrl+R!自己试试看吧
In [19]: print list(lexer("1 + two"))
Exception: invalid character at 2: 't'...
在一段痛苦的调试之后,我们最终把程序写出来了。很遗憾程序超出了我预计的长度,就不贴在这里了。后面部分的开发过程跟前面基本还是一样,总结起来就是:
- 保持你的程序是一个可以运行并且有意义的状态,尽可能频繁的运行。
- 在 IPython 里查看文档,尝试小的程序片段,测试些你不确定的做法,确定之后再把东西添加到你的代码里。
- 用不同的参数在 IPython 里测试你正在编写的函数/class。
- 当遇到问题的时候,先简单的用
pdb在异常处 break,十有八九都能有些头绪。
额外的注意事项
这里举的例子是你所有的开发都是在单个 .py 文件里的。现实生活中你很有可能会横跨几个文件一起修改。请务必注意,在 IPython 里你每次 run 的时候只有被 run 的那个文件里的东西会是最后修改的版本,其 import 的东西如果在期间被修改是不会反应出来的。
这个的原理就跟你在 Python shell 里在修改前修改后重复 import 某个模块不会有作用是一样的,Python 神奇的 import 机制不会去追踪其他模块的修改。你可以手动用 reload 函数来重新载入,你也可以使用 IPython 的 autoreload 功能来让你忽略这个问题。个人来说我没怎么用过这个功能,IPython 没有默认开启它可能也是有些顾虑,请自己评估看看。
另外你应该已经注意到,run 的效果基本上就是把你的代码拷贝进 IPython 里执行一遍。对于没有 __main__ 的文件,你也可以 run,这样里面定义的函数和 class 就会反映出你的更改。
IDE, lint 和测试
不知不觉又到了凑字数的部分,这里简单列举一下现在的 IDE 情况,lint 工具的使用以及简单的测试配置。
当下的 IDE 选择
之前的文章里推荐 PyDev 作为 IDE,很大部分原因是因为当时根本没有多少别的东西可以选。现在虽然我自己很少使用 IDE,但有看到新的工具出来。
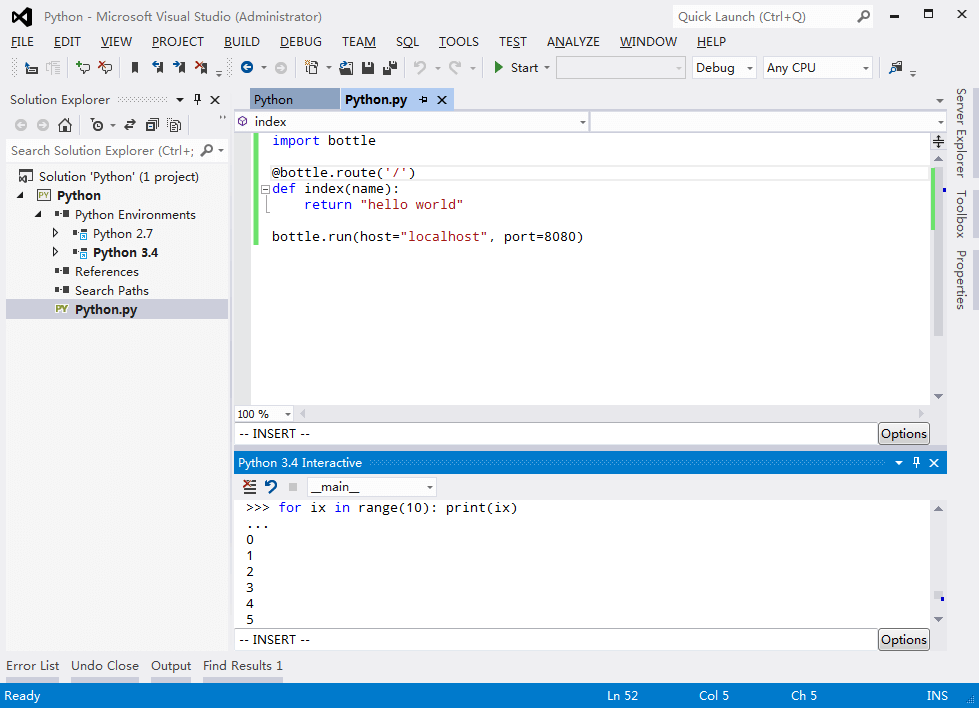
正在阅读这篇文章的你十有八九电脑上都装着个 Visual Studio,那么这个只有 5mb 大小的半官方的 Python 插件绝对可以先试一试。我用了下发现功能很够用,装好后会自动搜索你机器上安装的 Python 版本,3.x 也可以支持。其自动补全也是通过提前索引所有安装的库来做,效果可谓是相当不错。作为 Visual Studio 的插件,你理所当然的 IDE 功能 PTVS 也支持了不少。比如豪华的断点调试 (你甚至可以把鼠标移到代码中的变量上看它当前的值) ,难得的 Refactor (变量重命名,简化 import 语句)。另一个优势就是你可以继续使用其他配套的插件,比如 VsVim 等等。
PTVS 的文档里还介绍了面向科学计算的 IPython 集成,你可以让 IPython 里面画的图直接显示在 VS 里面。
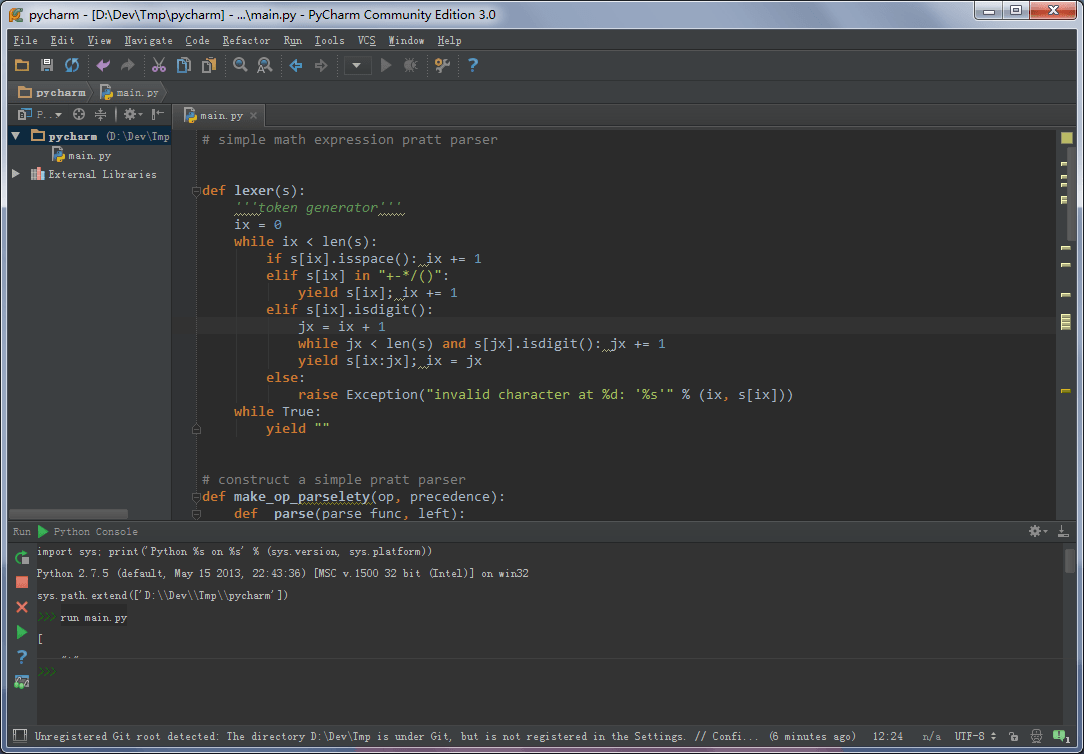
PyCharm 的名声一直是 "最好的 Python IDE"。做过 Java 开发的同学肯定知道 Eclipse 现在最大的竞争对手就是 IntelliJ,而 PyCharms 就是基于 intelliJ 开发的。说实话我总觉得 IntelliJ 可能是上手难度最高的一个 IDE,我始终没学会。但可以感觉到它的确做的很好,而且只要用熟一个那么他们一系列的 IDE 就都没问题了。
当你配置好 Python 版本,调整好字体,选好配色再打开一个已有的 Python 文件以后,你会发现跟 Java 一样它会给你列出很多 Warning 的地方。PyCharm 除了会做简单的 pep8,还会做一些高级的静态分析来判断某些变量是不是存在。这些高级功能对动态语言来说意义不太大,但根据个人喜好有人会非常喜欢这种功能。比起 PTVS,PyCharm 提供的重构和代码浏览功能就强大的多了。这里有一篇文章介绍了 PyCharm 优秀的地方。
linting
Python 这样的动态语言跳过了编译这一步,一个负面的效果就是少了一个发现错误的机会。对于简单的语法错误,我们只要跑一下程序马上就能发现。但是有些微妙的错误虽然很明显,但从你眼皮底下溜到了运行时还是会让人很恼怒。这时候就是静态分析出场的时候了。他们仅仅从代码文本的角度进行解析来尝试找到一些简单的错误和代码中不好的地方。不同的软件有不同的目标,这里简单的介绍一下。
pyflakes 功能非常简洁,它仅仅尝试检查标准的"疏忽"错误,比如引用了一个前面没有声明的变量,有声明的变量但没有使用。这类问题很多时候都能帮助你找到一些愚蠢而又难以察觉到的 bug。很多编辑器也有简单的 pyflakes 支持,你可以在编辑代码的时候实时的看到这些问题。
到现在你应该已经知道了,要安装 pyflakes 只要 pip install pyflakes 就可以了,执行的话以你的程序文件为参数运行 pyflakes foo.py 即可。后面几个也是完全一样的安装和运行方式。
PEP 8 -- Style Guide for Python Code 是一个官方的代码风格规范,规定了像用空格还是 tab (必须用空格!),每行不能超过多少行这些琐碎的风格上的问题。而 pep8 是按照这个规范来检查代码的程序。我个人认为强硬的遵守这种意义不是很大,但要养成好习惯的话还是可以多试试这个。
pylint 就是很重量级的所谓代码质量工具了。它的功能应该包括了 pyflakes 的功能,还有很多更加琐碎的东西,默认情况还会给你的代码打个分。个人来说我不太原意用这个,它的目标受众可能也是企业级团队。
为什么你不愿意写测试
我感觉大部分人懒得写的原因大部分可能还是觉得太麻烦了。好消息是我感觉现在所有的测试工具都在向让事情更简单的方向发展。就 Python 来说,你只要走通了一次就知道 Python 测试是多么简单了。
接着我们上面的例子来说,我们想要跟 expr.py 加上一点测试。为了让事情变的更复杂,我们特地把目录结构组织成这样:
package
├── lib
│ └── expr.py
└── test
└── test_lexer.py
package 是我们的当前目录。其中 test/test_lexer.py 的内容是如下:
from expr import lexer
def token_list(s):
ls = []
for t in lexer(s):
if t != '':
ls.append(t)
else:
return ls
def test_lexer():
assert token_list('1+2/3') == '1 + 2 / 3'.split()
assert token_list('1+(2-3)*456') == '1 + ( 2 - 3 ) * 456'.split()
def test_lexer_throw():
try:
token_list('not really')
except Exception, e:
assert e.message.startswith('invalid character')
接下来确认我们已经安装了 nose (pip install nose,你懂的) 以后,在 package 目录下运行 nosetests,可以看到结果。
$ nosetests -v
test_lexer.test_lexer ... ok
test_lexer.test_lexer_throw ... ok
------------------------------------------
Ran 2 tests in 0.002s
OK
这样我们在没有任何额外配置和 import 任何别的东西的时候,就有了一组简单的测试。为什么 test_lexer.py 里面可以 import 的到 expr.py 的内容,以及这些测试函数是如何被找到的,这些都归结于 nose 的一系列 "魔法"。它有一些"启发式"的规则来让大部分常见的目录结构和测试组织形式都能够顺利的跑起来。具体的讲,nose 发现我们有一个 lib 目录,估计这个是我们的库,就把它加入到了 PYTHONPATH 上。后面 nose 又看到了 test/test_lexer.py,它会认为所有名字里面有 test 的 Python 文件都是测试,并在里面寻找有名字里面有 test 的函数作为测试来跑。这个机制叫做 "test discovery",详细的规则在这里有介绍。
在写测试用例的时候你往往很难第一次就写对,比如我们这里添加了一个新的例子:
assert token_list('1+2+3') == '1 + 2 / 3'.split()
在运行的时候发现这个测试失败了:
$ nosetests
F.
============================================
FAIL: test_lexer.test_lexer
--------------------------------------------
Traceback (most recent call last):
File "test/test_lexer.py", line 14, in test_lexer
assert token_list('1+2+3') == '1 + 2 / 3'.split()
AssertionError
--------------------------------------------
Ran 2 tests in 0.002s
FAILED (failures=1)
说实话这个结果很难一下看出来到底是哪里出了问题。虽然说测试的目的就是发现问题,但很重要的一个部分也是要尽可能方便的找到错误的原因。做到这个的一个简单方法就是让测试输出更有意义的错误信息。使用标准库的 unittest 的 TestCase 和其自带的 assert 方法就可以轻易的做到这点。我们把我们的测试用 unittest 的标准方法重写一遍:
from unittest import TestCase
class LexerTest(TestCase):
def test_lexer(self):
self.assertEqual( token_list('1 + 2 / 3'), '1 + 2 / 3'.split() )
self.assertEqual( token_list('1 + (2 - 3) * 456'),
'1 + ( 2 - 3 ) * 456'.split() )
self.assertEqual( token_list('1+2+3'), '1 + 2 / 3'.split() )
def test_lexer_throw(self):
with self.assertRaisesRegexp(Exception, 'invalid character'):
token_list('not really')
毫无悬念的 nose 也会支持这种测试形式。运行 nosetests 我们可以清楚的看到是哪里出了问题:
$ nosetests
F.
===================================================
FAIL: test_lexer (test_lexer.LexerTest)
---------------------------------------------------
Traceback (most recent call last):
File "test/test_lexer.py", line 16, in test_lexer
self.assertEqual( token_list('1+2+3'), '1 + 2 / 3'.split() )
Error: Lists differ: ['1','+','2','+','3'] != ['1','+','2','/','3']
First differing element 3:
+
/
- ['1', '+', '2', '+', '3']
? ^
+ ['1', '+', '2', '/', '3']
? ^
---------------------------------------------------
Ran 2 tests in 0.005s
FAILED (failures=1)
assertEqual 函数在断言失败的时候给出了非常清晰的错误信息,包括指出具体是哪个地方不一样。把错误的 '/' 换成 '+' 就可以了。
Python 有着繁多的测试相关的库,用于满足各种不同的测试需求。比如 testtools 提供了可以组合的 assert 函数,以及很多 IO 相关的测试函数实现。还有更为高端的 pytest 提供更多的功能。一个好消息是大部分测试相关的库都可以混着用,所以可以根据你的具体需求挑选。
(我认为的) Python 糟糕的地方
如果我要是有机会写什么剧本那我打算搞一个反高潮的结局。所以这里列出我所认为的 Python 做的不太好的地方。俗话说做人拥有独立的人格和客观的视角最重要,这里希望你能简单看过就好不要太上心...
- 隐式的变量声明。我一直觉得用
:=来做变量初始化是最好的办法。 - 糟糕的 scoping。没有 block scope 导致循环的变量到循环结束还能用,Python 3 加入的
nonlocal这些都是表现。 - lambda 太弱。仅支持单个 expression 让人头疼的想哭。在 Python 2.x 试试 map 和 print 一起用你就知道了。
- 原生类型和 Object 的区别太大,没法由用户自建类似原生类型的类似行为的对象,以及其带来的 pass-by-sharing, 上面提到的
nonlocal和著名的def foo(ls = [])问题。 - 某些莫名的不一致。印象最深刻的就是你可以用 StringIO 建一个 File-like object,可以用在大多数可以接受 file object 的地方。在 subprocess 里你可以把 STDOUT 重定向到一个 file object。猜猜看你能把 STDOUT 重定向到 StringIO Object 里么?
- 谜一样的
import行为。Guido 自己都说过(但我搜不到来源了...):"如果你认为你彻底了解了import是如何工作的那说明还没完全了解它"。例子包括迷离的from ... import, 诡异的 namespace package, 以及总有一天你会遇到的"明明就是在那里但就是 import 不进来"。 - 蛋疼的
.pyc文件。这么多动态语言似乎只有 Python 默认就要生成这个东西。 - Python 3 的现状。说实话我觉得 Python 3 让这个语言稍微变的有点没意思了,把 print 换成函数虽然很合理,但每次要多打个括号稍微有点恼火,而且既然 print 都改了不知道为什么 assert 仍然还是 statement。unicode 的改变也是很合理,但现实情况不是很理想。大量的 generator 使用可能有些效率上的提升,但是你每次在 repl 里拿到的东西必须加上个 list 才能显示出来,再加上之前 print 的括号,这些细小的地方的变化没有让人感觉很好。而相反的有意思的新功能大部分都是标准库的扩充,这些在 2.x 也是完全可以做的。
最后
Python 现在几乎是我工作中用的最多的一个语言。站在极端功利的角度来看,学习和使用 Python 在现在看来真的是非常划算的。古老的 Perl 现在会的人越来越少,原意学习的人几乎没有。同时期开始流行的 Ruby 现在很残酷的几乎没什么声音了。而 Python 由于在科学计算各个方向上的扩展吸引了更多来自 MatLab 和 R 的用户。Python 3 漫长的迁移过程似乎也没有产生太大的负面影响。站在不那么功利的角度来讲,程序员掌握一门脚本语言真的很重要。无论你是做什么工作,总有脚本语言上场的机会,而 Python 在此时此刻绝对是一个非常合理的选择。希望本文介绍的东西能对你的学习工作有所帮助。
