前言
大数据处理技术应用:
- [x] 电信运营商
- 数据营销:房地产营销、运营商时代(汇聚用户行为)
- [x] 互联网用户行为分析
- 数据驱动运营:漏斗模型、反作弊
- [x] P2P风控系统
- 个人征信(人民银行)、各大银行贷款记录
我们正在做的:
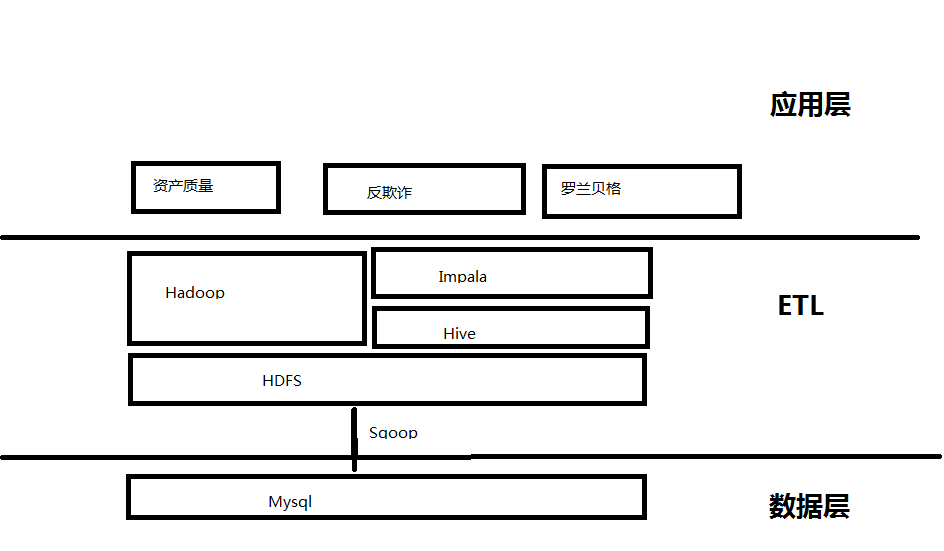
离线:
image
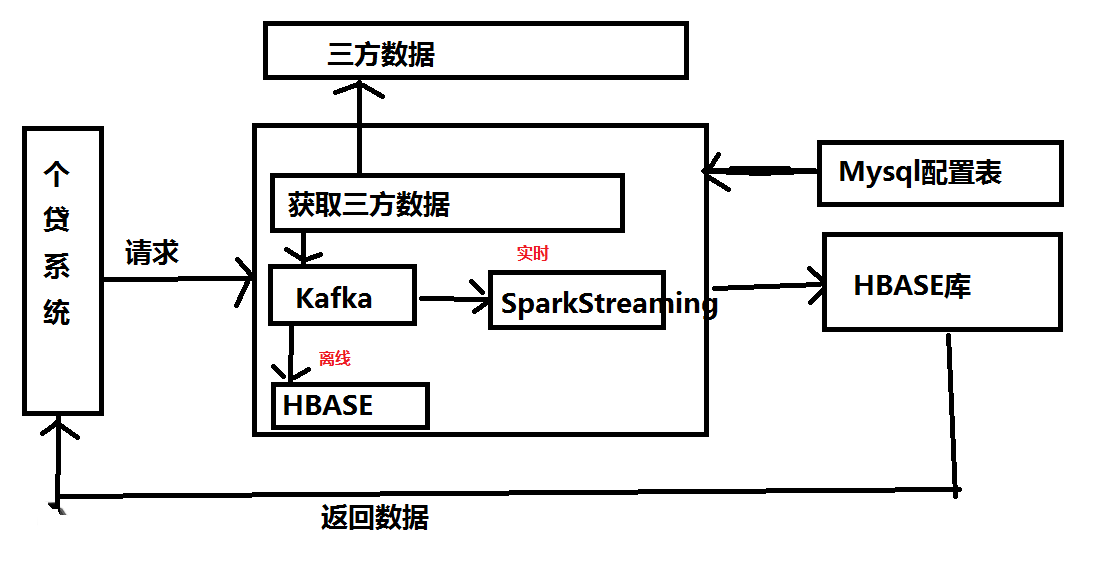
实时:
image
一、离线数据处理简介
(1)分布式计算(mapreduce)
数据仓库工具hive(基于磁盘存储)构建在mapreduce之上,支持标准化SQL的形式查询存储在HDFS上的数据,原理就是解析HiveQL,经过编译后(SQL转换成MapReduce任务)生成执行计划(多个Stage依赖)
(2)分布式存储(hdfs)
- 是一种允许文件 通过网络在多台主机(廉价商用机)上分享的文件系统,可让多机器上的多用户分享文件和存储空间。
- 通透性。让实际上是通过网络来访问文件的动作,由程序与用户看来,就像是访问本地的磁盘一般。
- 容错。即使系统中有某些节点脱机,整体来说系统仍然可以持续运作而不会有数据损失。
-
适用于 一次写入、 多次查询的情况,不支持并发写情况,小文件不合适
 image
image
(3)分布式资源调度(yarm)
通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处
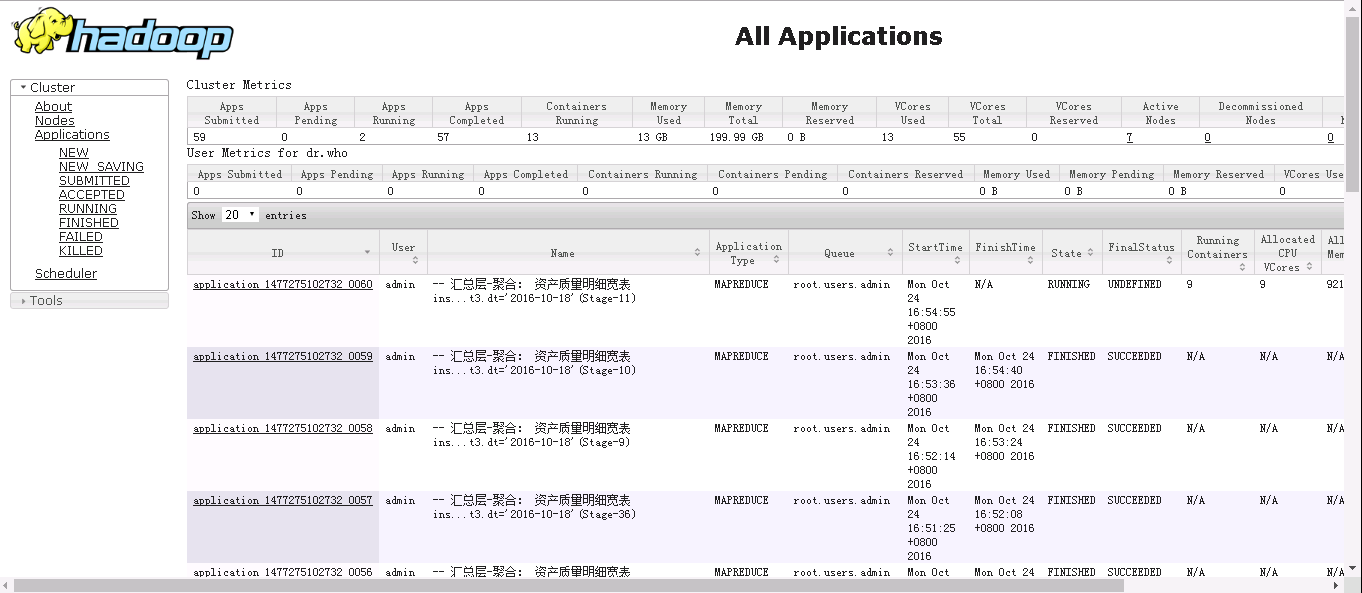
二、数据导入(sqoop)
(1)数据导入方式对比
- mysql表导出为文件形式,再使用hive load加载命令将数据导入Hadoop平台
优点:方式简单
缺点:数据可靠性得不到保障,扩展性低 - 开源工具Sqoop,基于MapReuce
优点:扩展性高
(2)介绍
Sqoop是一个用来将Hadoop和关系型数据库中的数据相互转移的工具,可以将一个关系型数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
对于某些NoSQL数据库它也提供了连接器。Sqoop,类似于其他ETL工具,使用元数据模型来判断数据类型并在数据从数据源转移到Hadoop时确保类型安全的数据处理。Sqoop专为大数据批量传输设计,能够分割数据集并创建Hadoop任务来处理每个区块。
(3)个贷数据迁入Hadoop平台
- [x] 基于个贷表元数据生成查询SQL,替换Hive敏感字符并统一数据类型
- 换行符、制表符、#等等统一替换成空格符
- 多种时间格式(timestamp、date、datetime)转换为Hive支持的统一时间格式
- [x] 开发迁移脚本
- 统一时间库
- 数据校验
- 动态链接个贷表
生成查询SQL脚本
SELECT
CASE
WHEN data_type IN('varchar','text','char') then
CONCAT('REPLACE(REPLACE(REPLACE(REPLACE(', column_name,',CHAR(13),'' ''),CHAR(10),'' ''),CHAR(9),'' ''),CHAR(44),'' ''),')
when data_type in('timestamp','date','datetime') then
CONCAT('DATE_FORMAT(', column_name, ',''%Y-%m-%d %h:%i:%s''),')
else
CONCAT(column_name,',')
END
FROM COLUMNS WHERE table_name='crm_repay_dk'
查询SQL样例
select
id,
contract_id,
REPLACE(REPLACE(REPLACE(REPLACE(account_number,CHAR(13),' '),CHAR(10),' '),CHAR(9),' '),CHAR(44),' '),
repay_method,
year,
DATE_FORMAT(first_repay,'%Y-%m-%d %h:%i:%s'),
status,
repay_status,
REPLACE(REPLACE(REPLACE(REPLACE(accntnm,CHAR(13),' '),CHAR(10),' '),CHAR(9),' '),CHAR(44),' '),
REPLACE(REPLACE(REPLACE(REPLACE(accntno,CHAR(13),' '),CHAR(10),' '),CHAR(9),' '),CHAR(44),' '),
REPLACE(REPLACE(REPLACE(REPLACE(bank,CHAR(13),' '),CHAR(10),' '),CHAR(9),' '),CHAR(44),' '),
REPLACE(REPLACE(REPLACE(REPLACE(branchnm,CHAR(13),' '),CHAR(10),' '),CHAR(9),' '),CHAR(44),' '),
loan_type,
from #tablename where $CONDITIONS
mysql导入hdfs脚本
sqoop import \
--connect jdbc:mysql://$server:$port/$mysql_database?tinyInt1isBit=false \
--username $username \
--password $password \
--split-by id \
--query "$excute_sql" \
--target-dir $tmp_partition
echo "load data inpath '$tmp_partition/$table_suff/*' into table $hdb.pl_$table partition(dt='"$partition"')"
#exit
if [ $? -eq 0 ];then
echo "数据mysql导入hive分区$year$month成功"
echo "$tmp_partition/$table/*"
hive -hiveconf hive.exec.parallel=true -e "use $hdb;alter table pl_$table add if not EXISTS partition(dt='"$partition"');
load data inpath '$tmp_partition/*' into table $hdb.pl_$table partition(dt='"$partition"');"
else
echo "$tmp_partition 分区下数据为空"
fi
(4)碰到的问题
- mysql数据导入hive有两种方式,第一种是基于全表,第二种是基于查询条件
//基于全表导入
/*
优点:方法简单
缺点:1.导入过程中不能做额外逻辑操作
2.导入到hdfs中目录结构为 /table/文件,导致hive外部表指定的location失效,解决方法可以使用中间临时存储区过度
3.关系型数据控中如果有特殊字符可能会导致hive表错列,因为hive建表时会执行行分隔符和列分隔符,当关系型数据库表字段内容含有已指定分隔符就会导致hive表错列
*/
sqoop import \
--connect jdbc:mysql://$server:$port/$mysql_database?tinyInt1isBit=false \
--username sqoop \
--password sqoop
--table ${table_suff} \
--warehouse-dir $tmp_partition
//基于查询SQL导入
优点:可以进行数据过滤转换等操作
缺点:暂时没发现啥缺点
sqoop import \
--connect jdbc:mysql://$server:$port/$mysql_database?tinyInt1isBit=false \
--username $username \
--password $password \
--split-by id \
--query "$excute_sql" \
--target-dir $tmp_partition
- 起初对数据探测不到位,导致对个贷部分表的部分字段内容包含的特殊字符了解不到位,比如换行符/制表符/#/逗号,导致我们导入到Hive中会错列
- mysql 数据类型tinyint转换至hive中为null 解决方法:tinyInt1isBit=false
- 原生sqoop只支持数据导入单分区,要支持多分区可以先把数据拉到hdfs多分区目录下(/database/table/year=2016/month=10/day=27/),再使用load命令加载数据
三、数据处理(hive/impala)
(1)数据仓库工具Hive
Hive建表
--放款合同信息表
CREATE EXTERNAL TABLE `pl_crm_account_mes_dk` (
`id` int,
`intopieces_id` int,
`by_name` string,
`is_by_name` string,
`by_id_card` string,
`addressee` string,
`mail_province` int,
`mail_city` int,
`mail_address` string,
`account_time` int,
`account_staff_id` int,)
PARTITIONED BY (
`dt` string COMMENT 'by date')
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs://hadb/rmdb/pl_crm_account_mes_dk';
数据加载
加overwrite 数据覆盖对应分区,不加overwrite 会追加数据到对应分区
--load data [local] inpath 'hdfs路径/本地文件路径' [overwrite] into 库名.表名 partition(分区名='对应分区')
注:这个操作是移动数据,而不是复制数据
注意问题:
- 数据存放的路径层次要和表的分区一致;
- 如果分区表没有新增分区,即使目标路径下己经有数据了,但依然查不到数据。
分隔符问题:
- 分隔符默认只有单个字符。如果有多个字符,默认取第一个字符作为分隔符。
数据类型对应问题:
- Load数据数据,字段类型不能互相转化时,查询结果返回NULL。而实际的数据仍然存在。
- Select查询插入,字段类型不能互相转化时,插入数据为NULL。而实际的数据也为NULL。
其他:
- Select查询插入数据,字段值顺序要与表中字段顺序一致,名称可不一致。
- Hive在数据加载时不做检查,查询时检查。
- 外部分区表需要添加分区才能看到数据。
hive 中 Order by, Sort by ,Dristribute by,Cluster By 的作用和对比
order by
按照某些字段排序
样例
select col1,other...
from table
where conditio
order by col1,col2 [asc|desc]
注意
order by后面可以有多列进行排序,默认按字典排序
order by为全局排序
order by需要reduce操作,且只有一个reduce,与配置无关。数据量很大时,慎用。
Sort排序
sort by col – 按照col列把数据排序
select col1,col2 from M
distribute by col1
sort by col1 asc,col2 desc
两者结合出现,确保每个reduce的输出都是有序的。
distribute by与group by对比
都是按key值划分数据
都使用reduce操作
唯一不同的是distribute by只是单纯的分散数据,而group by把相同key的数据聚集到一起,后续必须是聚合操作。
order by与sort by 对比
order by是全局排序
sort by只是确保每个reduce上面输出的数据有序。如果只有一个reduce时,和order by作用一样。
cluster by
把有相同值的数据聚集到一起,并排序。
效果等价于distribute by col sort by col
cluster by col <==> distribute by col sort by col
hive自定义函数
自定义函数介绍
当hive提供的函数不能满足我们的需求时,需要开发者自己开发自定义函数,自定义函数分为以下三类:
- [x] UDF(user defined function)
- 用户自定义函数针对单条记录,解决输入一行输出一行需求。
- 案例:根据用户访问日志获得客户端设备类型
public class UADeviceType {
public Text evaluate(Text url_text) {
if(null==url_text){
return new Text();
}
DeviceType dt = null;
try {
UserAgent userAgent = UserAgent.parseUserAgentString(url_text.toString());
dt = userAgent.getOperatingSystem().getDeviceType();
} catch (Exception e) {
e.printStackTrace();
}
return new Text(dt.getName());
}
public static void main(String[] args) {
UserAgent userAgent = UserAgent.parseUserAgentString("Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1");
System.out.println(userAgent.getOperatingSystem().getDeviceType().getName());
}
}
- [x] UDTF(User-Defined Table-Generating Functions)
- 用来解决 输入一行输出多行(On-to-many maping) 的需求。
- 案例:从日志表抽取优惠券券码生成优惠券明细表
hive --hiveconf mapreduce.job.queuename=root.offline.hdp_daojia.normal -v -e "use hdp_daojia_defaultdb;
insert overwrite table dj58_f_coupon partition(dt=$1)
select coupon_code,cookieid,urlfields['hmsr'],order_id,operation_status,mobile,urlfields['znsr']
from dj58_o_web lateral view explode(split(urlfields['code'],',')) adtable as coupon_code
where dt=$1;"
- [x] UDAF(user defined aggregation function)
- 用户自定义聚合函数针对记录集合,输入多行输出一行的需求
自定义函数开发流程(UDTF和UDAF)
- 自定义一个Java类
- 继承UDF类
- 重写evaluate方法
- 打成jar包
- 在hive执行add jar方法
- 在hive执行创建模板函数
- hql中使用
案例:
hive --hiveconf mapreduce.job.queuename=root.offline.hdp_daojia.normal -hiveconf hive.exec.parallel=true -v -e "
add jar hdfs://hdp-58-cluster/home/hdp_58dp/udf/udf-utils.jar;
create temporary function result_update as 'com.dj58.data.hive.udf.ResultsUpdate';
create temporary function spend_time as 'com.dj58.data.hive.udaf.SpendTime';
use hdp_daojia_defaultdb;
--$1 优惠券活动下单明细统计
select result_update('app_coupon/a_app_coupon_order.properties',
$1,hmsr,znsr,cateid,order_users,orders,finished_order_users,finished_orders,finished_order_price_sum,finished_corder_actual_price_sum)
from(
select (case when t2.hmsr!='' then t2.hmsr else 'none' end) hmsr,--渠道
(case when t2.znsr!='' then t2.znsr else 'none' end) znsr,--站内渠道
t1.cateid,--业务类型
count(distinct(case when t1.createtime='$2' and t2.operation_status = 'ordersuccess' then t1.uid end)) order_users,--渠道下单用户数
count(distinct(case when t1.createtime='$2' and t2.operation_status = 'ordersuccess' then t2.order_id end)) orders,--渠道下单数
count(distinct(case when t1.servicetime='$2' and t1.bistate in(3,8) then t1.uid end)) finished_order_users,--渠道完成订单用户数
count(distinct(case when t1.servicetime='$2' and t1.bistate in(3,8) then t1.orderid end)) finished_orders,--渠道完成订单数
sum((case when t1.bistate in(3,8) and t1.price is not null then t1.price else 0 end)) finished_order_price_sum, --渠道带来的完成订单的实收金额总和
sum((case when t1.bistate in(3,8) and t1.actual_price is not null then t1.actual_price else 0 end))finished_corder_actual_price_sum--渠道带来的完成订单实际金额加和
from(
select uid,orderid,bistate,price,actual_price,to_date(createtime) createtime,to_date(servicetime) servicetime,cateid
from hdp_daojia_defaultdb.dj58_f_mysql_order
where uid!='' and orderid!='' and to_date(createtime)='$2' or to_date(servicetime)='$2'
)t1
left outer join(
select hmsr,znsr,order_id,operation_status,mobile
from hdp_daojia_defaultdb.dj58_f_web_orderchannel
where order_id !=''
)t2
on t1.orderid = t2.order_id
group by t2.hmsr,t2.znsr,t1.cateid
order by order_users desc
)t5;
"
(2)开源的Apache Hadoop UI系统Hue
HUE的使用 B/S 代替C/S架构,不用频繁登陆 hive/hbase等客户端
Hue是一个可快速开发和调试Hadoop生态系统各种应用的一个基于浏览器的图形化用户接口。官网给出的特性,通过翻译原文简单了解一下Hue所支持的功能特性集合:
- 默认基于轻量级sqlite数据库管理会话数据,用户认证和授权,可以自定义为MySQL、Postgresql,以及Oracle
- 基于文件浏览器(File Browser)访问HDFS
- 基于Hive编辑器来开发和运行Hive查询
- 支持基于Solr进行搜索的应用,并提供可视化的数据视图,以及仪表板(Dashboard)
- 支持基于Impala的应用进行交互式查询


三、数据导出(sqoop)
hive导入mysql脚本
#下载HDFS文件到本地目录
hadoop fs -get $basedir/$hive_table/dt=$year-$month-$day/ $resultDir
#进入本地文件目录
cd $resultDir/dt=$year-$month-$day
pwd
#合并文件
cat ./* > data.txt
#exit
#加载数据至mysql数据库
mysql -u root -p123456 -h$server -e "use '$mysql_database';
delete from $mysql_table where data_dt='$year-$month-$day';
load data local infile '$resultDir/dt=$year-$month-$day/data.txt' into table $mysql_table FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n';"
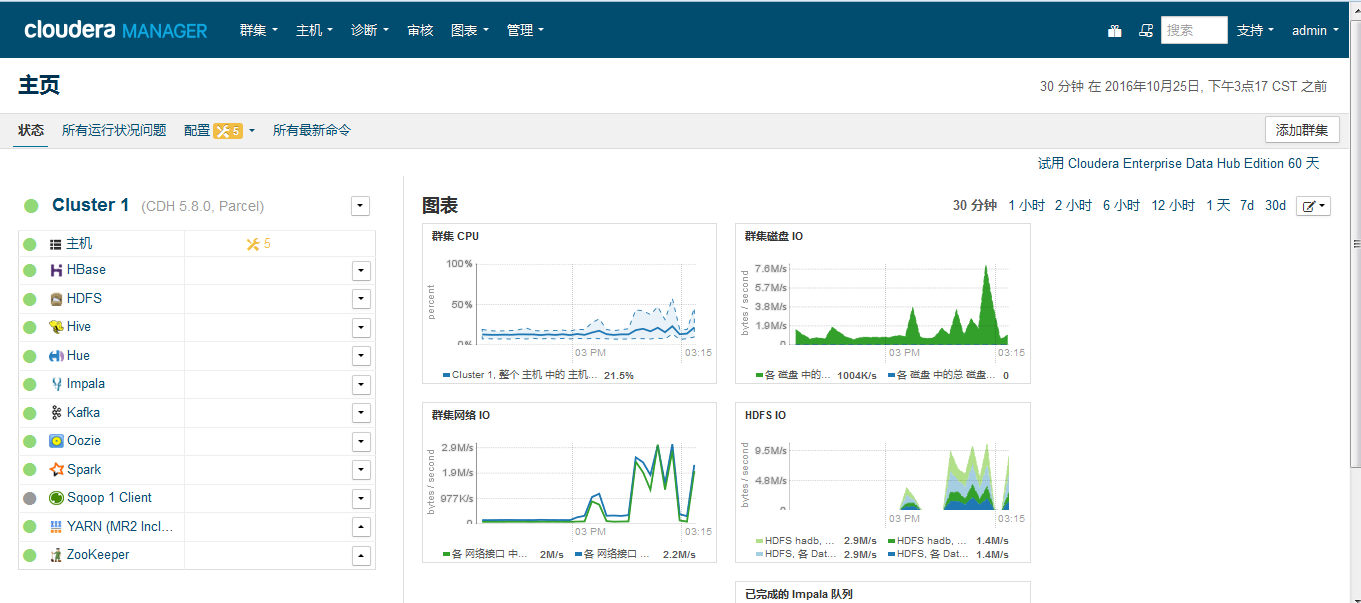
四、商业化hadoop平台CDH应用
hadoop是一个开源项目,所以很多公司在这个基础进行商业化,Cloudera对hadoop做了相应的改变
五、作业调度系统
基于 Linux 系统级别的 Crontab。
在 Job 数量庞大的情况下,Crontab 脚本的编写,变得异常复杂。其调度的过程也不能透明化,让管理变得困难。
Java 应用级别的 Quartz。
Quartz 虽然不用编写脚本,实现对应的调度 API 即可,然其调度过程不透明,不涵盖 Job 运行详情。需自行开发其功能。
第三方调度平台对比
Oozie
Oozie目前是托管在Apache基金会的,开源。配置的过程略显繁琐和复杂,配置相关的调度任务比较麻烦,然其可视化界面也不是那么的直观,另外,对UI界面要求较高的同学,此调度系统估计会让你失望。
Zeus
它是一个阿里巴巴开源Hadoop的作业平台,从Hadoop任务的调试运行到生产任务的周期调度,它支持任务的整个生命周期。从其功能来看,它支持以下任务:
- Hadoop的MapReduce任务调度运行
- Hive任务的调度运行
- Shell任务的运行
- Hive元数据的可视化展示查询及数据预览
- Hadoop任务的自动调度
Azkaban
Azkaban提供了一个易于使用的用户界面来维护和跟踪你的工作流程。另外,Github上贡献的Azkaban调度系统的源码量不大,做二次开发难度不大。其功能点涉及以下内容:
- 易用的Web UI
- 简单的Web和Http工作流的上传
- 项目工作区
- 工作流调度
- 模块化和插件化
- 认证和授权
- 用户行为跟踪
- 邮件告警失败和成功
- SLA告警
- 重启失败的Jobs
Azkaban使用
- [x] 主页面
https://localhost:8443
注意是https,采用的是jetty ssl链接。输入账号密码azkaban/azkanban(如果你之前没有更改的话)

首页有四个菜单
- projects:最重要的部分,创建一个工程,所有flows将在工程中运行。
- scheduling:显示定时任务
- executing:显示当前运行的任务
- history:显示历史运行任务
主要介绍projects部分
首先创建一个工程,填写名称和描述,比如o2olog。

Flows:工作流程,有多个job组成
Permissions:权限管理
Project Logs:工程日志
- 创建工程:
创建之前我们先了解下之间的关系,一个工程包含一个或多个flows,一个flow包含多个job。job是你想在azkaban中运行的一个进程,可以是简单的linux命令,可是java程序,也可以是复杂的shell脚本,当然,如果你安装相关插件,也可以运行插件。一个job可以依赖于另一个job,这种多个job和它们的依赖组成的图表叫做flow。
job创建
创建job很简单,只要创建一个以.job结尾的文本文件就行了,例如我们创建一个工作,用来将日志数据导入hive中(关于大数据方面的东西,不在重复,可以理解为,将日志所需数据导入的mysql中),我们创建o2o_2_hive.job
type=command
command=echo "data 2 hive"
一个简单的job就创建好了,解释下,type的command,告诉azkaban用unix原生命令去运行,比如原生命令或者shell脚本,当然也有其他类型,后面说。
一个工程不可能只有一个job,我们现在创建多个依赖job,这也是采用azkaban的首要目的。
2、Flows创建
我们说过多个jobs和它们的依赖组成flow。怎么创建依赖,只要指定dependencies参数就行了。比如导入hive前,需要进行数据清洗,数据清洗前需要上传,上传之前需要从ftp获取日志。
定义5个job:
- o2o_2_hive.job:将清洗完的数据入hive库
- o2o_clean_data.job:调用mr清洗hdfs数据
- o2o_up_2_hdfs.job:将文件上传至hdfs
- o2o_get_file_ftp1.job:从ftp1获取日志
- o2o_get_file_fip2.job:从ftp2获取日志
依赖关系:
3依赖4和5,2依赖3,1依赖2,4和5没有依赖关系。
o2o_2_hive.job
type=command
# 执行sh脚本,建议这样做,后期只需维护脚本就行了,azkaban定义工作流程
command=sh /job/o2o_2_hive.sh
dependencies=o2o_clean_data
o2o_clean_data.job
type=command
# 执行sh脚本,建议这样做,后期只需维护脚本就行了,azkaban定义工作流程
command=sh /job/o2o_clean_data.sh
dependencies=o2o_up_2_hdfs
o2o_up_2_hdfs.job
type=command
#需要配置好hadoop命令,建议编写到shell中,可以后期维护
command=hadoop fs -put /data/*
#多个依赖用逗号隔开
dependencies=o2o_get_file_ftp1,o2o_get_file_ftp2
o2o_get_file_ftp1.job
type=command
command=wget "ftp://file1" -O /data/file1
o2o_get_file_ftp2.job
type=command
command=wget "ftp:file2" -O /data/file2
- 将上述job打成zip包。上传:


点击o2o_2_hive进入流程,azkaban流程名称以最后一个没有依赖的job定义的。

右上方是配置执行当前流程或者执行定时流程。

Flow view:流程视图。可以禁用,启用某些job
Notification:定义任务成功或者失败是否发送邮件
Failure Options:定义一个job失败,剩下的job怎么执行
Concurrent:并行任务执行设置
Flow Parametters:参数设置。
1.执行一次
设置好上述参数,点击execute。

绿色代表成功,蓝色是运行,红色是失败。可以查看job运行时间,依赖和日志,点击details可以查看各个job运行情况。

2.定时执行

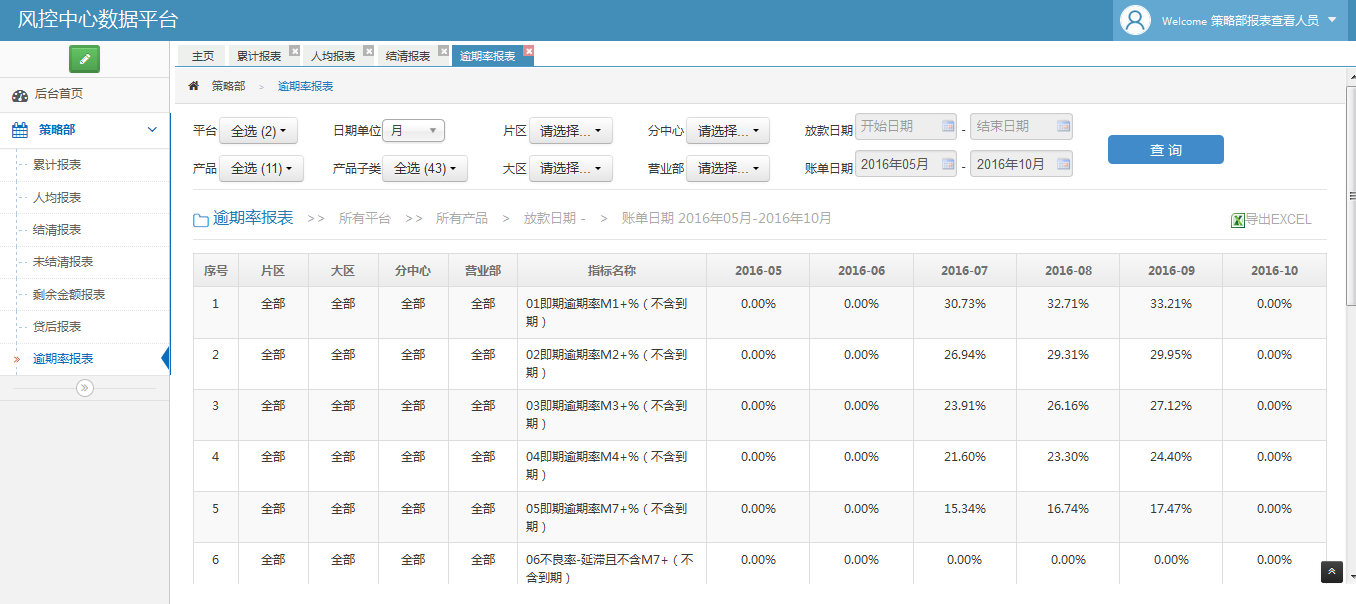
五、报表平台
参看文章:
Hive SQL编译过程:http://tech.meituan.com/hive-sql-to-mapreduce.html
Hadoop 新 MapReduce 框架 Yarn 详解:http://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-yarn/
Sqoop安装配置及演示:http://www.micmiu.com/bigdata/sqoop/sqoop-setup-and-demo/
Hue安装配置实践:http://shiyanjun.cn/archives/1002.html
Hadoop Hive sql语法详解:http://blog.csdn.net/hguisu/article/details/7256833
Azkaban-开源任务调度程序(安装篇):http://www.jianshu.com/p/cc680380ca34
Azkaban-开源任务调度程序(使用篇):http://www.jianshu.com/p/484564beda1d
Hive高级查询(group by、 order by、 join等) :http://blog.csdn.net/scgaliguodong123_/article/details/46944519
