一句话概括本文:
爬取我主良缘交友所有的妹子信息,利用Jupyter Notebook对五个方面:
身高,学历,年龄,城市和交友宣言进行分析,并把分析结果通过pyecharts
进行数据可视化。
引言:

本节应该是Python数据分析入门的最后一节了,数据分析的水可是深的很:
大数据处理,机器学习,深度学习,NLP等,当前能够抓下数据,用好
pandas,numpy和matplotlib基础三件套,完成数据可视化就够了。
上节分析拉勾网的Android招聘数据,没什么特别的感觉,我觉得
可能是数据太少了,加起来也就700来条。还有Jupyter Notebook
和pyecharts没有去试试,有点美中不足,于是乎我又想着抓点
什么分析分析。一天早上,日常出地铁,电视上依旧无脑放着这样
的广告:我主良缘的公众号,可以在线找对象的公众号...
坐过深圳地铁的应该不会陌生...突然灵光一闪,要不抓一波
我主良缘,分析分析都是些怎么样的妹子在找对象?
有idea了,接着就是看下抓数据的难度了,回公司直接打开
官网,点开交友页:
http://www.lovewzly.com/jiaoyou.html

F12打开抓包,大概看了抓取的难度不大,接着就开始爬数据环节啦~
1.数据抓取
列表滚动到底部加载更多,猜测是Ajax动态加载数据,直接拦截XHR
有点明显,随手点开一个:

哟,直接就是我们想要的数据了,接着研究下请求规律。
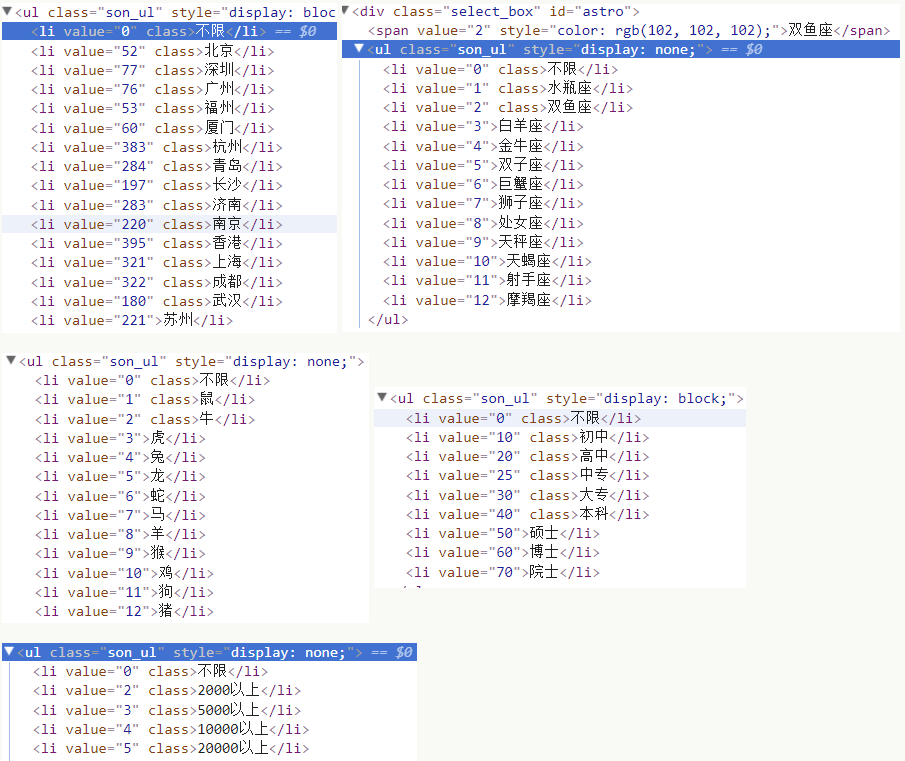
筛选条件都勾上,获取一波所有的参数,然后再自行搭配。

抓包看下参数:
| 字段 | 值 | 含义 |
|---|---|---|
| startage | 21 | 起始年龄 |
| endage | 30 | 截止年龄 |
| gender | 2 | 性别,1代表男,2代表女 |
| cityid | 52 | 城市id,这个通过查看页面结构可以获取热门的几个城市id |
| startheight | 161 | 起始身高 |
| endheight | 170 | 截止身高 |
| marry | 1 | 结婚状态,1未婚,3离异,4丧偶 |
| astro | 2 | 星座,看下表 |
| lunar | 2 | 生肖,看下表 |
| education | 40 | 教育水平,看下表 |
| salary | 2 | 收入,看下表 |
| page | 1 | 页数,一页20条数据 |
抓的链接是:http://www.lovewzly.com/api/user/pc/list/search?
接着就是请求头模拟了:
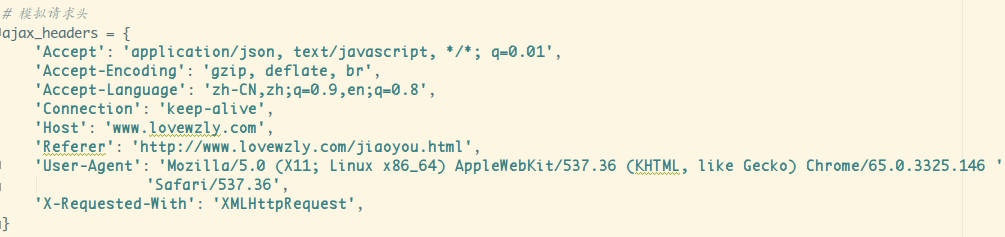
然后呢,我想抓所有未婚的妹子的信息,查询参数如下:

看下返回的Json,能拿到的参数如下:
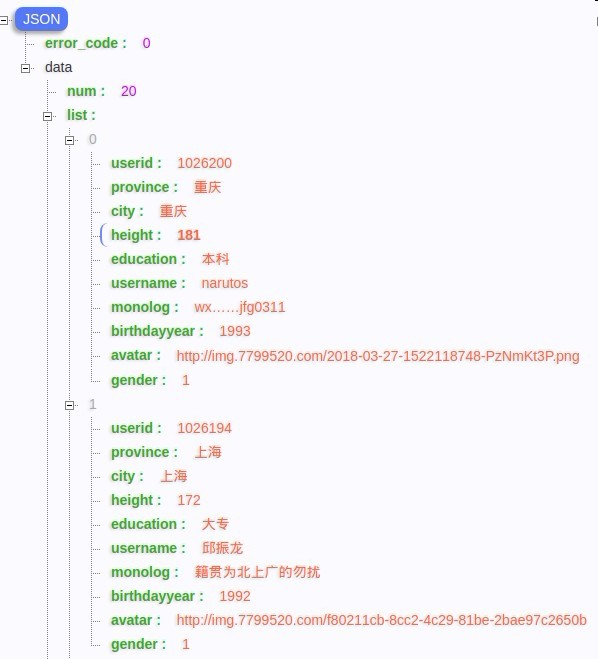
字段有:
头像,出生年份,省份,性别, 学历,身高,交友宣言,城市,用户id,昵称
东西都齐了,接着就是把爬到的数据写到csv里了,不难写出这样的代码:
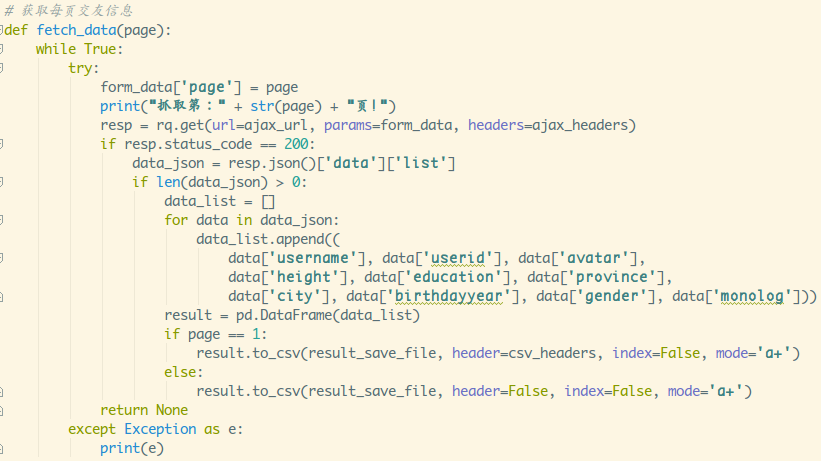
没用代理,这里依旧是随缘休眠,避免访问过于频繁ip被封,
接着挂着就好,大概要爬1.3个小时(没有好的代理ip,不用多进程就这样~)
抓取成功后的数据:

总共有15521条数据,可以,很nice,接着开始胡乱分析环节。
2.安装Jupyter Notebook与pyecharts
在开始数据分析前,我们另外安装两个东西:
Jupyter Notebook:一个非常适合做数据分析的工具,可以在上面写
代码,运行代码,写文档,做数据可视化展示。举个例子:
在Pycharm上写代码,matplotlib绘制的图形要么通过plt.show()展示出来
要么保存为一个图片文件,然后你要看的时候把图片文件打开。
而使用Jupyter直接就可以看到,配合支持文档编写,你都不需要报告了,
利用可以直接运行的特点,很多人都拿来直接写Python教程,非常方便。
安装也很简单,直接通过pip命令安装即可。
pip install jupyter notebook
安装完成后,命令行键入:jupyter notebook 会自动打开一个网页
点击New,选择一个内核,比如Python3,然后会新建一个ipynb后缀的文件,
点开会出现下面的页面:
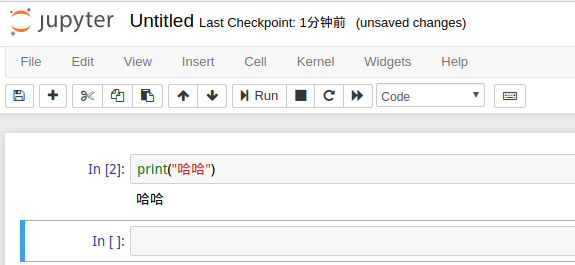
页面比较简单,自己点开摸索摸索吧,加号是新建一个单元格,
剪刀图标是删除单元格,接着是复制粘贴单元格,单元格上下移,
运行,终止。Code那里下拉可以选择单元格编写的内容;
运行的快捷键是:shift + enter,大概就这些,更多可见下述视频教程:
Jupyter Notebook Tutorial: Introduction, Setup, and Walkthrough
再接着是安装pyecharts,这是一个用于生成Echarts图表的类库,
Echarts是百度开源的一个数据可视化JS 库。用Echarts生成的图可视化
效果非常棒,pyecharts是为了与 Python 进行对接,方便在Python中直接
使用数据生成图,生成结果是一个html文件,用浏览器打开即可看到效果。
相关文档:
安装方法同样也很简单,直接pip走一波:
pip install pyecharts
安装完之后,直接编写代码绘制地图,地图区域是无法显示,你需要
另外安装地图文件:

pip install echarts-countries-pypkg
pip install echarts-china-provinces-pypkg
pip install echarts-china-cities-pypkg
特别注明,中国地图在 echarts-countries-pypkg 里。
一般安装第一个就够了,其他看自己吧。
到此就准备好了,接下来开始编码进行数据分析~
3.开始数据分析
这里我们直接在Jupyter写代码进行数据分析,命令行键入: jupyter notebook
打开,然后来到我们的目录下,新建一个WZLY.ipynb的文件,进入后就可以
开始编写代码了。
1.读取CSV文件里的数据

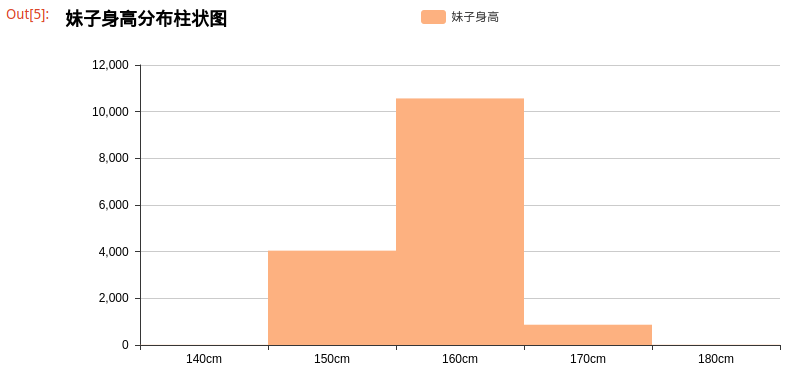
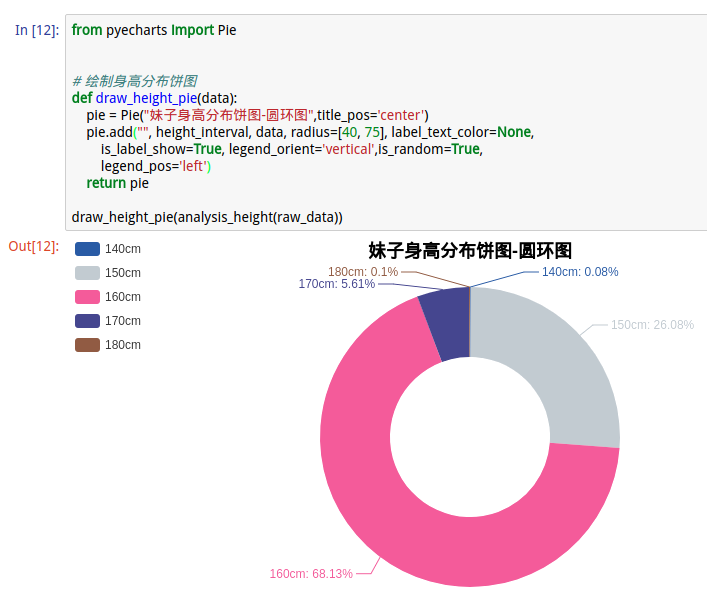
2.分析身高

运行结果:

3.分析学历

结果分析

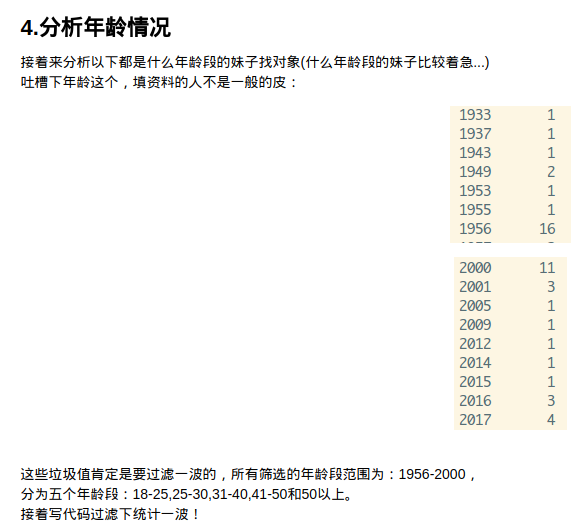
4.分析年龄
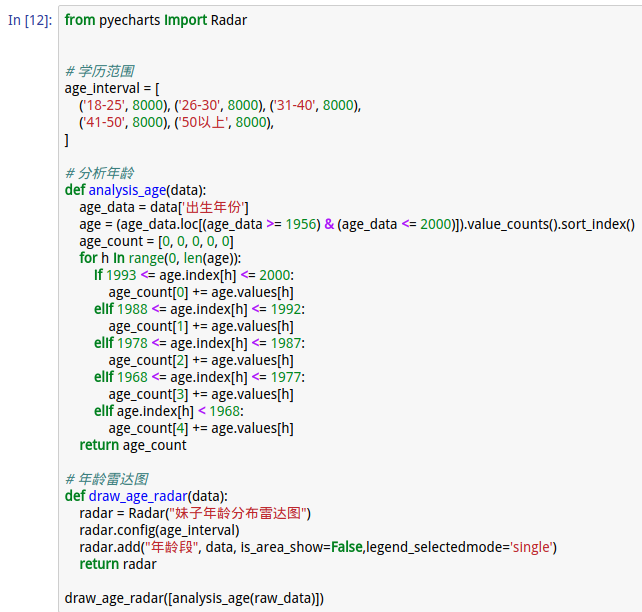
运行结果:

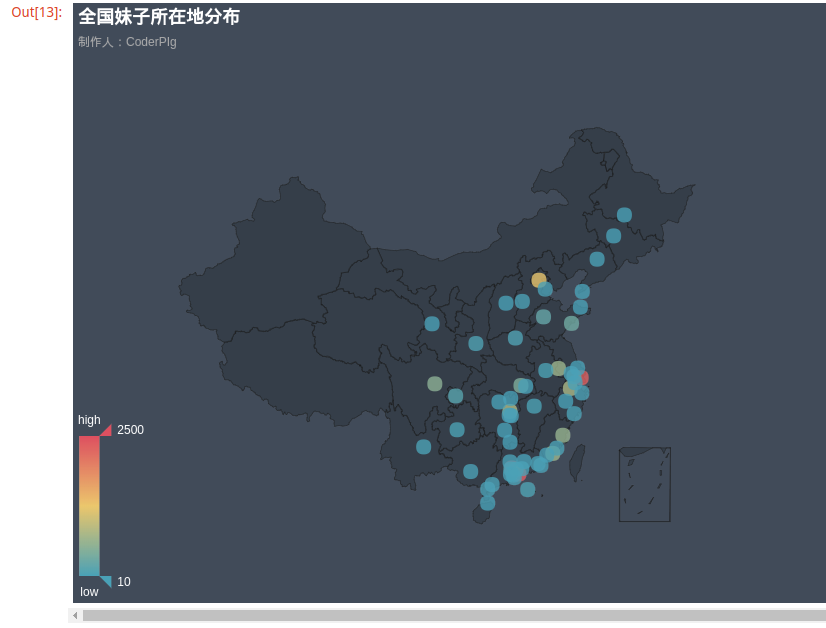
5.分析城市

运行结果:

6.分析交友宣言

输出结果


小结
以上就是对通过爬虫采集到的我主良缘妹子交友信息进行的简单的数据分析,
主要目的还是试试Jupyter Notebook和pyechars这两个东东,结果还是没
分析出什么特别有用的东西,分析完大概知道了这样一些信息:
- 1.妹子身高:集中在150-170cm之间,达到了94.21%的占比;
- 2.妹子学历:本科和大专是主力军;
- 3.妹子年龄:26-30岁的最多,18-25次之,31-40岁的大龄剩女也挺多的;
- 4.妹子城市分布:大部分还是集中在北深上广,其次杭州,南京,厦门,福州,成都,武汉,青岛;
- 5.妹子中意的对象特点:前八依次是责任心,上进心,事业心,热爱生活,性格开朗,脾气好,孝顺父母,安全感
好吧,关于Python做数据分析就到这里了,数据分析是一个方向,但是目前不会深究:
行业大数据 + 机器学习框架 + 深度学习算法 => 人工智能
so,不用我说什么了,后面能有适合的环境,有这样的机会研究这些东西,
再续写相关的文章吧。后面的文章会写回Python爬虫,多进程,分布式爬虫,
爬虫与反爬虫的策略研究,学习Redis,Mongodb,MySQL,Flask写个自己
APP使用的API,Django,弄自己的网站等等,敬请期待~

附:最终代码(都可以在:https://github.com/coder-pig/ReptileSomething 找到):

import requests as rq
import config as c
import tools as t
import pandas as pd
import numpy as np
import time
import random
import sys
from pyecharts import Bar, Pie, Funnel, Radar, Geo, WordCloud
import jieba as jb
import re
from collections import Counter
result_save_file = c.outputs_logs_path + 'wzly.csv'
# Ajax加载url
ajax_url = "http://www.lovewzly.com/api/user/pc/list/search?"
# 模拟请求头
ajax_headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'Connection': 'keep-alive',
'Host': 'www.lovewzly.com',
'Referer': 'http://www.lovewzly.com/jiaoyou.html',
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 '
'Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
}
# post请求参数
form_data = {'gender': '2', 'marry': '1', 'page': '1'}
# csv表头
csv_headers = [
'昵称', '用户id', '头像', '身高', '学历', '省份',
'城市', '出生年份', '性别', '交友宣言'
]
height_interval = ['140', '150', '160', '170', '180'] # 身高范围
edu_interval = ['本科', '大专', '高中', '中专', '初中', '硕士', '博士', '院士'] # 学历范围
age_interval = [
('18-30', 8000), ('26-30', 8000), ('31-40', 8000),
('41-50', 8000), ('50以上', 8000),
] # 学历范围
word_pattern = re.compile('[\s+\.\!\/_,$%^*(+\"\']+|[+——!,。?“”、~@#¥%……&*()(\d+)]+')
# 获取每页交友信息
def fetch_data(page):
while True:
try:
form_data['page'] = page
print("抓取第:" + str(page) + "页!")
resp = rq.get(url=ajax_url, params=form_data, headers=ajax_headers)
if resp.status_code == 200:
data_json = resp.json()['data']['list']
if len(data_json) > 0:
data_list = []
for data in data_json:
data_list.append((
data['username'], data['userid'], data['avatar'],
data['height'], data['education'], data['province'],
data['city'], data['birthdayyear'], data['gender'], data['monolog']))
result = pd.DataFrame(data_list)
if page == 1:
result.to_csv(result_save_file, header=csv_headers, index=False, mode='a+')
else:
result.to_csv(result_save_file, header=False, index=False, mode='a+')
return None
except Exception as e:
print(e)
# 分析身高
def analysis_height(data):
height_data = data['身高']
height = (height_data.loc[(height_data > 140) & (height_data < 200)]).value_counts().sort_index()
height_count = [0, 0, 0, 0, 0]
for h in range(0, len(height)):
if 140 <= height.index[h] < 150:
height_count[0] += height.values[h]
elif 150 <= height.index[h] < 160:
height_count[1] += height.values[h]
elif 160 <= height.index[h] < 170:
height_count[2] += height.values[h]
elif 170 <= height.index[h] < 180:
height_count[3] += height.values[h]
elif 180 <= height.index[h] < 190:
height_count[4] += height.values[h]
return height_count
# 分析学历
def analysis_edu(data):
return data['学历'].value_counts()
# 分析年龄
def analysis_age(data):
age_data = data['出生年份']
age = (age_data.loc[(age_data >= 1956) & (age_data <= 2000)]).value_counts().sort_index()
age_count = [0, 0, 0, 0, 0]
for h in range(0, len(age)):
if 1993 <= age.index[h] <= 2000:
age_count[0] += age.values[h]
elif 1988 <= age.index[h] <= 1992:
age_count[1] += age.values[h]
elif 1978 <= age.index[h] <= 1987:
age_count[2] += age.values[h]
elif 1968 <= age.index[h] <= 1977:
age_count[3] += age.values[h]
elif age.index[h] < 1968:
age_count[4] += age.values[h]
return age_count
# 分析城市分布
def analysis_city(data):
city_data = data['城市'].value_counts()
city_list = []
for city in range(0, len(city_data)):
if city_data.values[city] > 10:
city_list.append((city_data.index[city], city_data.values[city]))
return city_list
# 词频分布
def analysis_word(data):
word_data = data['交友宣言'].value_counts()
word_list = []
for word in range(0, len(word_data)):
if word_data.values[word] == 1:
word_list.append(word_data.index[word])
return word_list
# 绘制身高分布柱状图
def draw_height_bar(data):
bar = Bar("妹子身高分布柱状图")
bar.add("妹子身高", height_interval, data, bar_category_gap=0, is_random=True, )
return bar
# 绘制身高分布饼图
def draw_height_pie(data):
pie = Pie("妹子身高分布饼图-圆环图", title_pos='center')
pie.add("", height_interval, data, radius=[40, 75], label_text_color=None,
is_label_show=True, legend_orient='vertical', is_random=True,
legend_pos='left')
return pie
# 学历漏斗图
def draw_edu_funnel(data):
funnel = Funnel("妹子学历分布漏斗图")
funnel.add("学历", edu_interval, data, is_label_show=True,
label_pos="inside", label_text_color="#fff", title_top=50)
return funnel
# 年龄雷达图
def draw_age_radar(data):
radar = Radar("妹子年龄分布雷达图")
radar.config(age_interval)
radar.add("年龄段", data, is_splitline=True, is_axisline_show=True)
return radar
# 城市分布地图
def draw_city_geo(data):
geo = Geo("全国妹子分布城市", "data about beauty", title_color="#fff",
title_pos="center", width=1200,
height=600, background_color='#404a59')
attr, value = geo.cast(data)
geo.add("", attr, value, visual_range=[10, 2500], visual_text_color="#fff",
symbol_size=15, is_visualmap=True)
return geo
# 交友宣言词云
def draw_word_wc(name, count):
wc = WordCloud(width=1300, height=620)
wc.add("", name, count, word_size_range=[20, 100], shape='diamond')
wc.render()
if __name__ == '__main__':
if not t.is_dir_existed(result_save_file, mkdir=False):
for i in range(1, 777):
time.sleep(random.randint(2, 10))
fetch_data(i)
else:
raw_data = pd.read_csv(result_save_file)
word_result = word_pattern.sub("", ''.join(analysis_word(raw_data)))
words = [word for word in jb.cut(word_result, cut_all=False) if len(word) >= 3]
exclude_words = [
'一辈子', '不相离', '另一半', '业余时间', '性格特点', '茫茫人海', '男朋友', '找对象',
'谈恋爱', '有时候', '女孩子', '哈哈哈', '加微信', '兴趣爱好',
'是因为', '不良嗜好', '男孩子', '为什么', '没关系', '不介意',
'没什么', '交朋友', '大大咧咧', '大富大贵', '联系方式', '打招呼',
'有意者', '晚一点', '哈哈哈', '以上学历', '是不是', '给我发',
'不怎么', '第一次', '越来越', '遇一人', '择一人', '无数次',
'符合条件', '什么样', '全世界', '比较简单', '浪费时间', '不知不觉',
'有没有', '寻寻觅觅', '自我介绍', '请勿打扰', '差不多', '不在乎', '看起来',
'一点点', '陪你到', '这么久', '看清楚', '身高体重', '比较慢', '比较忙',
'多一点', '小女生', '土生土长', '发消息', '最合适'
]
for i in range(0, len(words)):
if words[i] in exclude_words:
words[i] = None
filter_list = list(filter(lambda t: t is not None, words))
data = r' '.join(filter_list)
c = Counter(filter_list)
word_name = [] # 词
word_count = [] # 词频
for word_freq in c.most_common(100):
word, freq = word_freq
word_name.append(word)
word_count.append(freq)
draw_word_wc(word_name, word_count)
来啊,Py交易啊
想加群一起学习Py的可以加下,智障机器人小Pig,验证信息里包含:
Python,python,py,Py,加群,交易,屁眼 中的一个关键词即可通过;

验证通过后回复 加群 即可获得加群链接(不要把机器人玩坏了!!!)~~~
欢迎各种像我一样的Py初学者,Py大神加入,一起愉快地交流学♂习,van♂转py。

