〇、前言
本文共108张图,流量党请慎重!
历时1个半月,我把自己学习Python基础知识的框架详细梳理了一遍。
一方面,我坚信实践总是记得牢一些,总结每一个知识点的时候我要参考非常多的资料,包括但不仅限于视频资料、大牛博客、问题交流贴、经验分享帖等。因此,首先我借鉴了许多前人、大牛的宝贵知识,有些我认为讲解非常到位的地方也直接照搬过来了,如果我借鉴的地方给原创带来了不便,请随时联系我,我将再做修改。我的参考资料已展示在本文文末。
另一方面,人的记忆是有一定周期的,许多现在自认为学的不错、掌握很牢的点,或许下个月就稍显生疏了。因此,便于我日后自己查阅,我按照自己的思路整理了一份主要供自己参考的“资料”。
本文的举例多以截图给出,这些例子都是在Jupyter Notebook中编辑而成的,在编辑过程中,我深感方便,因此也推荐给有需要的人可以进行尝试。
有关Jupyter Notebook的安装和使用,可以移步我的另一篇文章:Jupyter Notebook介绍、安装及使用教程
说到Jupyter Notebook,就不得不提Anaconda,一个可以便捷获取Python的包且对包能够进行管理,同时对环境可以统一管理的发行版本。大多数Python的包都以被安装,而且可以创建不同的环境以便在Python 2.x版本和Python 3.x版本之间切换使用。而且,Jupyter Notebook已经包含在Anaconda之中。如想了解更多Anaconda相关的内容,请移步我的另一篇文章:Anaconda介绍、安装及使用教程
本文的结构主要分为五个部分:
- 第一部分:Python代码规范、基本数据类型和流程控制语句
- 第二部分:函数
- 第三部分:模块
- 第四部分:面向对象和类
- 第五部分:参考资料
但愿我在自助的同时,也能帮助到你!
一、Python代码规范
0. 前言
Python代码规范请以官方文档为准,本部分的代码规范是结合Python官方文档并延袭学习时朱老师的代码习惯总结而成,仅供参考。
1. 换行
① 行长度
1行代码量不能超过80个字符。
② 特殊情况
长的导入模块语句。
注释里的URL。
③ 超过行长度限制的处理方法
⑴ 条件表达式
Python会将 圆括号, 中括号和花括号中的行隐式的连接起来。用英文半角小括号“()”括起来,在逻辑运算符前面换行。
例如:
【原代码】
if (1 < a < 10 and 2 < b < 10 and 3 < c < 10) or a > 10 or a <= 30
【修改】
if((1 < a < 10
and 2 < b < 10
and 3 < c < 10)
or a > 10
or a <= 30)
⑵ 字符串
Python会将 圆括号, 中括号和花括号中的行隐式的连接起来。用英文半角小括号“()”括起来换行。不要使用反斜杠连接行。
例如:
【原句】
string = 'If you wish to succeed, you should use persistence as your good friend, experience as your reference, prudence as your brother and hope as your sentry.'
【修改】
string = ('If you wish to succeed, you should use persistence as your good friend,'
' experience as your reference, prudence as your brother and hope as your sentry.')
⑶ 函数参数
在逗号后面折行。
例如:
【原函数】
def test(name, age, gender, hobby, specialization, city, province, country=China):
pass
【修改】
def test(name, age, gender, hobby, specialization,
city, province, country=China):
pass
⑷ 三目运算符
三目运算符又称三元运算符,可以将简单的 if 条件语句改写成1行代码,但是,如果三目运算符代码超过80个字符,则仍需使用 if 语句。
【if语句】
if a > 10:
b = 1
else:
b = 0
【三目运算符】
b = 1 if a > 10 else 0
2. 缩进
① 缩进的优点
缩进使代码具有层次感。
Python的语法要求。对于流程控制语句,语句体必须缩进,否则将不视为流程控制语句的一部分;函数中,函数名顶格,函数体必须缩进;类中,类名顶格,主体代码块必须缩进。如不遵循该原则,代码运行时会抛出异常。
② 缩进要求
官方建议,缩进采用4个空格,建议不要使用“tab”键,因为不同IDE对“tab”键空格个数的设置是不同的,但对空格的显示逻辑是相同的。
3. 空行
① 作用
使代码具有段落感,便于阅读。
② 空行的使用建议
⑴ import
import 上下各加1个空行。若连续导入模块,则在第一条 import 前空1行,最后一条 import 后空1行。
⑵ 函数
函数下面加2个空行。
⑶ 方法
类的每个方法下面加1个空行。
⑷ 流程控制语句
流程控制语句上下各加1个空行。
⑸ 变量定义
变量定义之间建议加1个空行。若变量之间有关系,则其间不加空行。
4. 空格
① 作用
使代码更清晰,便于阅读。
② 加空格的规则
⑴ 二元运算符:二元运算符两边加1个空格。包括:赋值(=),比较(==, <, >, !=, <>, <=, >=, in, not in, is, is not)和布尔或逻辑运算符(and, or, not)。例如:a + 34 >= (b + 34) * 3
⑵ 逗号:逗号后面必须加1个空格。
⑶ 括号:前括号“(”和后括号“)”前面不加空格。
⑷ 函数:函数参数赋值的等号两边不加空格。
5. 注释
① 定义
注释的内容在Python执行代码时是不予执行的。注释是便于代码维护、写给代码使用者看的说明性文字。
② 注释符号
⑴ 类和函数的说明文字
类和函数的说明文字位于类名或函数名下一行,有4个空格的缩进,用一对三个英文半角双引号 或 一对三个英文半角单引号 引起,若内容简短,可位于文字两边;若内容较长,可位于文字上下行。
例如:
【类】
class Test(object):
"""
这是Test类的说明文字。
注释符号是一对三个英文半角双引号。
注释符号位于说明文字上下行。
"""
pass
【函数】
def test():
'''这是test函数的说明文字'''
pass
⑵ 行注释
行注释用井号“#”起头,井号“#”后的文字,均为注释内容,Python不会执行该处文字或代码。
通常情况下写在被注释代码所在行的上一行。
只有当注释内容为1个单词或少数内容时才在被注释行后边进行注释。注意,在代码后边的行注释与该行代码有至少2个空格的间距,且各行注释不要对齐,因为会造成维护负担。
6. 命名规范
① 优点
提高代码可读性。
② 变量命名规范
⑴ 英文变量名严格区分大小写,通常以英文小写命名变量,以英文大写命名常量。
⑵ 变量名不能是纯数字或特殊符号(英文半角下划线“_”除外,下同),也不能以数字或特殊符号开头的组合,特殊符号不能以任何形式作为变量名。错误举例:1a = 6, a$ = 6, $a = 6
⑶ 不建议使用中文作为变量。一方面不利于代码国际化;另一方面可能存在字符编码问题。如果运行平台不是支持“utf-8”,则会出错。
⑷ 不能与Python关键词同名。例如:False = 6, True = 6, and = 6, or = 6。
- 查看Python关键词:
【输入】
import keyword
print(keyword.kwlist)
【输出】
['False', 'None', 'True', 'and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
- 命名建议:变量的命名要考虑变量的用途,尽量以存放的内容来命名变量。例如:存放年龄的变量使用“age”,存放姓名的变量使用“name”。
③ 其他命名规范
⑴ 函数名通常为英文小写单词。
⑵ 类名通常为首字母大写的英文单词。
7. 其他
如果在编程中有同一条代码重复出现,或者有高度相似的情况,则需要考虑合并代码进行优化。目的是为了方便日后代码的维护和扩展。
二、基本数据类型
1. 基本数据类型
Python 3的标准数据类型有6个:
- 数字:Number
- 字符串:String
- 列表:List
- 元组:Tuple
- 集合:Sets
- 字典:Dictionary
2. 基本数据类型——数字(Number)
① 数字类型
| 数字类型 | 英文表示 | 分类 |
|---|---|---|
| 整型 | int | 正数,负数 |
| 浮点型 | float | |
| 布尔型 | bool | |
| 复数 | complex |
例如:
② 进制转换
⑴ Python的进制表示形式
| 进制 | 表示形式举例 |
|---|---|
| 二进制 | 0b000000 |
| 八进制 | 0o345 |
| 十进制 | 145 |
| 十六进制 | 0xa3f |
⑵ 16以下数字二进制
| 十六进制 | 二进制 |
|---|---|
| 0 | 0000 |
| 1 | 0001 |
| 2 | 0010 |
| 3 | 0011 |
| 4 | 0100 |
| 5 | 0101 |
| 6 | 0110 |
| 7 | 0111 |
| 8 | 1000 |
| 9 | 1001 |
| a | 1010 |
| b | 1011 |
| c | 1100 |
| d | 1101 |
| e | 1110 |
| f | 1111 |
⑶ 相关内置函数
| 函数 | 作用 | 返回值类型 |
|---|---|---|
| int() | 将任意进制转化成十进制 | 返回整型 |
| bin() | 将任意进制转化成二进制 | 返回字符串 |
| oct() | 将任意进制转化成八进制 | 返回字符串 |
| hex() | 将任意进制转化成十六进制 | 返回字符串 |
| abs() | 求绝对值 | 返回整型 |
| pow(底数, 指数) | 取幂 | 返回整型 |
| float() | 转换浮点数 | 返回浮点型 |
| round(数字, 位数) | 四舍五入 | 返回浮点型 |
| sum() | 求和 | 返回整型 |
| min() | 最小值 | 返回整型 |
| max() | 最大值 | 返回整型 |
例如:

③ 操作符
⑴ 算术操作符
| 符号 | 含义 |
|---|---|
| + | 加 |
| - | 减 |
| * | 乘 |
| / | 除 |
| % | 取模 |
| // | 整除 |
| ** | 取幂 |
⑵ 比较操作符
| 符号 | 含义 |
|---|---|
| > | 大于 |
| >= | 大于等于 |
| < | 小于 |
| <= | 小于等于 |
| == | 等于 |
| != | 不等于 |
- 注意:
==对比的是值,is对比的是地址。
⑶ 赋值操作符
赋值操作符:=
⑷ 增强赋值操作符
| 符号 | 含义 | 举例 |
|---|---|---|
| += | 加后赋值 | a+=b → a=a+b |
| -= | 减后赋值 | a-=b → a=a-b |
| *= | 乘后赋值 | a*=b → a=a*b |
| /= | 除后赋值 | a/=b → a=a/b |
| %= | 模后赋值 | a%=b → a=a%b |
| **= | 取幂后赋值 | a**=b → a=ab |
| //= | 整除后赋值 | a//b → a=a//b |
| &= | 按位与后赋值 | |
| = | 按位或后赋值 | |
| ^= | 按位异或后赋值 | |
| <<= | 左移后赋值 | |
| >>= | 右移后赋值 |
⑸ 逻辑操作符
and
or
not
⑹ 位操作符
| 符号 | 含义 | 举例 |
|---|---|---|
| & | 按位与 | 两个位都为1时,结果才为1 |
| | | 按位或 | 两个位都为0时,结果才为0 |
| ^ | 按位异或 | 两个位相同为0,相异为1 |
| << | 按位左移位 | 各二进位全部左移若干位,高位丢弃,低位补0 |
| >> | 按位右移位 | 各二进位全部右移若干位,对无符号数,高位补0,有符号数,各编译器处理方法不一样,有的补符号位(算术右移),有的补0(逻辑右移) |
| ~ | 按位取反 | 0变1,1变0 |
- 注意:仅对数字操作。
⑺ 成员操作符
in
not in
⑻ 身份操作符
is
is not
注意:
==对比的是值,is对比的是地址。
⑼ 运算符运算次序
在程序设计语言中,各类运算符的运算次序是:
括号 → 函数 → 算术运算 → 关系运算 → 逻辑运算
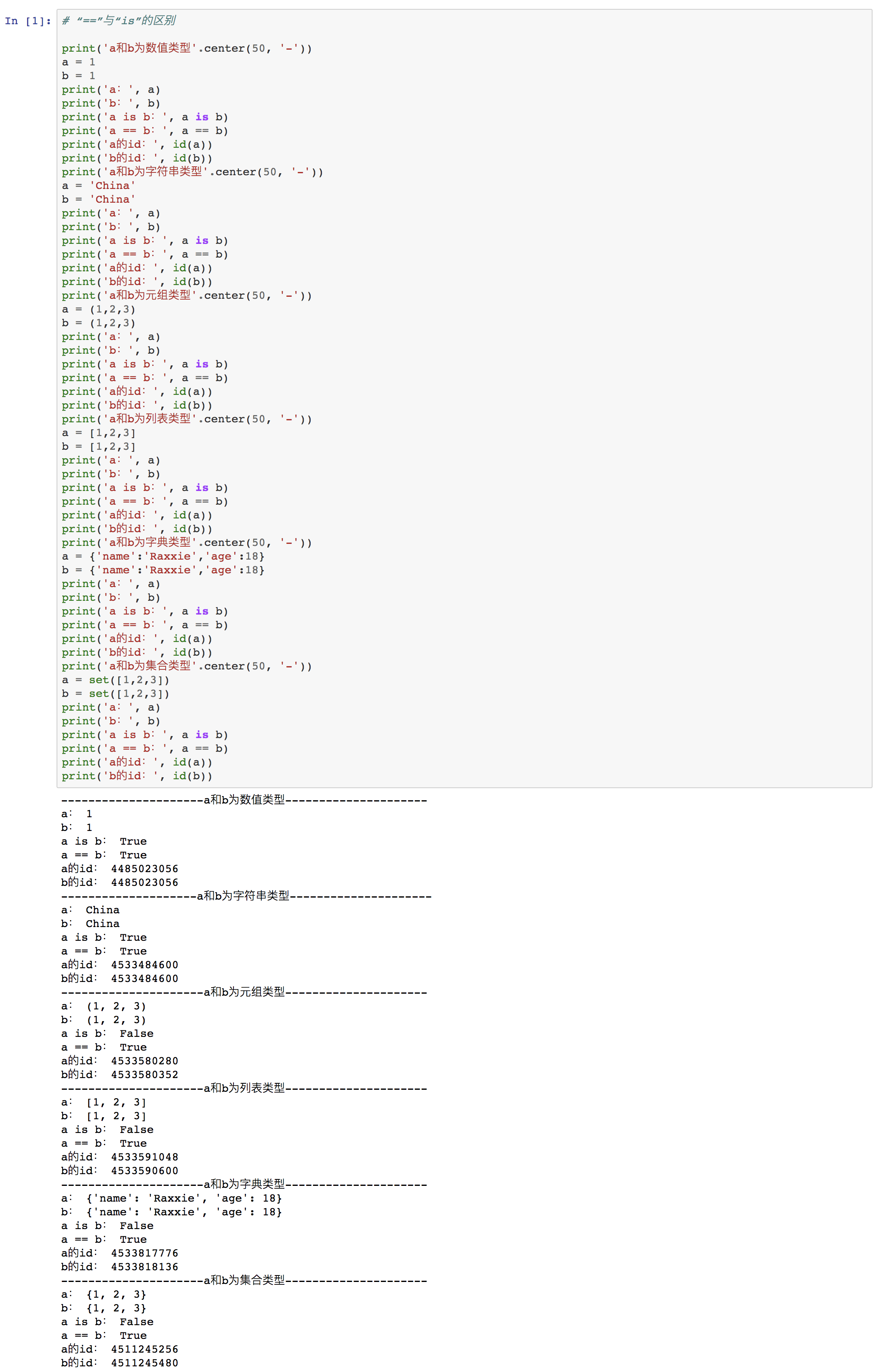
⑽ “==” 与 “is” 的区别
对象包含的三个基本要素
- id:身份标识
- type:数据类型
- value:值
区别
==:Python标准操作符中的比较操作符,用来比较判断两个对象的value(值)是否相等。is:Python中的身份操作符,也叫同一性运算符。用于比较判断对象间的唯一id(身份标识)是否相同。
结论
- 判断a和b,只有数值型和字符串型的情况下,
a is b才为True;当a和b是元组(tuple),列表(list),字典(dict)或 集合(set)型时,a is b为False。
举例
④ 浮点型数字的注意事项
浮点数不能与0直接比,不精确。
如果浮点数与0比较,需要界定范围之后,再进行比较。
如果浮点数与0比较,可以将其转成整型,再进行比较。
⑤ Python的数学函数库
import math
⑥ 数字储存
⑴ 数字存储原理
- 储存单位:字节(Byte)(最小单元)
- 1个字节(Byte) = 8个位(bit)
⑵ 原码和补码
-
原码:原码就是符号位加上真值的绝对值, 即用第一位表示符号, 其余位表示值。
- 例如:
[+1]原 = 0000 0001 [-1]原 = 1000 0001 -
反码:正数的反码是其本身;负数的反码是在其原码的基础上, 符号位不变,其余各个位取反。
- 例如:
[+1] = [0000 0001]原 = [0000 0001]反 [-1] = [1000 0001]原 = [1111 1110]反 -
补码:正数的补码就是其本身;负数的补码是在其原码的基础上, 符号位不变, 其余各位取反, 最后+1。
- 例如:
[+1] = [0000 0001]原 = [0000 0001]反 = [0000 0001]补 [-1] = [1000 0001]原 = [1111 1110]反 = [1111 1111]补
⑶ 整型正负号在二进制中的表示
- 整型中正负在二进制表示使用最高位来描述。其中,0代表正数,1代表负数。
- 正数的存储使用原码(正数的补码即是其原码本身)。
- 负数的存储使用补码。
⑷ 变量所占二进制位数
变量.bit_length()
⑸ 变量所占内存
变量.__sizeof__()
3. 序列
① 定义
所谓序列,就是一系列成员的有序排列。Python的基本数据类型中,字符串、列表和元组属于序列,其成员(元素)是有序的,序号从0开始。0表示第1位,-1表示末尾第1位。
② 序列的通用操作
- 索引
- 分片
- 加法
- 乘法
- 成员操作符
- 最大值、最小值和长度
4. 基本数据类型——字符串(String)
① 定义
字符串是用英文半角双引号("")或单引号('')引起来的内容,当遇到特殊字符时,可以使用反斜杠(\)进行转义。
字符串是不可变对象。
② 特点
⑴ 字符串的字符从左到右顺序排列。
⑵ 字符串不可改变。
⑶ 字符串使用英文半角单引号('')、双引号("")、三单引号('''''')、三双引号("""""")引用来表示。
-
注意:
- 单独使用时,单引号和双引号没有区别。
- 当引号中嵌套引号时,必须单引号中嵌套双引号;或者双引号中嵌套单引号。
- 三引号当中的内容可以跨行,将保留内容的原格式。
-
举例:
字符串引号的区别
③ 字符串格式化表达
⑴ 基本使用
| 类型 | 表达 | 输入类型 | 输出类型 |
|---|---|---|---|
| num | %d | 十进制数 | 十进制数 |
| str | %s | 字符串 | 字符串 |
| hex | %x | 十进制数 | 十六进制数 |
| oct | %o | 十进制数 | 八进制数 |
| float | %f | 浮点数 | 浮点数 |
⑵ 对齐方式
按 <num> 个字符位右对齐,前边补空格,其中,传入的字符个数也占<num>个数。用法:
%<num>d,%<num>s,%<num>x,%<num>o,%<num>f。“<num>”用数字代替。按 <num> 个字符位右对齐,前边补0,其中,传入的字符个数也占<num>个数。用法:
%0<num>d,%0<num>x,%0<num>o,%0<num>f。“<num>”用数字代替。按 <num> 个字符位左对齐,前边不能补内容。用法:
%-<num>d,%-<num>s,%-<num>x,%-<num>o,%-<num>f。“<num>”用数字代替。保留 <num> 位小数。用法:
%.<num>f。“<num>”用数字代替。
⑶ 举例
④ 前缀字符
⑴ “r”或“R”:字符串引号前有“r”或“R”,则表示字符串为非转义原始字符串,字符串内如有特殊功能的字符,将不起作用。
⑵ “b”或“B”:字符串引号前有“b”或“B”,则表示引号内为bytes类型。与普通字符串的区别是bytes访问类型是ASCII编码,并非是字符。
- 特殊功能字符:
| 符号 | 含义 |
|---|---|
| \n | 换行 |
| \r | 回车 |
| \b | 删除前一个字符 |
| \t | 制表符(tab键) |
| \033[ | VT100码前缀 |
-
举例:
前缀字符和特殊功能字符
⑤ 字符串与其他格式之间的转换
⑴ 其他格式转为字符串:str()
⑵ str转bytes类型:string.encode() 。其中,“string”表示任意“str”类型字符串。
⑶ bytes转str类型:bytes.decode() 。其中,“bytes”表示任意bytes类型字符串。
⑷ 字符串转ASCII码值:ord(string)。其中,“string”表示任意一个“str”类型字符。
⑸ ASCII码值转字符串:chr(number)。其中,“number”表示数字。
- ASCII码表:
-
举例:
字符串与其他格式之间的转换
⑥ 字符串的序列属性
⑴ 索引
索引即根据字符串成员的序号获取相应的内容。
string[number]
“string”为任意字符串。
“number”为数字,即要查找的序号,序号从0开始。0表示第1位,-1表示倒数第1位。
⑵ 分片
分片用于取字符串指定序号间的内容。
string[num1:num2:num3]
“string”为任意字符串。
“num1”为数字,即要查找的起始序号。若“num1”为空,则默认从第1位开始,“num1”后的冒号不可省略。
“num2”为数字,即要查找的截止序号(不包括此序号)。若“num2”为空,则默认到最后1位。若“num2”和“num3”同时为空,则“num2”后的冒号可以省略;若“num2”为空,“num3”有值,则“num2”后的冒号不能省略。
“num3”为数字,表示步长,“num3”可有可无,当没有“num3”时,同时省略“num3”前冒号,默认步长为1。若“num3”为-1,则表示倒序。
序号从0开始。0表示第1位,-1表示倒数第1位。
⑶ 加法
字符串加法不是数值相加,而是用加号“+”连接两个或多个字符串。
string1 + string2 + ... + stringN
- “string”为任意字符串。
⑷ 乘法
字符串乘法不是数值相乘,而是复制指定遍数的操作。
string * number
- “string”为任意字符串。
- “number”为数字,表示复制的遍数。
⑸ 成员判断
成员判断即运用成员操作符“in”或“not in”来判断指定字符是否在字符串当中。
string1 in string
string1 not in string
“string1”和“string”可以是任意字符串。
string1 in string用于判断string1是否在string当中,若在,返回True;若不在,返回False。string1 not in string用于判断string1是否不在string当中,若不在,返回True;若在,返回False。
⑹ 最大值、最小值和长度
最大值:判断字符串中ASCII码值最大的成员。语法:
max(string)最小值:判断字符串中ASCII码值最小的成员。语法:
min(string)长度:判断字符串成员的个数。语法:
len(string)
⑺ 举例
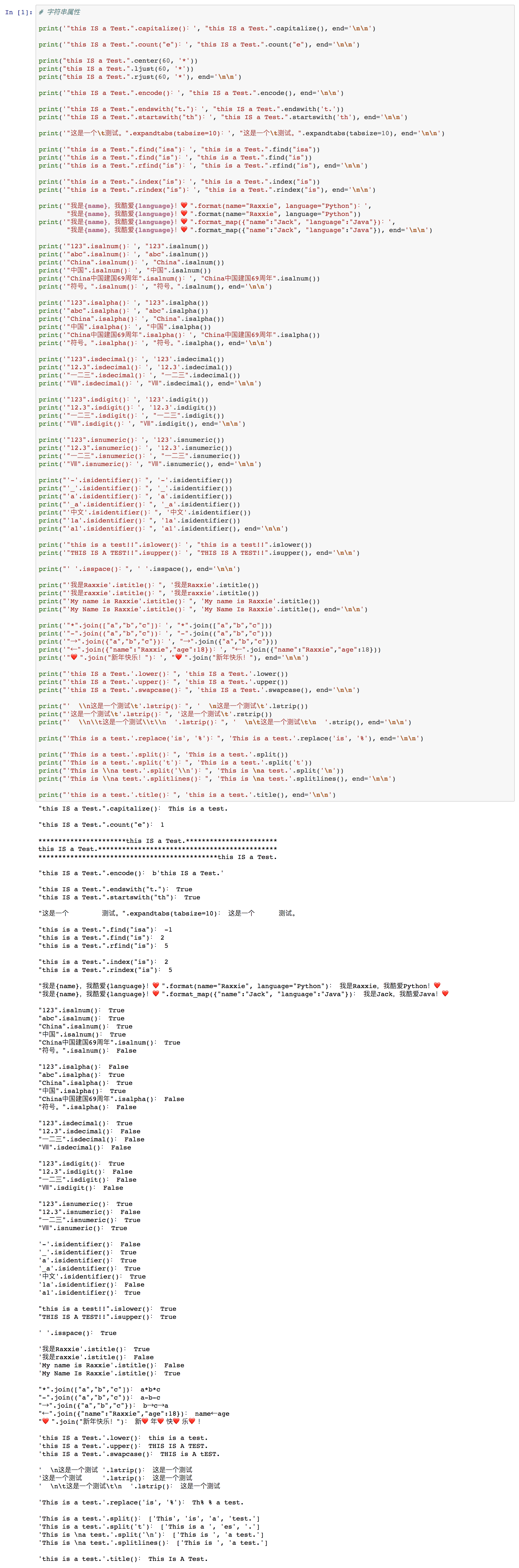
⑦ 字符串属性
⑴ 属性
| 属性 | 含义 | 用法 |
|---|---|---|
| string.capitalize() | 字符串首字母大写,其余全小写 | 不需要参数 |
| string.count(s[, n1, n2]) | 在字符串中查找指定字符的个数 | s为字符串,表示查找内容;n1为数字,表示查找的起始位置,可无;n2为数字,表示查找的截止位置,可无 |
| string.center(n, s) | 把string居中,前后填充s | n为数字,表示字符数;s为字符串,表示string前后填充的内容 |
| string.ljust(n, s) | 把string左对齐,然后右边填充s | n为数字,表示字符数;s为字符串,表示string前后填充的内容 |
| string.rjust(n, s) | 把string右对齐,然后左边填充s | n为数字,表示字符数;s为字符串,表示string前后填充的内容 |
| string.encode() | 把string转化为bytes类型 | |
| string.endswith(s) | 判断string是否是以s结尾,是返回True,不是返回False | s为字符串,用于判断string是否以s结尾 |
| string.startswith(s) | 判断string是否是以s开头,是返回True,不是返回False | s为字符串,用于判断string是否以s开头 |
| string.expandtabs(tabsize=n) | 将string中的制表符缩进定义为n个空格 | n为自定义缩进的空格数 |
| string.find(s) | 查找s在string中最左边的位置,返回索引;若不存在,返回-1 | s为字符串,表示被查找内容 |
| string.rfind(s) | 查找s在string中最右边的位置,返回索引;若不存在,返回-1 | s为字符串,表示被查找内容 |
| string.index(s) | 查找s在string中最左边的位置,返回索引;若不存在,抛出异常 | s为字符串,表示被查找内容 |
| string.rindex(s) | 查找s在string中最右边的位置,返回索引;若不存在,抛出异常 | s为字符串,表示被查找内容 |
| string.format() | 以关键字传值的方式在string中格式化输入内容 | 若为string中{name}传入值,则format(name="自定义内容") |
| string.format_map() | 以字典的方式在string中格式化输入内容 | 若为string中{name}传入值,则format_map({"name":"自定义内容"}) |
| string.isalnum() | 检测string是否由中文、字母和数字组成。只要满足其一,返回True,否则返回False | |
| string.isalpha() | 检测string是否只由中文、字母组成。全中文或全英文或中英文结合,返回True,否则返回False。 | |
| string.isdecimal() | 检测string是否是十进制数字,是就返回True,不是返回False | |
| string.isdigit() | 检测string是否是数字,是就返回True,不是返回False | |
| string.isnumeric() | 检测string是否是数字(中文、罗马、阿拉伯),是就返回True,不是返回False | |
| string.isidentifier() | 判断string是否是合法的变量名,合法返回True,否则返回False | |
| string.islower() | 检测string是否全是小写,是返回True,不是返回False。不考虑标点 | |
| string.isupper() | 检测string是否全是大写,是返回True,不是返回False。不考虑标点 | |
| string.ispace() | 检测string是否是空格,是返回True,不是返回False | |
| string.istitle() | 检测string中的每一个英文单词都是首字母大写的,是返回True,不是返回False | |
| string.join(iterable) | 把iterable的每两个元素之间用string结合起来 | iterable是指可迭代对象 |
| string.lower() | 把string变成全小写 | |
| string.upper() | 把string变成全大写 | |
| string.swapcase() | 把string中的大写转成小写,小写转成大写 | |
| string.lstrip() | 删除string左边的换行符('\n'),制表符('\t')和空格。 | |
| string.rstrip() | 删除string右边的换行符('\n'),制表符('\t')和空格。 | |
| sting.strip() | 删除string两边的换行符('\n'),制表符('\t')和空格。 | |
| string.replace(old, new, n) | 把string中的从左到右的n个old替换成new | old和new均为字符串,意味把old替换成new;n为数字,即从左往右替换old的个数,可无 |
| string.split(s) | 把string以s分割,分割之后返回列表 | s为字符串,表示分隔符 |
| string.splitlines(s) | 把string以换行符(\n)分割,分割之后返回列表 | |
| string.title() | 把string当中的所有单词都变为首字母大写 |
⑵ 举例
5. 基本数据类型——列表(List)
① 定义
列表是Python中使用最为频繁的数据类型,各个元素以英文半角逗号隔开,并用方括号“[]”括起所有元素,整个方括号及其内部的元素称为列表。
列表是可变对象。
[cell1, cell2, ..., cellN]
其中,“cell”是列表的元素。
② 列表的元素类型
列表的元素类型可以是任意数据类型,且元素之间的类型可以不同。元素的类型可以是:数字,字符串,列表,元组,字典和集合。
当列表的元素仍为列表时,就实现了列表的嵌套。
例如:
[1, 'raxxie', ['Python', 2018], ('a', 'b', 'c'), {1, 2, 3}, {'name':'Raxxie', 'age':18}]
③ 其他数据类型转为列表
list(iterable)
其中,“iterable”为可迭代对象。
例如:
④ 列表的序列属性
⑴ 索引
列表是“有序”的。索引即根据列表元素的位置序号读取相应元素。
list[number]
“list”为任意列表。
“number”为数字,即要查找的序号,序号从0开始。0表示第1位,-1表示倒数第1位。
若要修改列表指定位置元素的值,可以通过索引的方式修改:
list[number] = new
“list”为任意列表。
“number”为数字,即要查找的序号,序号从0开始。0表示第1位,-1表示倒数第1位。
“new”为“list[number]”的新值。
例如:
⑵ 分片
分片用于读取列表指定位置序号间的元素。
list[num1:num2:num3]
“list”为任意列表。
“num1”为数字,即要查找的起始序号。若“num1”为空,则默认从第1位开始,“num1”后的冒号不可省略。
“num2”为数字,即要查找的截止序号(不包括此序号)。若“num2”为空,则默认到最后1位。若“num2”和“num3”同时为空,则“num2”后的冒号可以省略;若“num2”为空,“num3”有值,则“num2”后的冒号不能省略。
“num3”为数字,表示步长,“num3”可有可无,当没有“num3”时,同时省略“num3”前冒号,默认步长为1。若“num3”为-1,则表示倒序。
序号从0开始。0表示第1位,-1表示倒数第1位。
例如:
⑶ 加法
列表加法不是数值相加,而是将2个或多个列表拼接成1个列表。拼接方法是加号“+”后边的列表元素直接添加到加号“+”前边列表最后1个元素的后边。
list1 + list2 + ... + listN
- “list”为任意列表。
例如:
⑷ 乘法
语法
列表乘法不是数值相乘,而是把列表中的元素复制指定遍数的操作。
list * number
- “list”为任意列表。
- “number”为数字,表示复制的遍数。
但是,元素为可变对象的列表乘法和元素为不可变对象列表乘法,其效果是存在差异的。在解释这种差异之前,先来了解什么是可变对象和不可变对象。
不可变对象
不可变对象,是指该对象所指向的内存中的值不能被改变。当改变某个变量时候,由于其所指的值不能被改变,相当于把原来的值复制一份后再改变,这会开辟一个新的地址,变量再指向这个新的地址。
不可变对象包括:数字(int 和 float)、字符串(string)和元组(tuple)。
可变对象
可变对象,是指该对象所指向的内存中的值可以被改变。变量(准确的说是引用)改变后,实际上是其所指的值直接发生改变,并没有发生复制行为,也没有开辟新的地址,通俗点说就是原地改变。
可变对象包括:列表(list)、字典(dictionary)和集合(set)。
列表乘法的差异
当元素是不可变对象的列表时,列表乘法之后生成新的列表。修改新列表的某个(些)元素的值不会改变其他元素。
当元素是可变对象的列表时,列表乘法之后生成新的列表。修改新列表的某个(些)元素的值时,被复制的元素也会随之发生变化。
总之,列表进行乘法运算之后所得新的列表。在修改新列表的元素值时,修改的是不可变对象,则其他被复制的值不会改变;修改的是可变对象,则其他被复制的值也会跟着改变。
简言之,列表的乘法对于不可变对象是复制的值,对于可变对象是复制的引用。
举例
⑸ 成员判断
成员判断即运用成员操作符“in”或“not in”来判断指定内容是否在列表当中。
cell in list
cell not in list
“cell”可以是任何数据类型。
“list”指任意列表。
cell in list用于判断cell是否在list当中,若在,返回True;若不在,返回False。cell not in list用于判断cell是否不在list当中,若不在,返回True;若在,返回False。
⑹ 最大值、最小值和长度
最大值 和 最小值
最大值:判断列表最大的元素。语法:max(list) 。
最小值:判断列表最小的元素。语法:min(list) 。
需要注意的是,只有当列表元素的数据类型相同的情况下才能够取出最大值,否则会抛出异常。
元素为数字的列表,将取出数值最大的元素作为最大值;取出数值最小的元素作为最小值。
元素为字符串的列表,将取出ASCII码值最大的元素作为最大值;取出ASCII码值最小的元素作为最小值。
元素为元组(或列表)的列表,元组(或列表)的元素数据类型要相同,否则抛出异常,其比较原则同“数字”或“字符串”。
元素为集合的列表,最大值和最小值均是排在第1个的集合,因此无法比较。
元素为字典的列表,无法比较最大值和最小值。
长度
- 长度:判断列表的元素个数。语法:
len(list)
举例
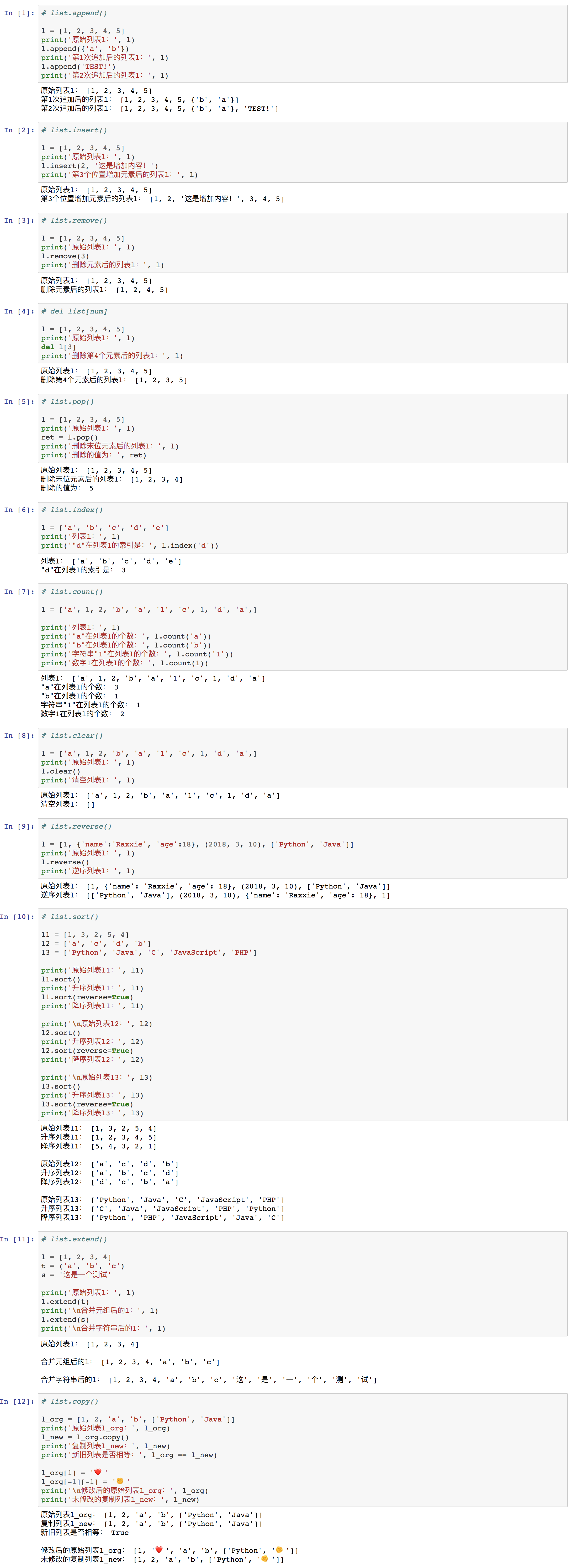
⑤ 列表的属性
⑴ 属性
| 属性 | 含义 | 用法 |
|---|---|---|
| list.append(cell) | 在list中追加(末尾添加)一个元素 | 参数可以是任何数据类型 |
| list.insert(num, cell) | 在list指定位置添加一个元素 | num为添加元素的位置序号(索引);cell是被添加的元素内容,可以是任何数据类型 |
| list.remove(cell) | 在list中删除cell元素,返回None | cell是将被删除的元素,必须是list当中的元素 |
| del list[num] | 这不是list属性,而是用del删除list中指定位置的元素 | num是删除元素的位置序号(索引) |
| list.pop() | 删除list中的最后一个元素,并且返回该元素的值 | 没有参数 |
| list.index(cell) | 返回cell在list中的索引 | cell是被查找索引的元素值,可以是任何数据类型,但必须是list当中的元素 |
| list.count(cell) | 查找cell在list的个数,返回数字 | cell是被计数的元素值,可以是任何数据类型,但必须是list当中的元素 |
| list.clear() | 清空list | 没有参数 |
| list.reverse() | 使list逆序 | 没有参数 |
| list.sort([reverse=True/False]) | 使list降序/升序排序 | 参数可有可无。若参数reverse=True,则降序排列;若没有参数或参数reverse=False,则升序排列 |
| list.extend(iterable) | 把iterable的元素追加到list末尾 | 参数iterable必须是可迭代对象 |
| list.copy() | 复制列表 | 列表元素为不可变对象时,修改元素值其他被复制元素不会改变;列表元素为可变对象时,修改元素值其他被复制元素值也跟着改变 |
注意: list.copy() 原理请参考本部分“列表的序列属性”之“乘法”部分。
⑵ 举例
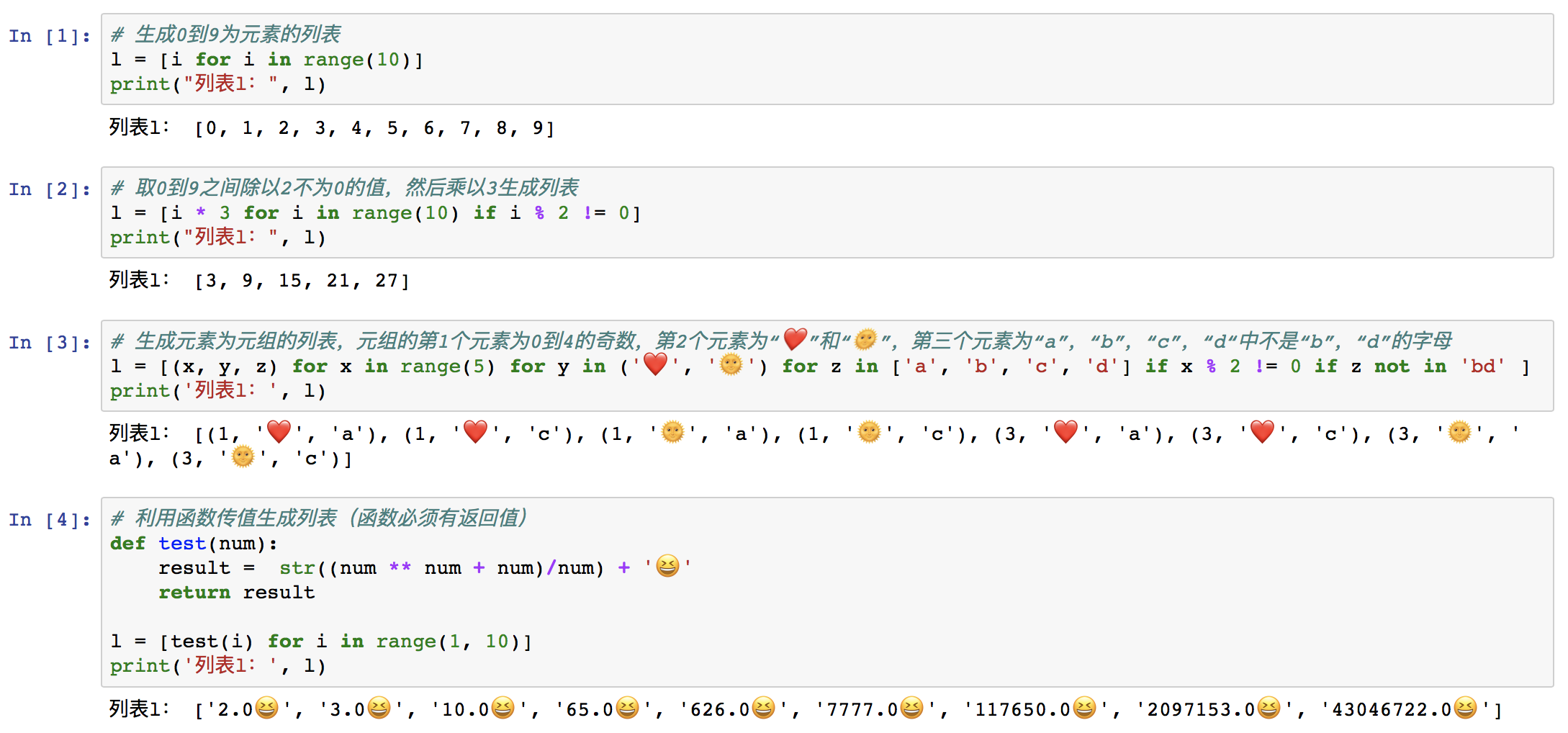
⑥ 列表推导式
列表推导式又称列表生成式或列表解析式,是通过固定语法生成列表的方式。
[<cell_expression> for <cell> in <iterable> if <cell_condtion>]
其中:
“<cell_expression>”是列表元素所满足的表达式,也可以只是元素本身。
“<cell>”是元素的变量名,要与“<cell_expression>”中的元素变量名保持一致。
“<iterable>”是可迭代对象。此处可以是:列表,元组,字符串,
range()。“if <cell_condition>”是元素的取值条件,可有可无。
举例:
6. 基本数据类型——元组(Tuple)
① 定义
各个元素以英文半角逗号隔开,并用小括号“()”括起所有元素,整个小括号及其内部的元素称为元组。
(cell1, cell2, ..., cellN)
其中,“cell”是元组的元素。
元组被称为不可变列表(或只读列表),因为元组的元素只能被读取,不能被修改。
空元组表示为:()
只有一个元素的元组表示:(cell,) ,其中,“cell”表示元素,可以是任意数据类型。
需要注意的是,单元素元组小括号内元素后边的逗号不能省略,否则这将不是元组类型,而是该元素的数据类型。
例如:

② 元组的元素类型
元组的元素类型可以是任意数据类型,且元素之间的类型可以不同。元素的类型可以是:数字,字符串,列表,元组,字典和集合。
当元组的元素仍为元组时,就实现了元组的嵌套。
例如:
(1, 'raxxie', ['Python', 2018], ('a', 'b', 'c'), {1, 2, 3}, {'name':'Raxxie', 'age':18})
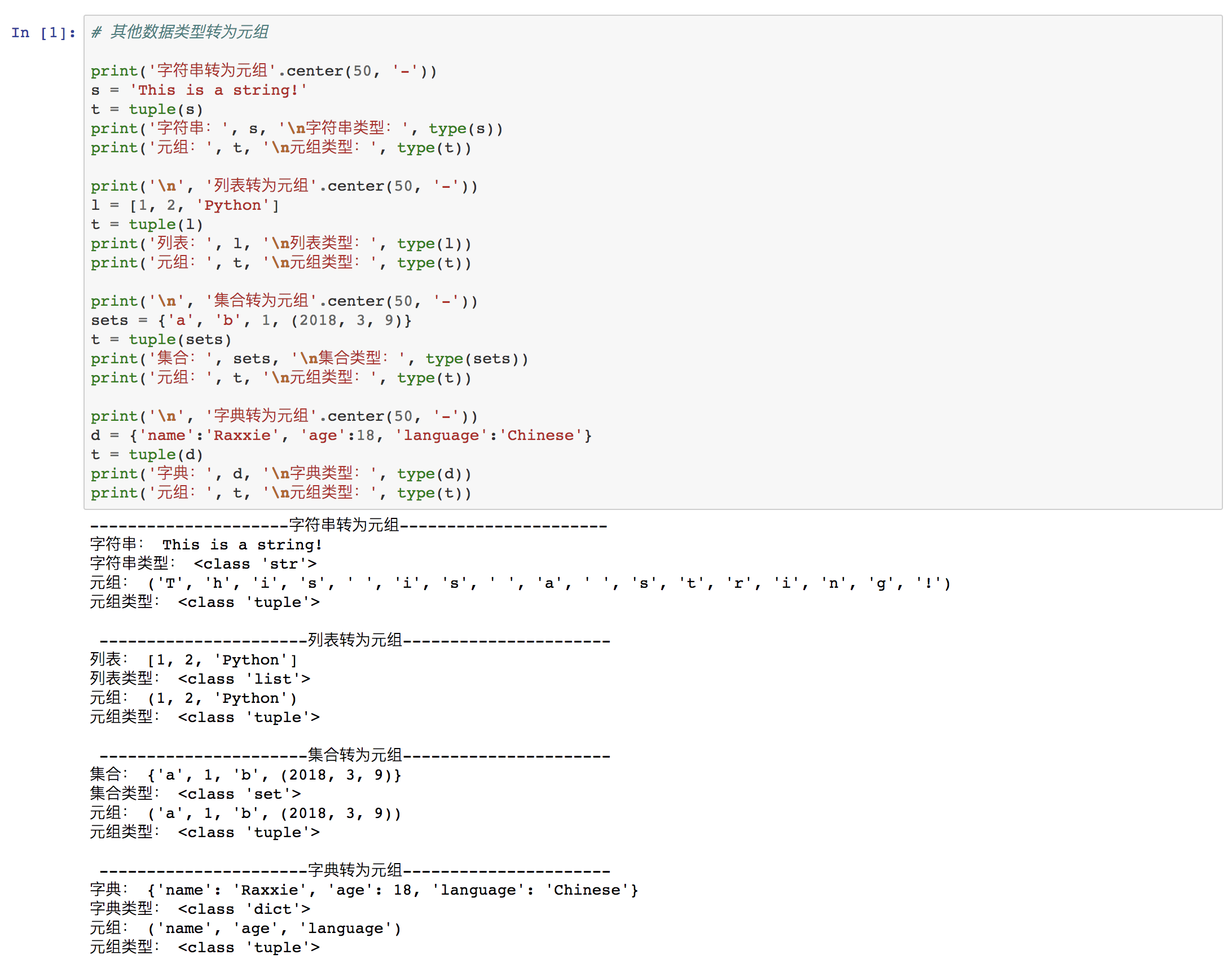
③ 其他数据类型转为元组
tuple(iterable)
其中,“iterable”为可迭代对象。
例如:
④ 元组的序列属性
⑴ 索引
元组是“有序”的。索引即根据元组元素的位置序号读取相应元素。
tuple[number]
“tuple”为任意元组。
“number”为数字,即要查找的序号,序号从0开始。0表示第1位,-1表示倒数第1位。
由于元组是只读的,因此不能以任何方式修改其元素的值。
⑵ 分片
分片用于读取元组指定位置序号间的元素。
tuple[num1:num2:num3]
“tuple”为任意元组。
“num1”为数字,即要查找的起始序号。若“num1”为空,则默认从第1位开始,“num1”后的冒号不可省略。
“num2”为数字,即要查找的截止序号(不包括此序号)。若“num2”为空,则默认到最后1位。若“num2”和“num3”同时为空,则“num2”后的冒号可以省略;若“num2”为空,“num3”有值,则“num2”后的冒号不能省略。
“num3”为数字,表示步长,“num3”可有可无,当没有“num3”时,同时省略“num3”前冒号,默认步长为1。若“num3”为-1,则表示倒序。
序号从0开始。0表示第1位,-1表示倒数第1位。
⑶ 加法
元组加法不是数值相加,而是将2个或多个元组拼接成1个新的元组。拼接方法是加号“+”后边的元组元素拼接到加号“+”前边元组最后1个元素的后边,由此形成1个新的元组。
tuple1 + tuple2 + ... + tupleN
- “tuple”为任意元组。
⑷ 乘法
元组乘法不是数值相乘,而是把元组中的元素复制指定遍数,然后形成1个新的元组的操作。
tuple * number
- “tuple”为任意元组。
- “number”为数字,表示复制的遍数。
⑸ 成员判断
成员判断即运用成员操作符“in”或“not in”来判断指定内容是否在元组当中。
cell in tuple
cell not in tuple
“cell”可以是任何数据类型。
“tuple”指任意列表。
cell in tuple用于判断cell是否在tuple当中,若在,返回True;若不在,返回False。cell not in tuple用于判断cell是否不在tuple当中,若不在,返回True;若在,返回False。
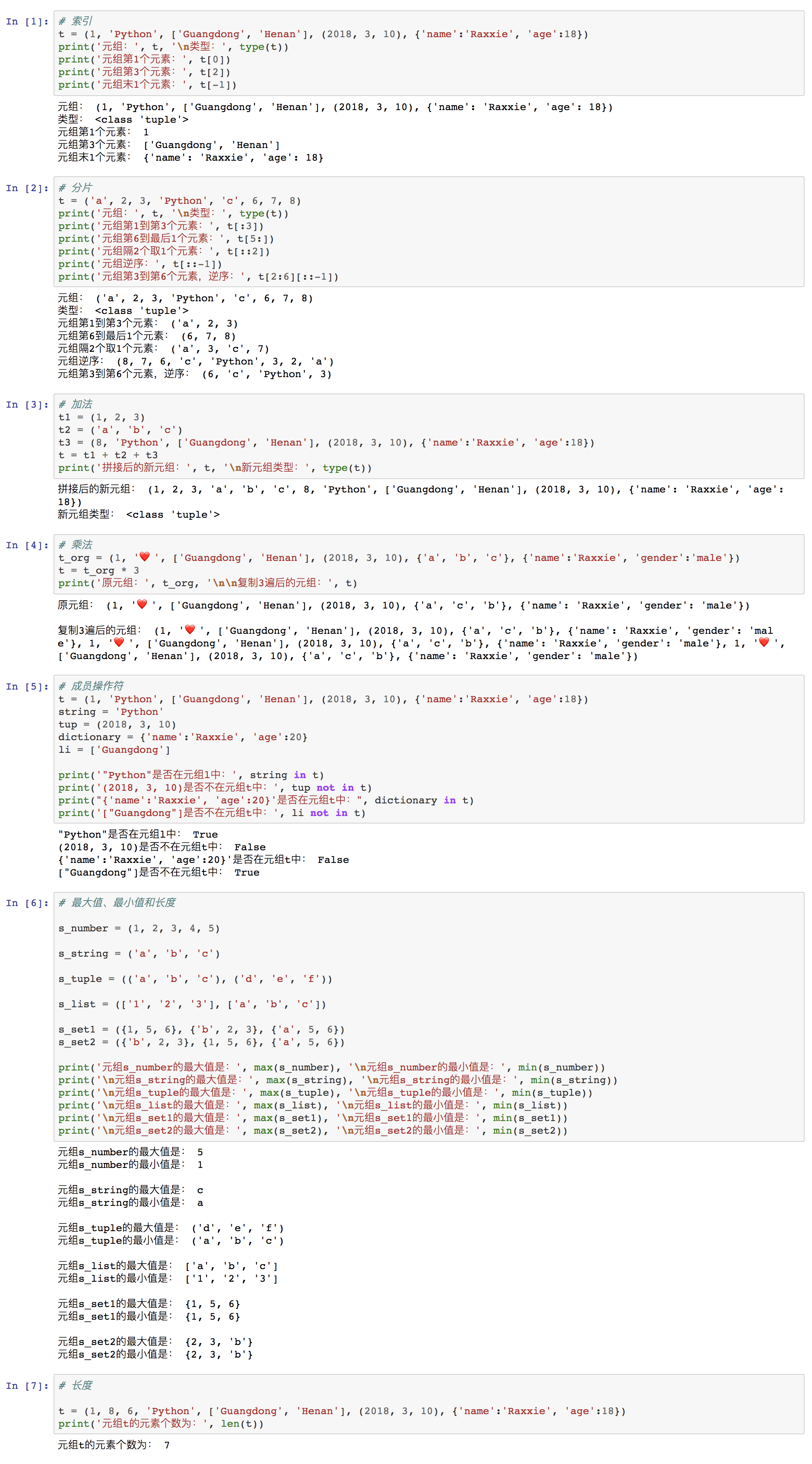
⑹ 最大值、最小值和长度
最大值 和 最小值
最大值:判断元组最大的元素。语法:max(tuple) 。
最小值:判断元组最小的元素。语法:min(tuple) 。
需要注意的是,只有当元组元素的数据类型相同的情况下才能够取出最大值,否则会抛出异常。
元素为数字的元组,将取出数值最大的元素作为最大值;取出数值最小的元素作为最小值。
元素为字符串的元组,将取出ASCII码值最大的元素作为最大值;取出ASCII码值最小的元素作为最小值。
元素为列表(或元组)的元组,列表(或元组)的元素数据类型要相同,否则抛出异常,其比较原则同“数字”或“字符串”。
元素为集合的元组,最大值和最小值均是排在第1个的集合,因此无法比较。
元素为字典的元组,无法比较最大值和最小值。
长度
- 长度:判断元组的元素个数。语法:
len(tuple)
举例
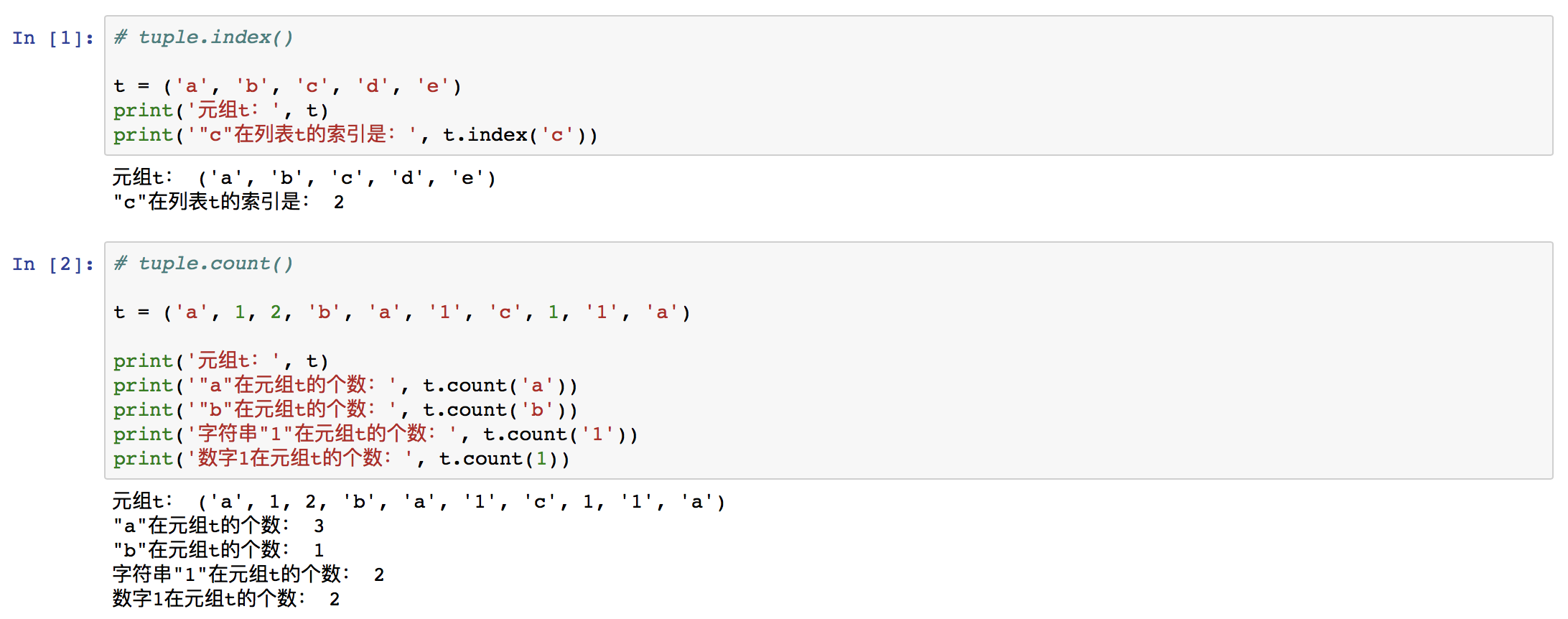
⑤ 元组的属性
⑴ 属性
| 属性 | 含义 | 用法 |
|---|---|---|
| tuple.index(cell) | 返回cell在tuple中的索引 | cell是被查找索引的元素值,可以是任何数据类型,但必须是tuple当中的元素 |
| tuple.count(cell) | 查找cell在tuple的个数,返回数字 | cell是被计数的元素值,可以是任何数据类型,但必须是tuple当中的元素 |
⑵ 举例
7. 基本数据类型——集合(Sets)
① 定义
一组互不相同的数据以英文半角逗号隔开,用花括号“{}”括起来,花括号和这组数据被称为集合。
集合是无序的,因此集合不能索引和分片。
{cell1, cell2, ..., cellN}
其中,“cell”是集合的元素。
集合的元素只能是数字、字符串、元组。
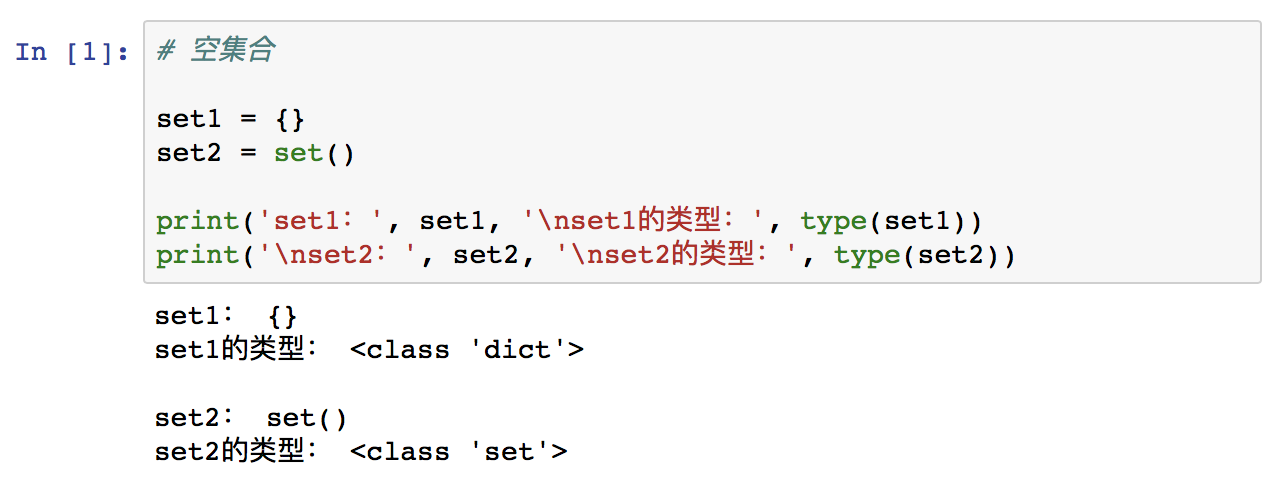
空集合不能使用 {} 来定义,因为 {} 是空字典,即字典类型;要通过 set() 来定义。
例如:
② 集合的特性
确定性:给定一个集合,任给一个元素,该元素或者属于或者不属于该集合,二者必居其一,不允许有模棱两可的情况出现。
互异性:一个集合中,任何两个元素都认为是不相同的,即每个元素只能出现一次。
无序性:一个集合中,每个元素的地位都是相同的,元素之间是无序的。
③ 其他数据类型转为集合
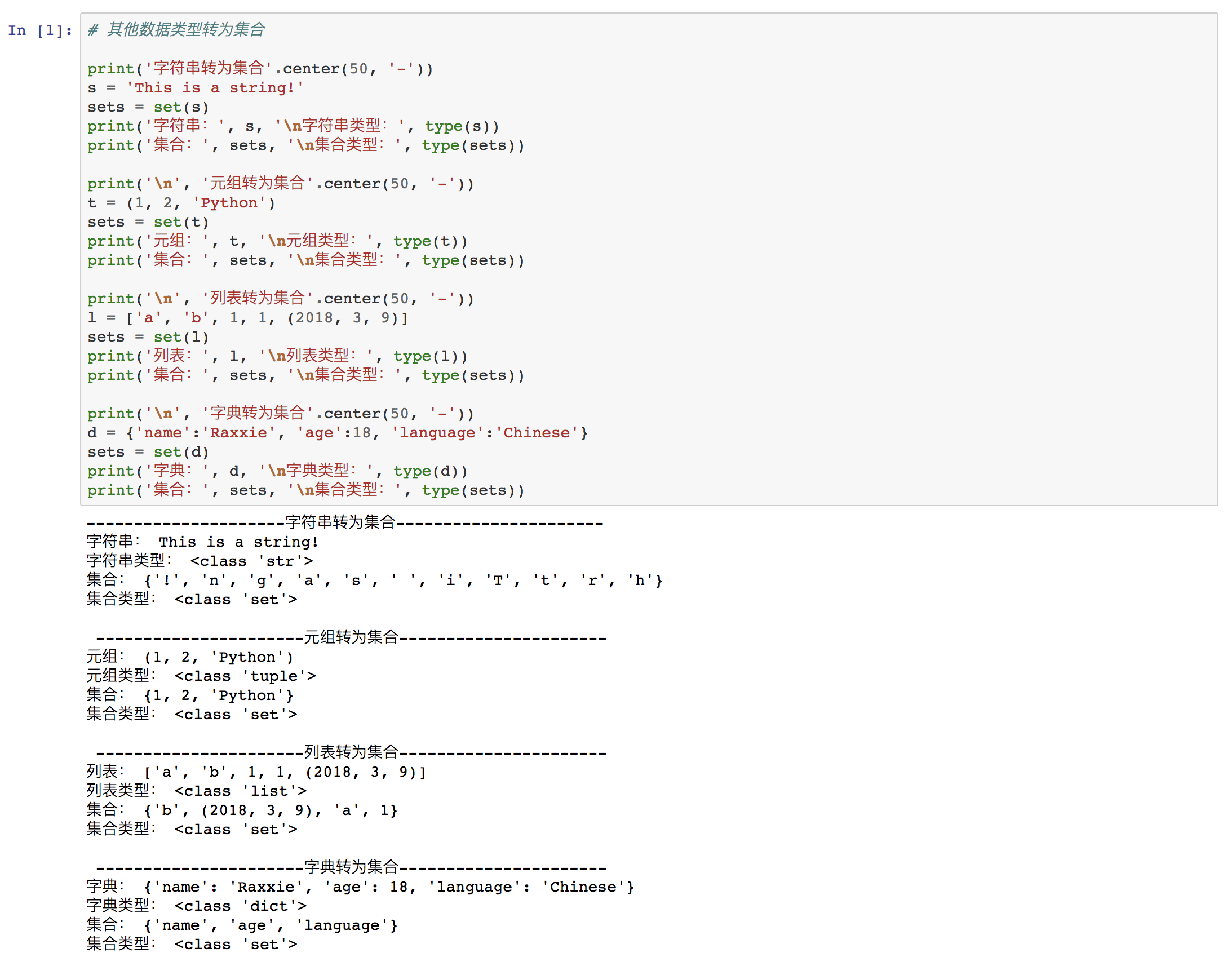
- 注意:
其他数据类型转为集合时,重复的元素将只会保留1个。
字典转为集合时,只是将字典的“Key”作为集合的元素形成新的集合。
④ 集合的使用场景
“去重需求”:去掉重复元素的需求。
“关系判断”需求:测试两组数据之间的关系,包括但不仅限于:交集、差集、并集。
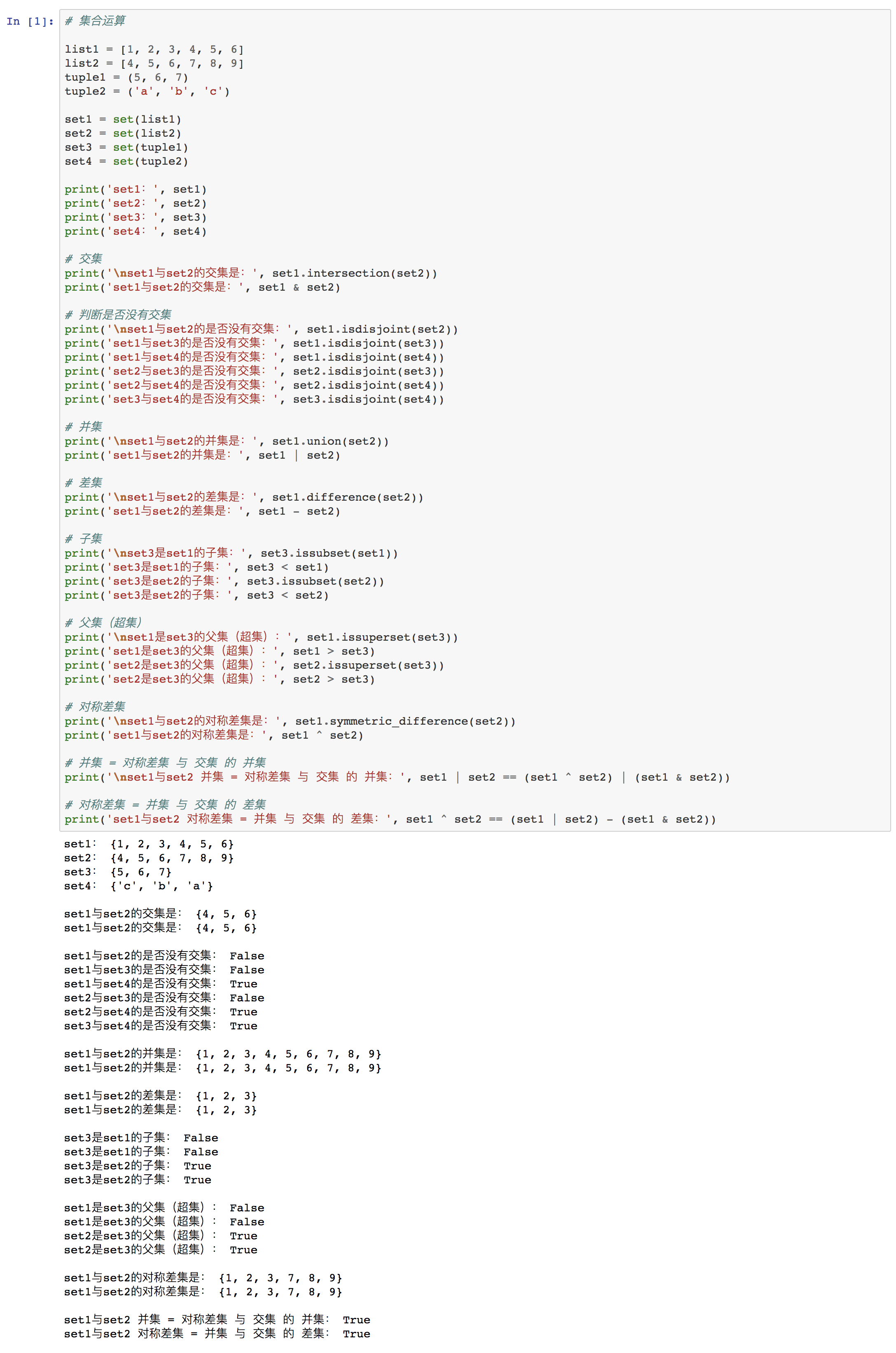
⑤ 集合运算(关系测试)
⑴ 交集
交集即取两集合重合的元素。
set1.intersection(set2)
或
set & set2
⑵ 判断是否没有交集
set1.isdisjoint(set2)
如果 set1 & set2 == set() 那么表示set1和set2没有交集,或称两集合交集为空集。
⑶ 并集
并集是合并两集合的所有元素且只保留1组重复元素。
set1.union(set2)
或
set1 | set2
⑷ 差集
若两个集合分别是set1和set2,则差集就是属于set1且不属于set2的元素。
set1.difference(set2)
或
set1 - set2
⑸ 子集
若两个集合分别是set1和set2,且set1是set2的一部分(或全部),则称为set1是set2的子集。
set1.issubset(set2)
或
set1 < set2
如果set1是set2的子集,则结果返回True;否则返回False。
⑹ 父集或超集
若两个集合分别是set1和set2,且set1是set2的一部分(或全部),则称为set2是set1的父集(或超集)。
set1.issuperset(set2)
或
set2 > set1
如果set2是set1的父集(或超集),则结果返回True;否则返回False。
⑺ 对称差集
对称差集即两集合中不相同元素的结合。
set1.symmetric_difference(set2)
或
set1 ^ set2
两集合的对称差集 与 交集 的 并集,等于两集合的并集。即:
set1 | set2 == (set1 ^ set2) | (set1 & set2)两集合的并集 与 交集 的 差集,等于两集合的对称差集。即:
set1 ^ set2 == (set1 | set2) - (set1 & set2)
⑻ 举例
⑥ 三组运算的实例对比
⑴ difference() 与 difference_update()

⑵ intersection() 与 intersection_update()

⑶ symmetric_difference() 与 symmetric_difference_update()

⑦ 集合的增删
⑴ 增
增加1个元素
set.add(cell)
“cell”表示添加的元素,只能是数字、字符串或元组。
参数只能有1个。
增加多个元素
set.update(iteralbe1, iterable2, ..., iterableN)
“iterable”表示添加的元素,只能是可迭代对象(iterable)。
参数可以是多个。
当参数为字符串时,将把字符串的每个字符作为1个元素添加到集合中。
当参数为列表或元组时,将把元组或列表的每个元素作为1个元素添加到集合中。
举例

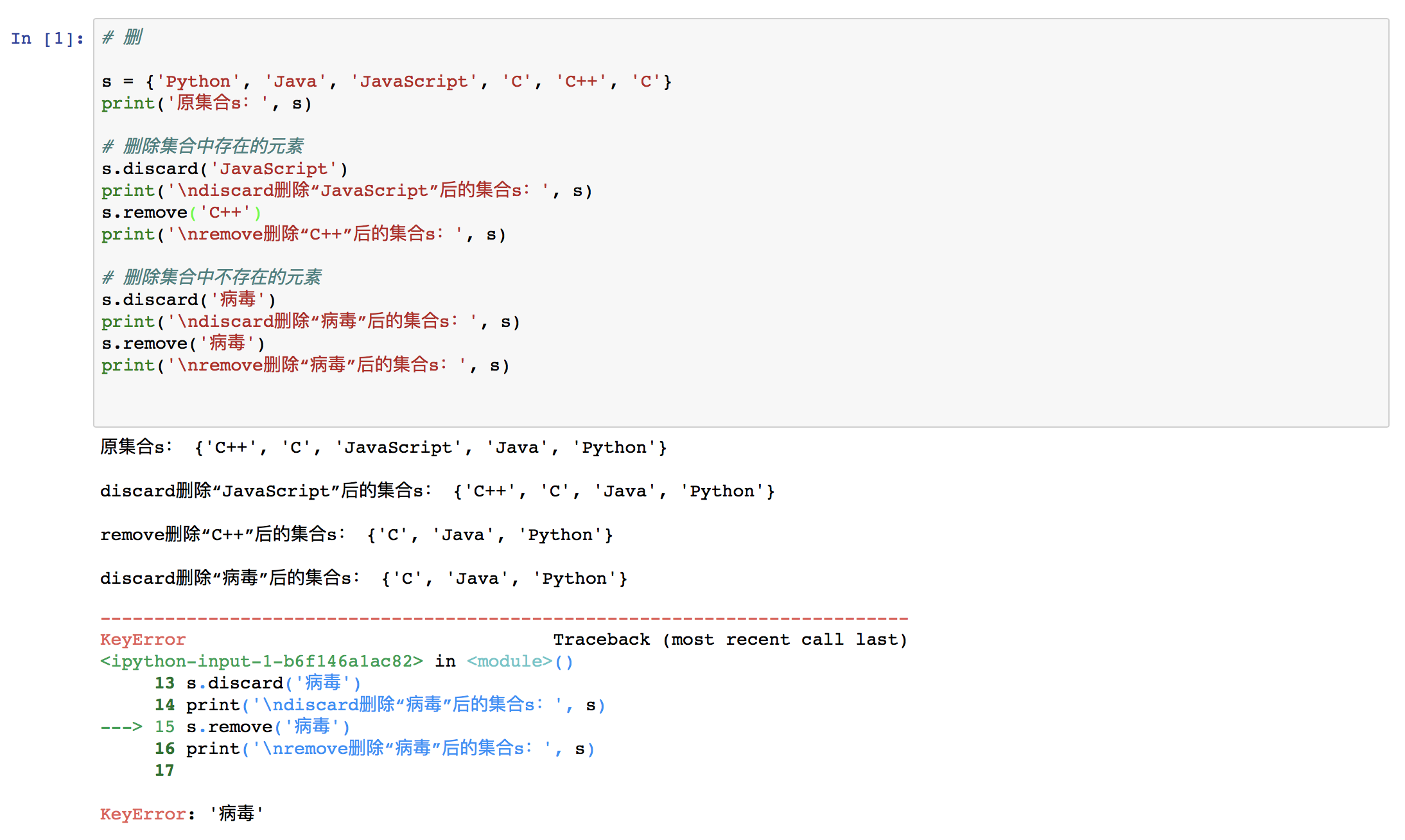
⑵ 删
set.remove(cell)
“cell”表示将被删除的元素。
被删除的元素必须在集合中存在。否则将会抛出异常。
set.discart.(cell)
“cell”表示将被删除的元素。
如果被删除的元素在集合中存在,则删除该元素;否则不做任何处理。
举例:
set.pop()
没有参数。
随机删除集合中的一个元素,并返回删除元素的值。
set.clear()
没有参数。
清空集合。
例如:

⑧ 内置函数
⑴ 内置函数
| 属性 | 含义 | 用法 |
|---|---|---|
| all(set) | 集合元素全为真,返回True,一个为假返回False | 参数为集合。元素为:"", 0, (),False时为假,当集合为空时(即,set())返回True |
| any(set) | 集合元素全为假,返回False,一个为真返回True | 参数为集合。元素为:"", 0, (),False时为假,当集合为空时(即,set())返回False |
| enumerate(set) | 返回一个枚举对象,其中包含了集合中所有元素的索引和值(配对) | 参数为集合。可以通过遍历获取索引和值 |
| len(set) | 返回集合的元素个数 | 参数为集合。 |
| max(set) | 返回集合中元素的最大值 | 参数为集合。若集合元素为字符串,则比较ASCII值;若集合元素为数字,则比较数值;若集合元素为元组,则比较元组的第1个元素 |
| min(set) | 返回集合中元素的最小值 | 参数为集合。若集合元素为字符串,则比较ASCII值;若集合元素为数字,则比较数值;若集合元素为元组,则比较元组的第1个元素 |
| sorted(set[, reverse=True/False]) | 将集合中的元素值排列顺序并返回一个新的列表 | 参数为集合,返回的结果为列表。若集合元素为字符串,则比较ASCII值;若集合元素为数字,则比较数值。reverse参数可有可无,当reverse=True时,将降序排列;当没有reverse参数或reverse=False时,将升序排列 |
| sum(set) | 当集合元素全为数字时,计算集合元素之和 | 参数为集合。集合的元素只能是纯数字,否则将抛出异常 |
⑵ 举例
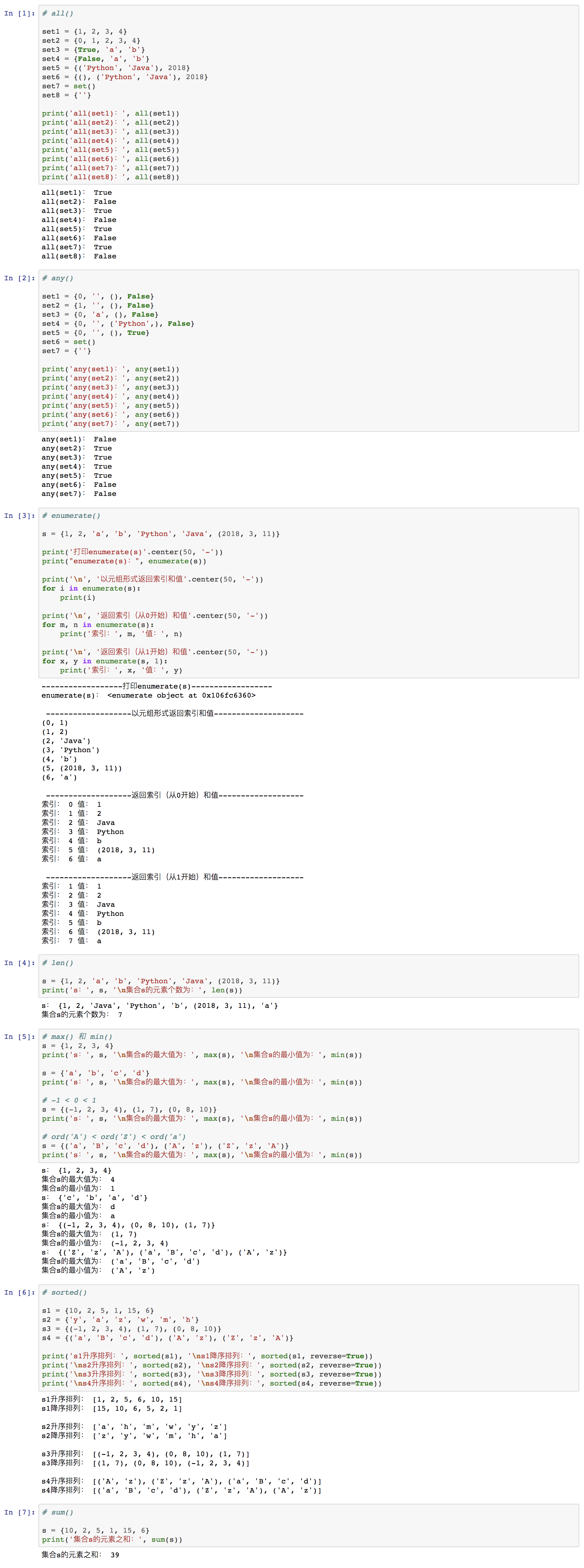
⑨ 不可变集合
根据前面的介绍,集合是可以增加(add() 或 update )和删除(remove())元素的。不可变集合则不具备增加和删除元素的属性。因此,创建一个不可变集合,可以通过以下方法:
frozenset([iterable])
- “iterable”表示可迭代对象。
- 当没有参数时,表示创建一个空不可变集合。
由于set是可变的,因此它不存在哈希值;frozenset是不可变的,所以它存在哈希值。并且,frozenset可以作为字典的key,也可以作为其他集合的元素。
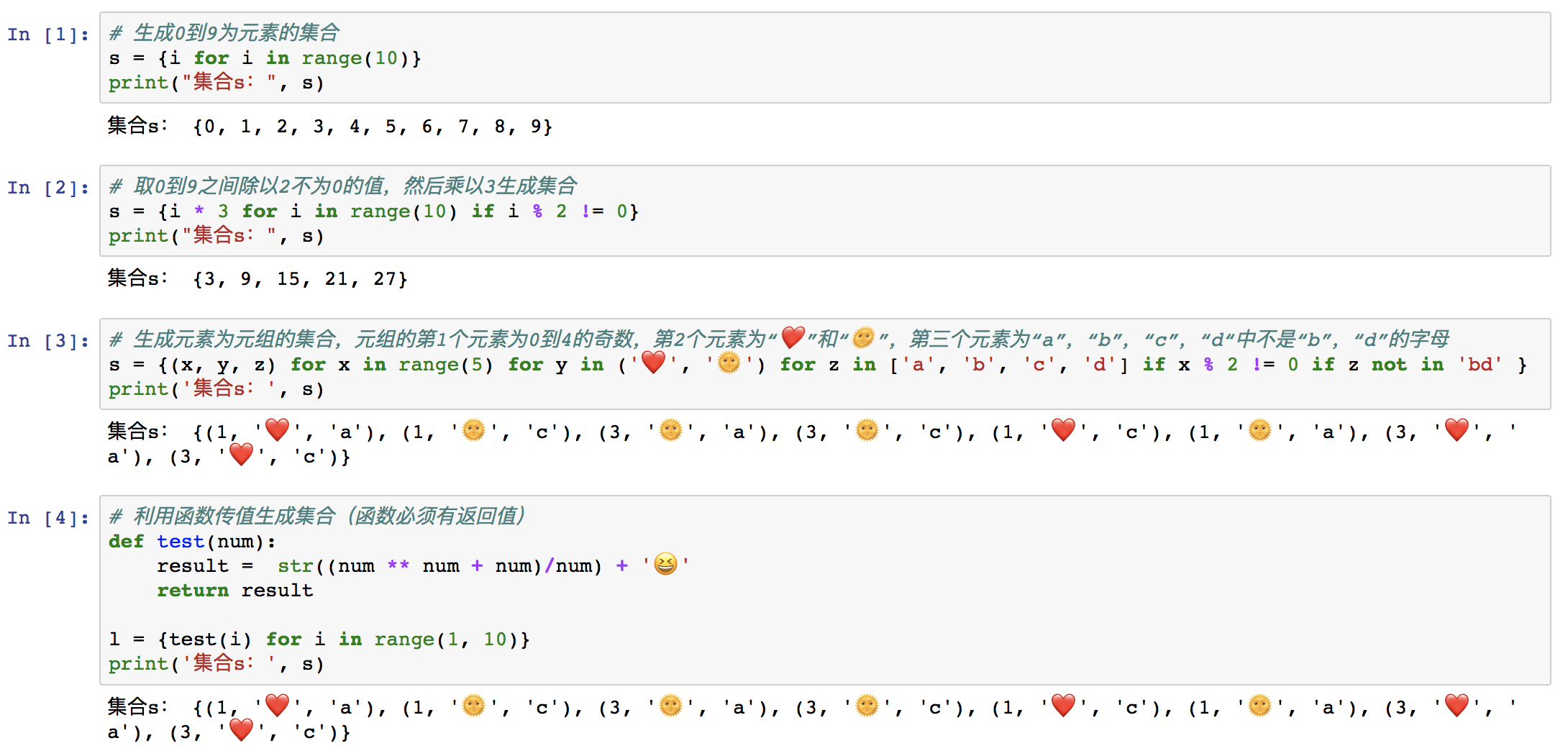
⑩ 集合推导式
集合推导式与列表推导式几乎相同,只是把列表的方括号“[]”替换成集合的花括号“{}”。并且生成的元素如有重复,则集合会自动去重。
集合推导式又称集合生成式或集合解析式,是通过固定语法生成集合的方式。
{<cell_expression> for <cell> in <iterable> if <cell_condtion>}
其中:
“<cell_expression>”是集合元素所满足的表达式,也可以只是元素本身。
“<cell>”是元素的变量名,要与“<cell_expression>”中的元素变量名保持一致。
“<iterable>”是可迭代对象。此处可以是:列表,元组,字符串,
range()。“if <cell_condition>”是元素的取值条件,可有可无。
举例:
8. 基本数据类型——字典(Dictionary)
① 定义
字典是可变对象,且字典是无序的。字典可以储存任何数据类型,它是以“键值对”(Key-Value)的方式储存数据的,即每个“键”(Key)对应一个“值”(Value),“键”和“值”之间以英文冒号隔开。这些键值对以英文半角逗号隔开,外侧以花括号“{}”括起。
{key1:value1, key2:value2, ..., keyN:valueN}
其中,“key”是字典的“键”;“value”是字典的值。
② 字典的“键”、“值”特点
- 字典的“键”必须是唯一的,而“值”可以不唯一。如果在创建字典时存在2个或多个相同的“键”,则取最后一个键值对。
例如:

字典的“键”必须是不可变对象的数据类型,包括:字符串,数字,元组。
字典的“值”可以是任何数据类型。
③ 创建字典
字典的创建方法有2种。
一种是根据字典的定义来创建字典,即通过在花括号内自定义键、值,并将键和值以冒号隔开,键值对之间以逗号隔开,由此创建字典。
另一种是通过 dict 语法生成:
dict(key1=value1, key2=value2, ..., keyN=valueN)
注意:第1种方法创建字典时,如果键的数据类型为字符串,则必须为键名添上英文半角单引号或双引号;第2种方法创建字典,键名不需要加引号。
例如:

④ 字典元素的增删改查
⑴ 查
由于字典是无序的,因此无法通过索引的方式查看字典的元素,同时,也无法对字典进行分片操作。
查看字典指定值可以借助对应的键:
dictionary[key]
- “dictionary”为字典。
- “key”是键名。
上述方法如果查找的是不存在的元素,则会抛出异常。
dictionary.get(key)
- “dictionary”为字典。
- “key”是键名。
该方法如果查找的是不存在的元素,则返回“None”。
⑵ 改
修改字典的值只需要在查看该值之后直接赋上新值即可。
dictionary[key] = new_value
- “dictionary”为字典。
- “key”是修改值的键名。
- “new_value”为修改后的值。
⑶ 增
dictionary[new_key] = new_value
- “dictionary”为字典。
- “new_key”是增加元素(键值对)的键名。
- “new_value”为增加元素(键值对)的值。
⑷ 删
del dictionary[key]
- “dictionary”为字典。
- “key”是键名。
上述方法将直接删除字典指定的元素(键值对)。
dictionary.pop(key)
- “dictionary”为字典。
- “key”是键名。
上述方法将直接删除字典指定的元素(键值对),并返回删除的值。
dictionary.popitem()
- 不需要参数。
上述方法将随机删除字典的一个元素(键值对),并以元组的形式返回删除的键值对,元组的第1个元素为删除的键,第2个元素为删除的值。
⑸ 举例

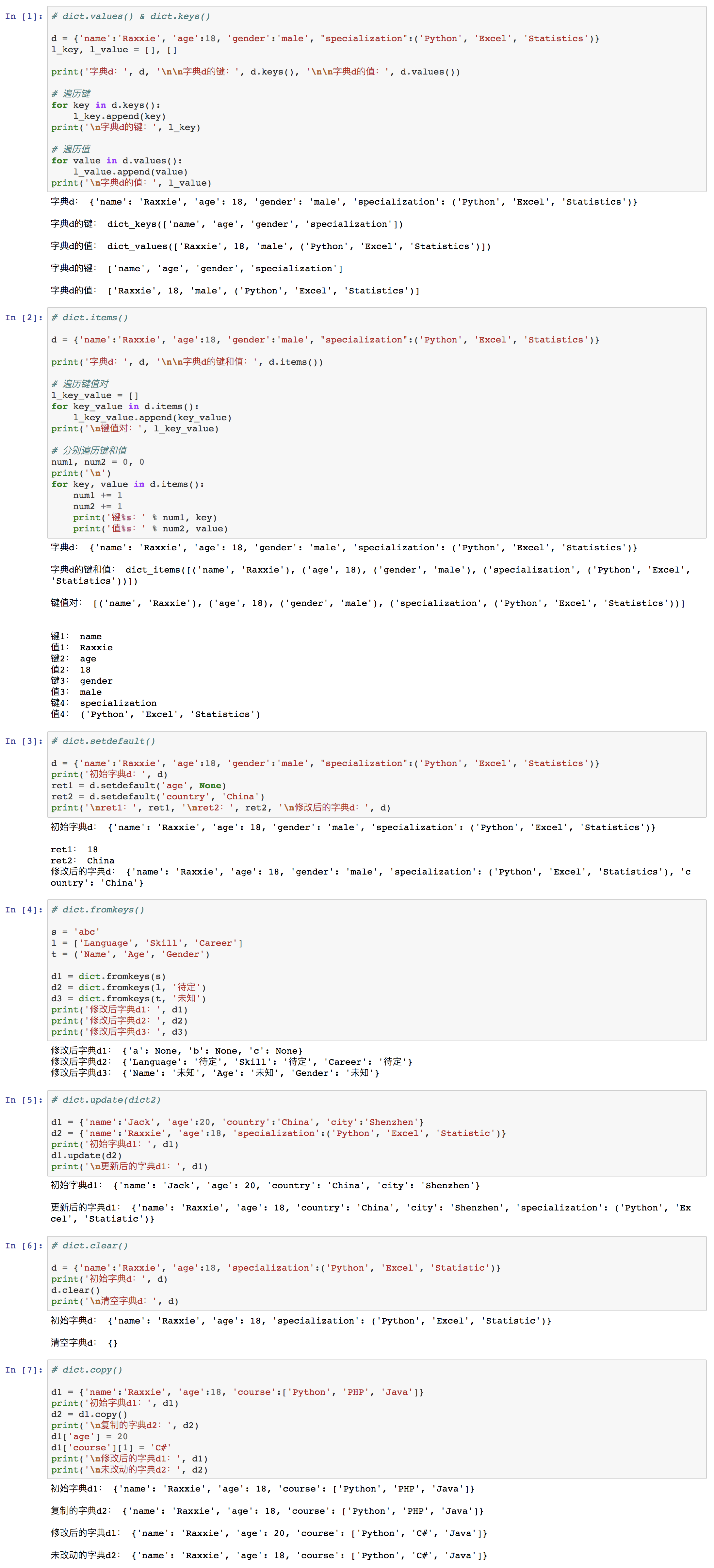
⑤ 字典的属性
⑴ 属性
| 属性 | 含义 | 用法 |
|---|---|---|
| dict.values() | 获取字典中所有的值(可进行遍历) | 不需要参数 |
| dict.keys() | 获取字典中所有的键名(可进行遍历) | 不需要参数 |
| dict.items() | 获取字典中所有的键值对(可进行遍历) | 不需要参数 |
| dict.setdefault(key[, default=None]) | 返回key对应的值 | 如果 key 在 字典中,返回对应的值。如果不在字典中,则插入 key 及设置的默认值 default,并返回 default ,default 默认值为 None。 |
| dict.fromkeys(seq[, default=None]) | 创建新字典,seq的元素作为新字典的键,default作为默认值 | seq为指定序列,其元素作为新字典的键;default可有可无,表示新字典键的默认值。若无default则默认值为None,default值可自定义。 |
| dict.update(dict2) | 把字典dict2的键/值对更新到dict里 | dict2是字典。若dict与dict2有相同的键,则更新dict2的值到dict;若dict没有dict2中的键,则添加dict2的键值对到dict中 |
| dict.clear() | 把字典清空 | 不需要参数 |
| dict.copy() | 浅复制字典 | 不需要参数。原字典修改不可变对象的值,复制的字典值不变;原字典修改可变对象的值,复制的字典其对应值也发生改变 |
⑵ 举例
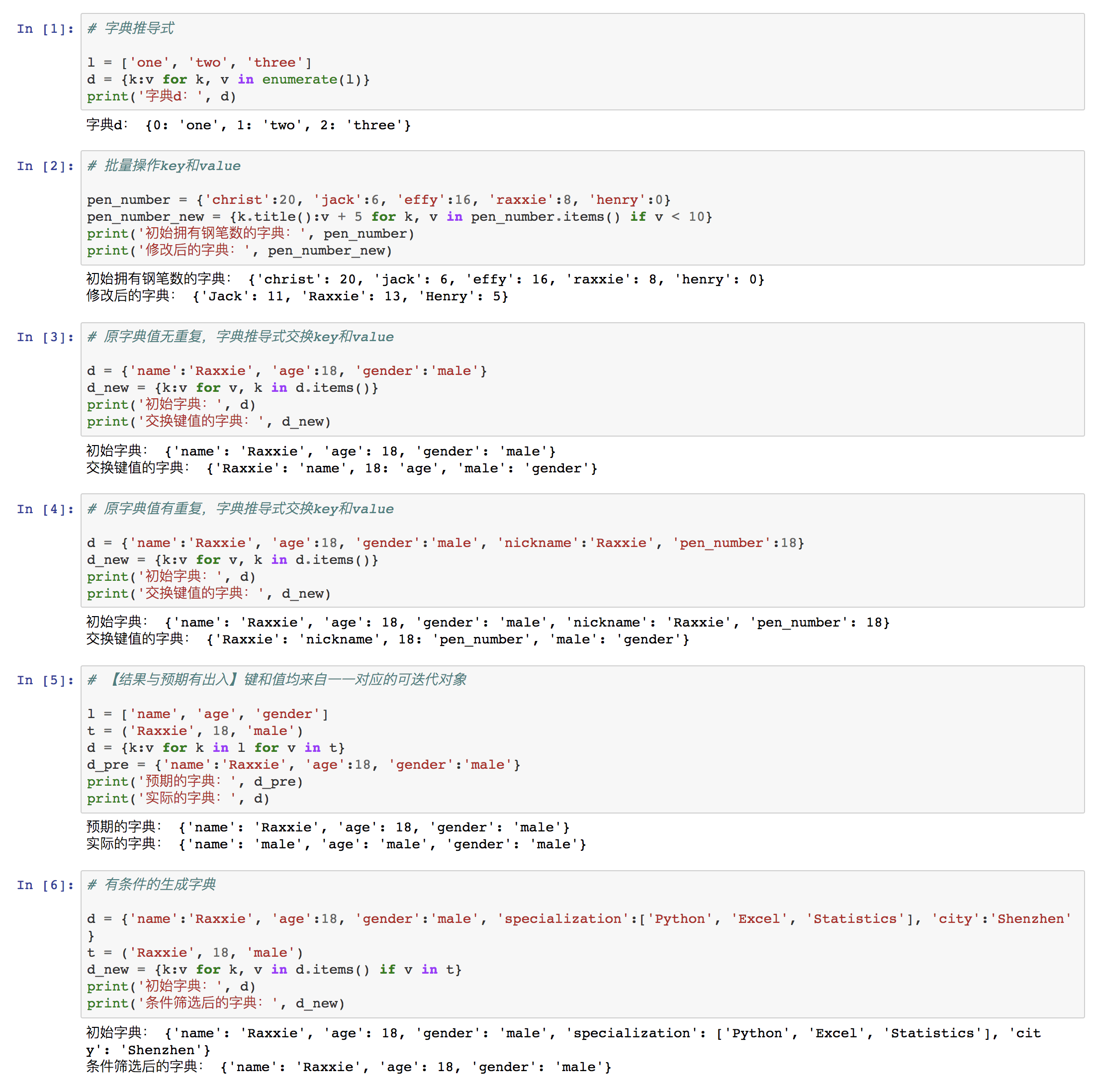
⑥ 字典推导式
字典推导式又称字典生成式或字典解析式,是通过固定语法生成字典的方式。
[<key_expression>:<value_expression> for <key>, <value> in <iterable> if <condtion>]
其中:
“<key_expression>”是字典的键所满足的表达式,也可以只是键本身。
“<value_expression>”是字典的值所满足的表达式,也可以只是值本身。
“<key>”表示字典的键,要与“<key_expression>”中的键名保持一致。
“<value>”表示字典的值,要与“<value_expression>”中的值保持一致。
“<iterable>”是可迭代对象。
“if <condition>”是元素的键和值的取值条件,可有可无。
举例:
三、流程控制语句
1. 条件控制
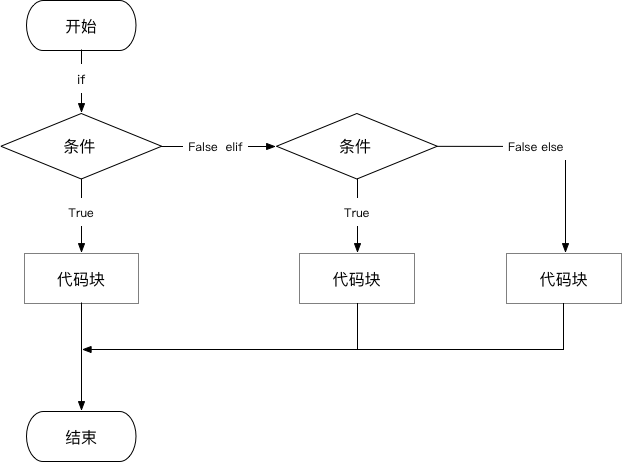
① 语法一:if
if 条件:
代码块
该情况只有一个 if 语句,表示当条件成立时,执行代码块,否则就继续执行主程序。
例如:

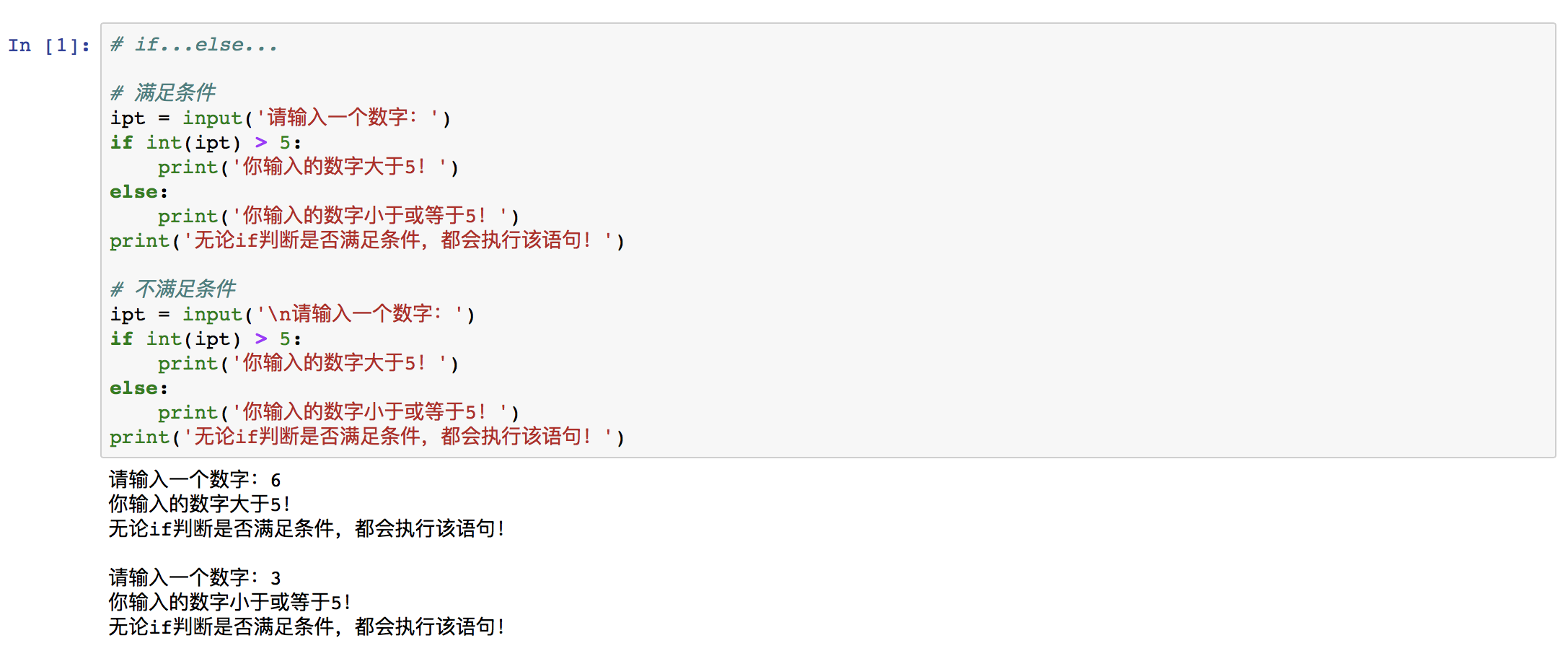
② 语法二:if...else...
if 条件:
代码块1
else:
代码块2
当 if 语句条件成立时,执行 代码块1;否则执行 else 语句的代码块2。然后再继续执行主程序。
例如:
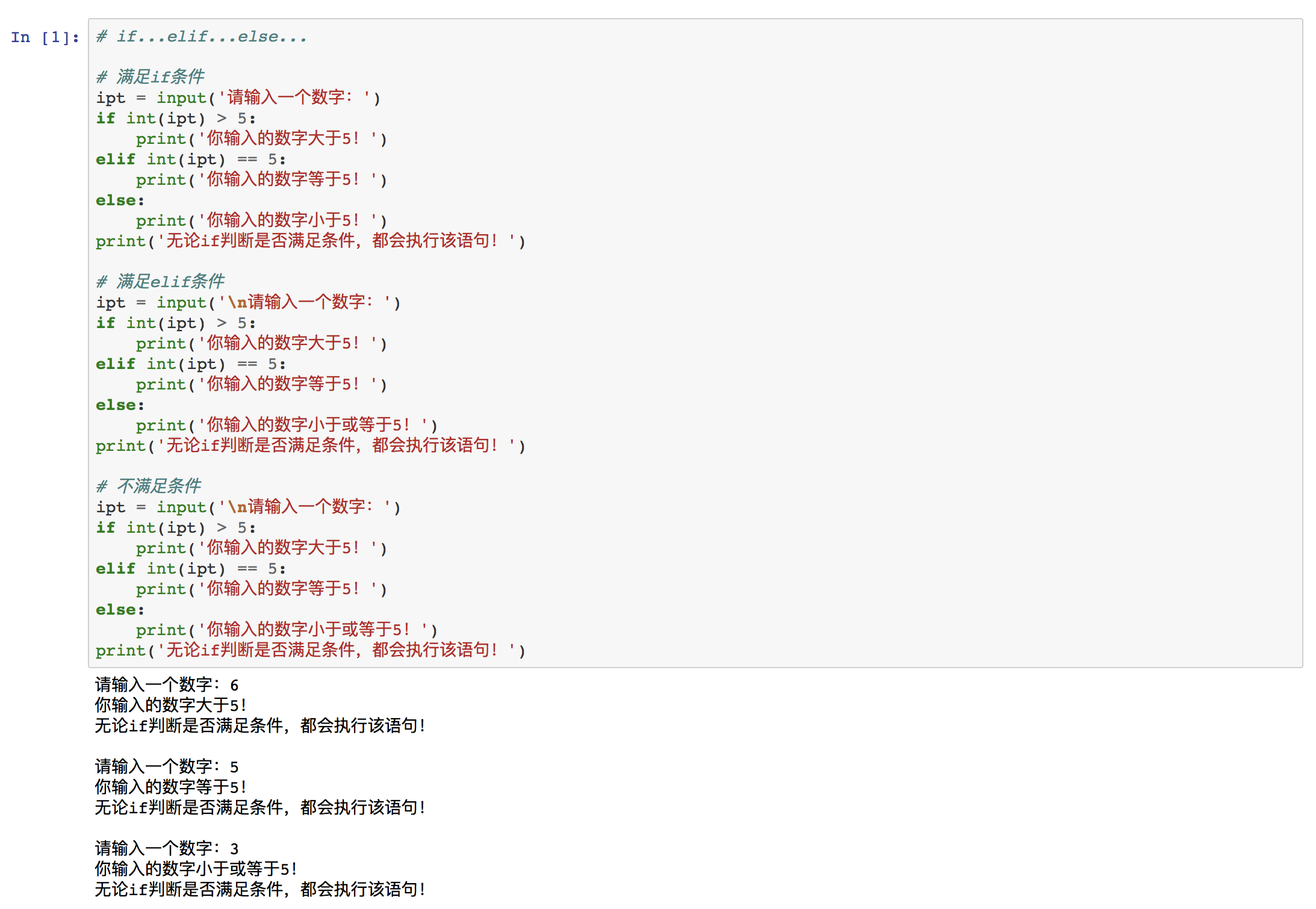
③ 语法三:if...elif...else...
if 条件1:
代码块1
elif 条件2:
代码块2
else:
代码块3
当 if 语句条件1成立时,执行 代码块1;否则判断 elif 语句条件2是否成立,若成立,则执行代码块2;若不成立,则执行 else 语句的代码块3。然后再继续执行主程序。
例如:
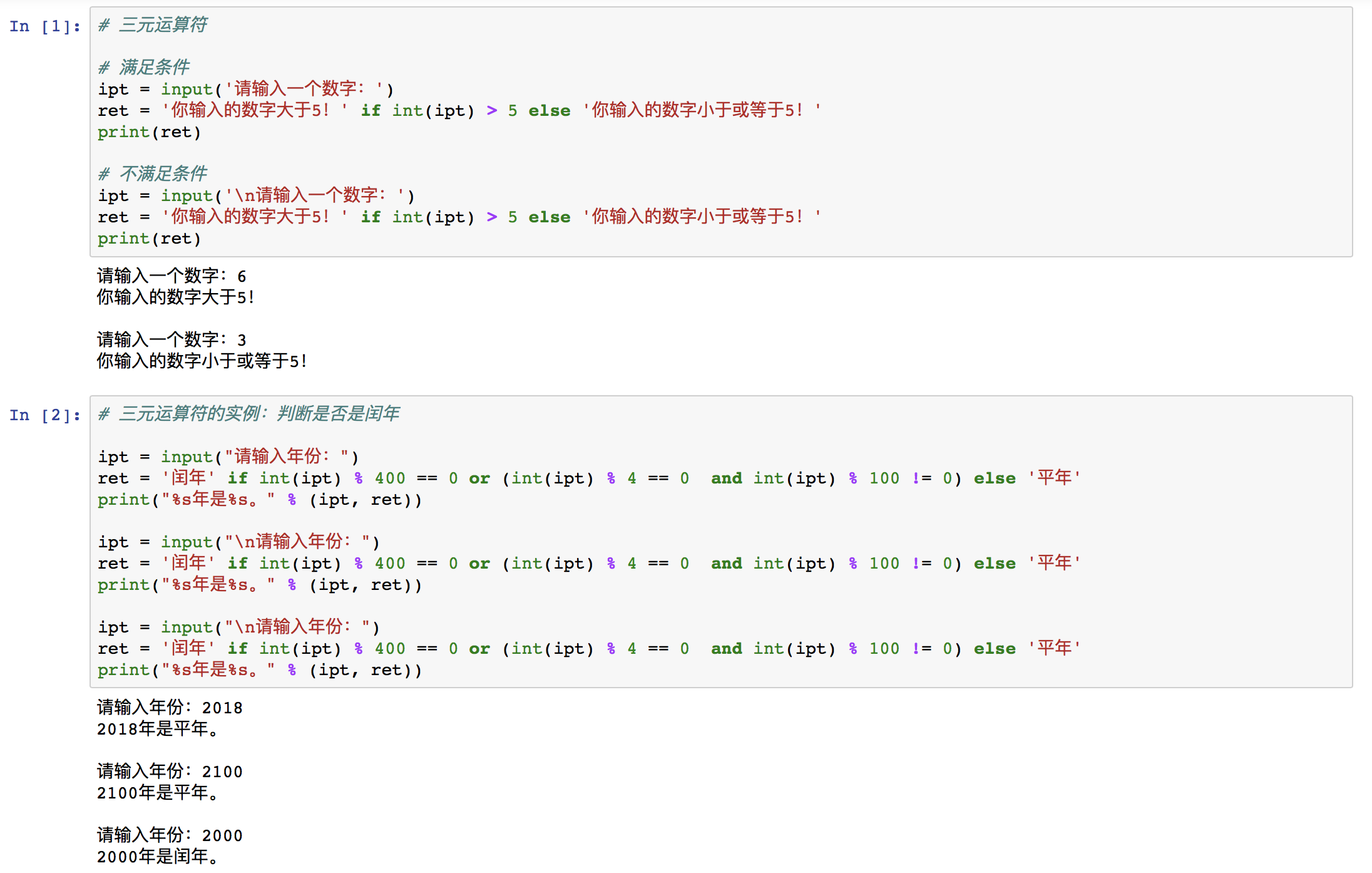
④ 语法四:三元运算符
三元运算符又称三目运算符,主要用于赋值使用。简单的 if...else... 语句可以改写为三元运算符;但当三元运算符的长度超过每行的最大字符限制时,仍要用 if...else... 语句。
value1 if 条件 else value2
当条件成立时取“value1”,当条件不成立时取“value2”。
例如:
⑤ 注意
其中"判断条件"成立时(非零),则执行后面的语句,而执行内容可以多行,以缩进来区分表示同一范围。
else为可选语句,当需要在条件不成立时执行内容则可以执行相关语句,if语句的判断条件可以用>、<、==、>=、<=、!=或布尔值(也可以是1或0)来表示其关系。elif是当判断条件为多个值时才使用。若判断条件为一个,则使用if...else...即可。多个条件判断,只能用
elif来实现。如果一个判断条件中需要多个条件需同时进行判断时,可以使用or,表示多个条件有一个成立时则整个判断条件成立;使用and表示多个条件有一个不成立时则整个判断条件都不成立。-
条件判断的优先级:
- 当if有多个条件时可使用括号来区分判断的先后顺序,括号中的判断优先执行。
-
and和or的优先级低于比较操作符号,即比较操作符在没有括号的情况下会比逻辑操作符要优先判断。
2. 循环语句
① for循环
⑴ for循环流程图
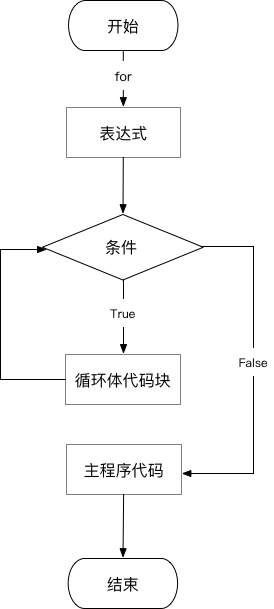
由图可知,表达式只执行1次,然后进行条件判断;只有满足条件才会进入循环,执行循环体代码,并在每次循环体代码执行结束后再度判断条件,直到条件不满足,跳出循环,继续执行主程序,然后结束。
⑵ 语法
for variable in iterable:
<loop body>
else:
<statements>
“variable”表示变量。
“iterable”表示可迭代对象。
“<loop body>”表示循环体代码。
“<statements>”表示跳出
for循环后执行的代码,即条件不满足时执行的代码。该部分可有可无。
语法含义为:如果变量“variable”在“iterable”当中,执行循环体代码块“<loop body>”;否则执行 else 语句代码“<statements>”。
⑶ range()函数
在 for 循环的语法中,“iterable”部分常用 range() 函数,用于获取数字。
range([start_num, ]end_num[, step])
- “start_num”表示起始数字。
- “end_num”表示截止数字。
- “step”表示步长。
- 如果
range()函数中只有1个参数,那么该参数表示截止数字,起始数字将默认从0开始,步长默认为1。 -
range()函数的取值是遵循“前闭后开”的原则,即[start_num, end_num)或start_num ≤ value < end_num。
⑷ 举例
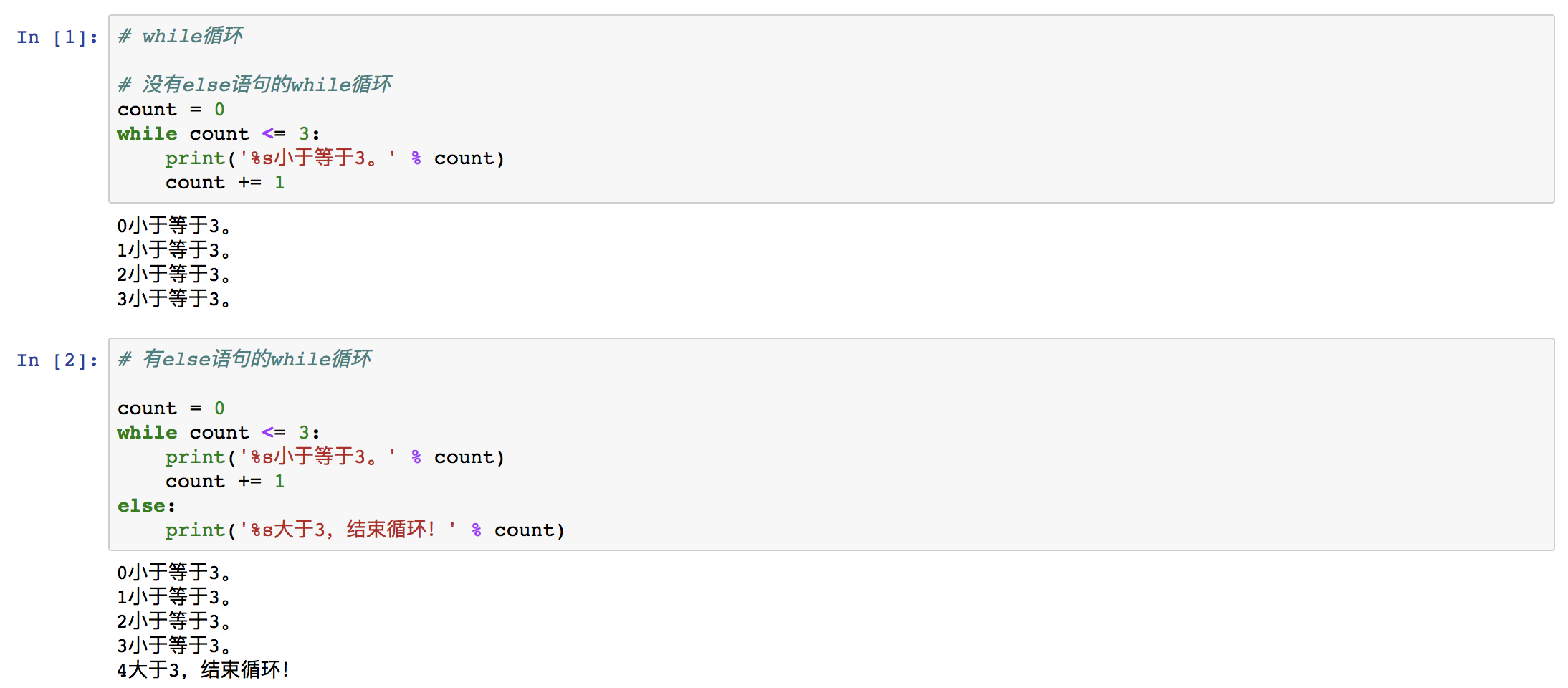
② while循环
⑴ while循环流程图
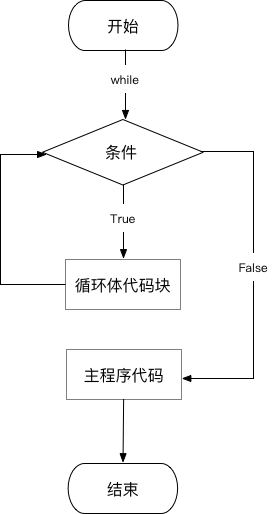
由图可知,当满足 while 后的判断条件时,将会进入循环体,并执行循环体代码。每一次循环体代码执行完毕,都会再次执行判断条件,直到不满足判断条件,就跳出循环体,继续执行主程序代码,然后结束。
⑵ 语法
while <condition>:
<loop body>
else:
<statements>
“<condition>”表示判断是否进入循环体的条件。
“<loop body>”表示循环体代码。
“<statements>”表示当跳出循环体时执行的代码。
else语句可有可无。
代码含义是:当满足循环判断条件“<condition>”时,进入循环体,执行代码“<loop body>”;直到不再满足判断条件“<condition>”,便执行 else 语句的代码“<statements>”。
⑶ 简单语句组
while (<condition>): <loop body>
类似于三元运算符,当 while 的判断条件“<condition>”和循环体“<loop body>”非常简单时,可以使用上述语法格式来构造 while 循环。
例如:
⑷ 无限循环
当条件永远为真时,即条件永远满足,这时进入循环体将无法自动结束循环,想要结束循环体只能按 CTRL C 来终止运行。这种情况叫做无限循环,也称为死循环。
想要构造无限循环,可以自定义一个永远满足的条件,也可以简单的把判断条件设置为 1 或 True。
无限循环的使用场景:
- 游戏界面的实时刷新。
- 服务器上客户端的实时请求。
- ......
例如:
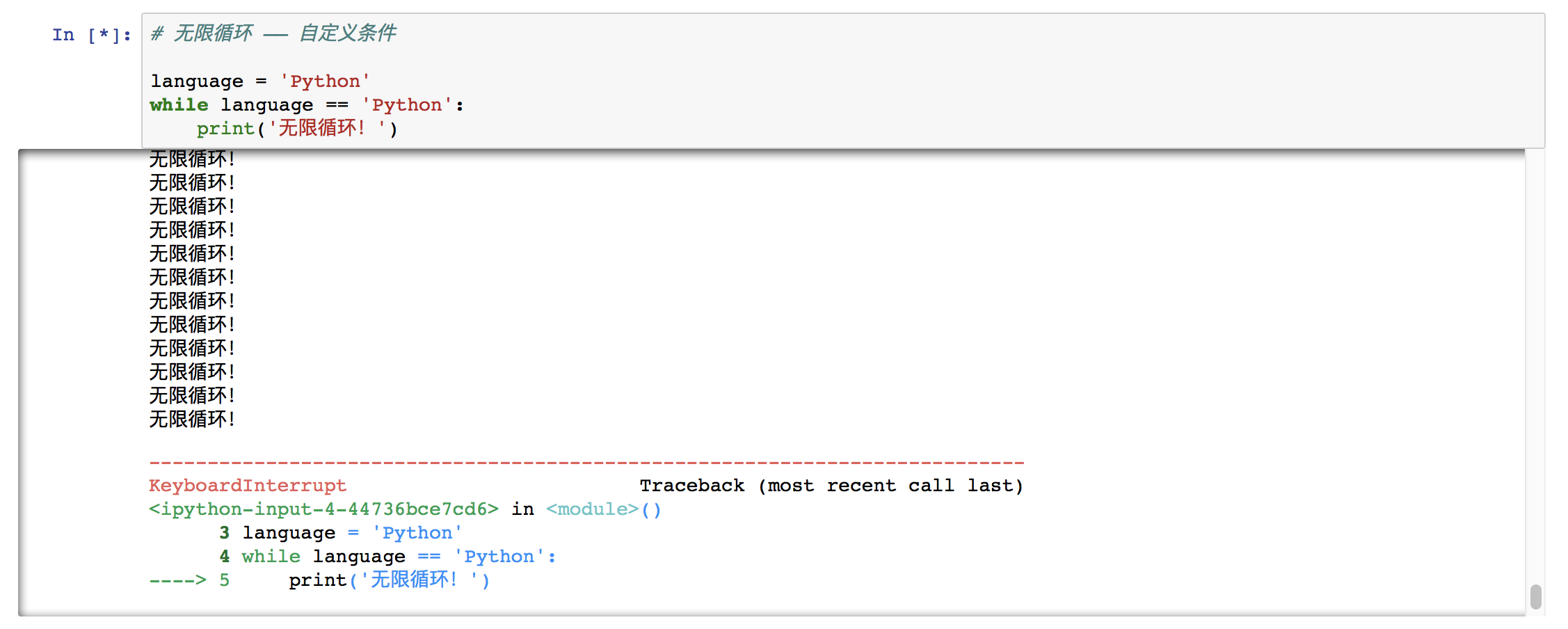
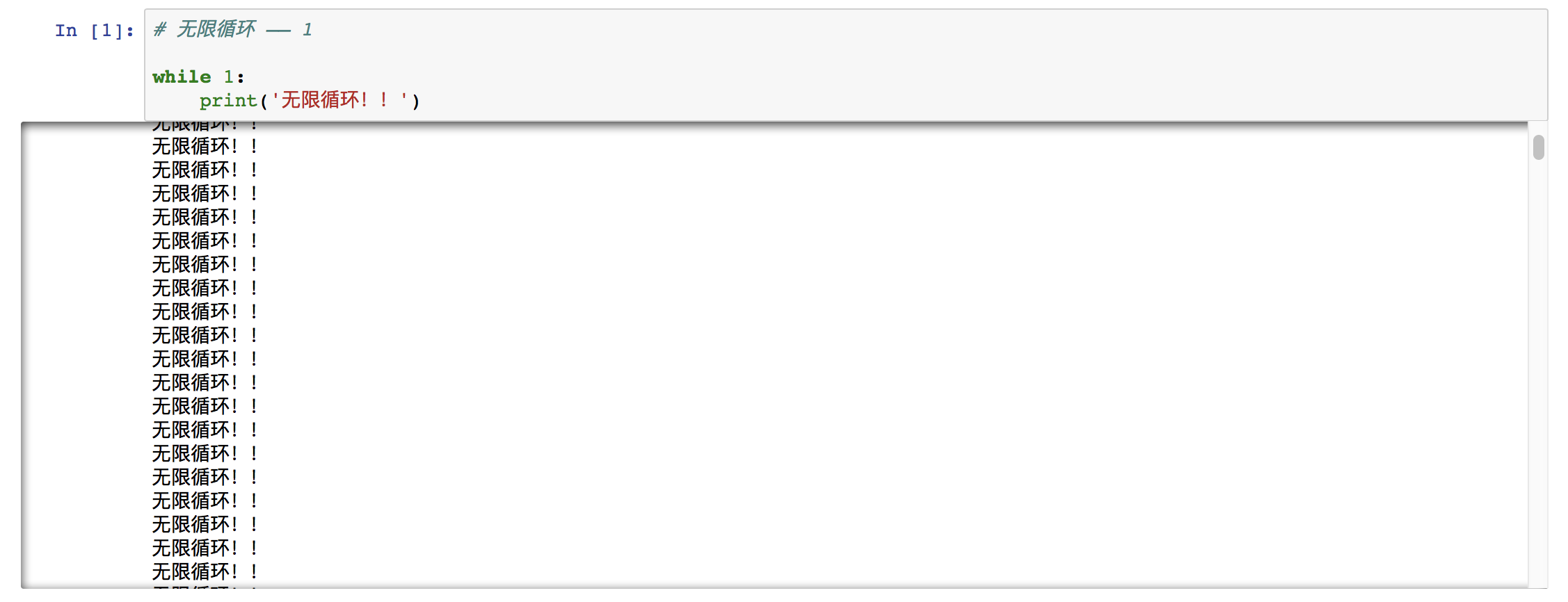
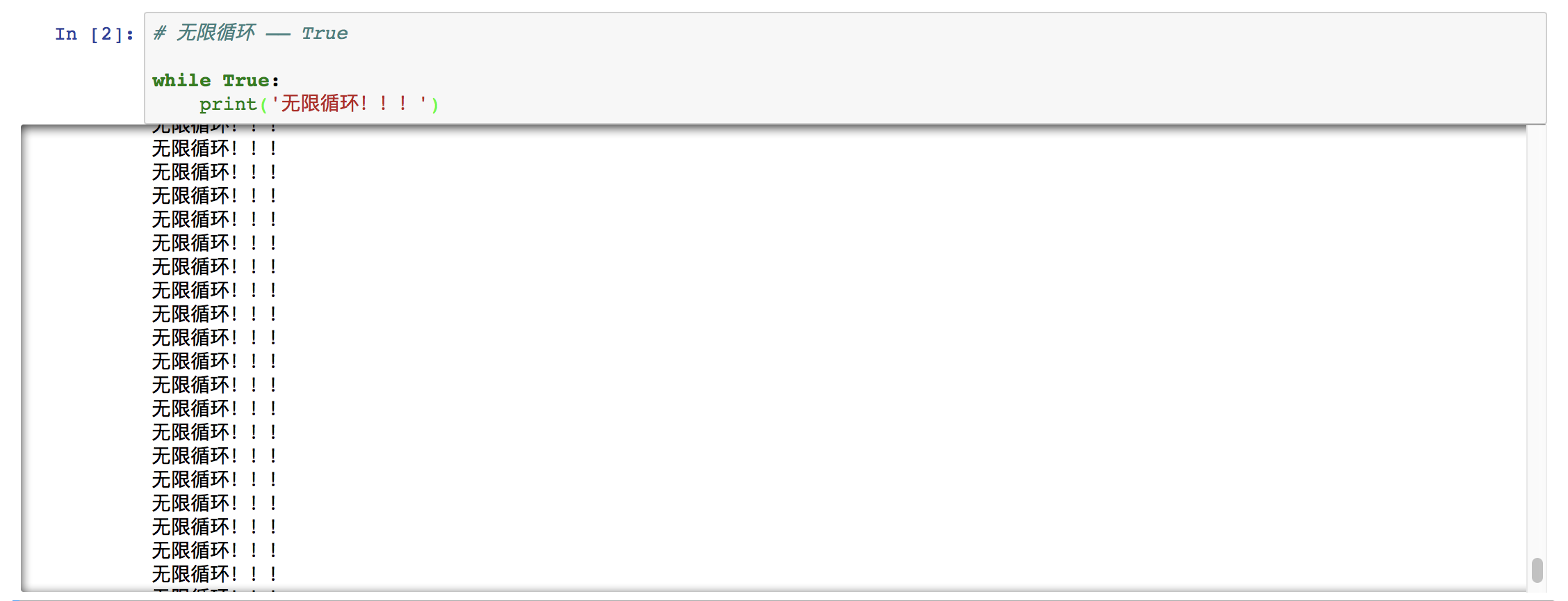
⑸ 举例
③ continue 和 break
contiue 语句的作用是跳过当前循环,执行下一轮循环。如果当前循环后边仍有代码未执行,那么也直接跳到下一轮循环。可以用于 for 和 while 循环中。
break 语句的作用是跳出整个循环体。如果接下来仍有循环未进行,那么不再执行余下循环,跳出整个循环体。可以用于 for 和 while 循环中。
例如:

④ pass
pass 是空语句,是为了保持程序结构的完整性。
pass 不做任何事情,一般用做占位语句。
例如:
class Test(object):
pass
def test():
pass
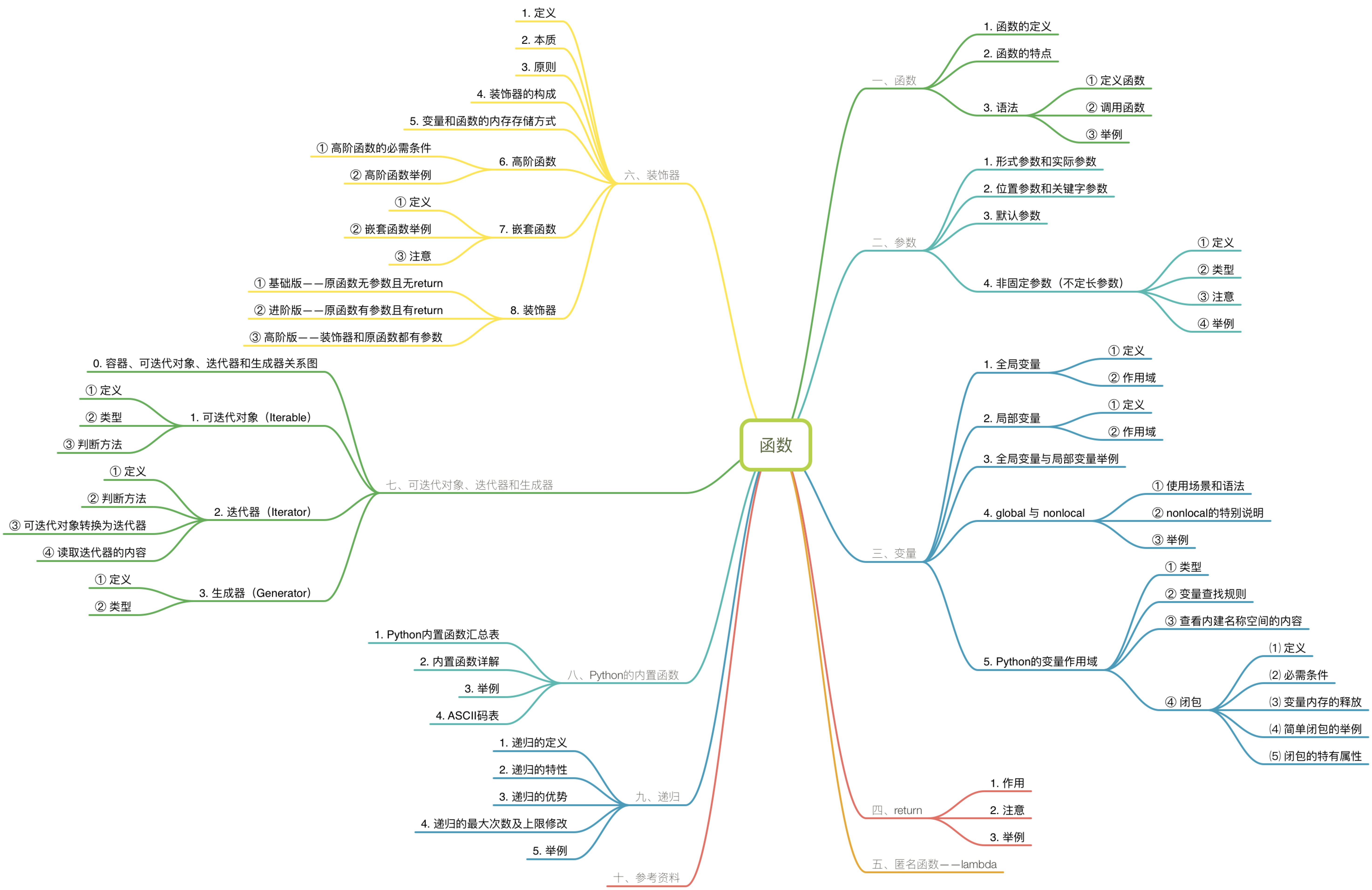
一、函数
1. 函数的定义
函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段。
能够被称为函数的代码段,具有以下特点:
- 代码段被封装。
- 具有特定的名称作为函数名。
- 可以通过调用函数名来执行函数。
2. 函数的特点
在工作当中,一个项目都包含多种功能,而项目的正常运行也都是各个功能发挥着各自的作用。然而,某些功能或许在项目进行过程中会被反复使用,那么被重复使用的功能代码段的反复出现将降低代码的运行效率。这时,使用函数将该功能封装,并在每一使用该功能时都调用特定的函数名,不仅提高了代码的运行效率,也减少了重复代码。在代码后期的维护过程中,只需对函数代码进行维护,由于函数的调用方式是不变的,不需要对其他函数调用之处进行重复维护,降低了维护复杂度。被封装为函数的代码段在日后的项目当中也可以被使用或加入到其他功能当中,具有较强的扩展性。
简言之,使用函数的优势在于:
- 减少重复代码。
- 代码便于维护。
- 程序可扩展性强。
3. 语法
① 定义函数
def 函数名([参数1, 参数2, ..., 参数N]):
"""
函数的解释说明文字
"""
函数体
[return 返回值]
-
必需要素:
- 以
def开头。 - 确定的函数名,可自定义,通常以小写字母开头,并与
def以空格隔开。 - 在函数名后必须有英文半角的括号()和冒号。
- 函数体中的代码前均需缩进。
- 以
-
非必需要素:
- 参数为非必需要素,函数可以没有参数,也可以有1个或多个参数。多个参数之间以英文半角逗号隔开。
- 函数的解释说明文字为非必需要素,但建议为函数匹配相应的解释说明。解释说明内容前后均要有3个英文半角单引号或双引号。
-
return 返回值为非必需要素。
② 调用函数
函数名([参数1, 参数2, ..., 参数N])
-
必需要素:
- 被调用函数的函数名。
- 紧接着函数名后的英文半角括号()。
非必需要素:参数。须遵循定义函数时的参数个数,即调用函数时参数的个数需要与定义函数时参数的个数相等,否则会报错。
③ 举例
二、参数
1. 形式参数和实际参数
形式参数:形式参数又称形参,是在定义函数时写在函数名后的括号中的参数。形参变量只有在被调用时才分配内存单元,在调用结束时,即刻释放所分配的内存单元。因此,形参只在函数内部有效。函数调用结束返回主调用函数后则不能再使用该形参变量。
实际参数:实际参数又称实参,是在调用函数时卸载函数名后的括号中的参数,用于把实际的参数值传入函数中进行执行和运算的参数。实参可以是常量、变量、表达式、函数等。无论实参是何种类型的量,在进行函数调用时,它们都必须有确定的值,以便把这些值传送给形参。因此应预先用赋值,输入等办法使参数获得确定值。
-
例如:
形式参数和实际参数
2. 位置参数和关键字参数
位置参数:在调用函数时,实参的顺序应与定义函数时形参的顺序保持一致,因为Python在传参时,是按照顺序将实参传递给形参的。因此,按顺序传参的方法就是位置传参。
关键字参数:在参数传递时,若不想按顺序传参,可以使用
形参=值的方式作为实参进行参数传值。这种传参方法称为关键字传参。关键字传参不考虑形参的顺序,因为该方法指明了将为某个形参传递确切的值。注意:位置传参和关键字传参可以结合使用。但是,关键字传参之前的参数传值可以是位置传参;一旦出现关键字传参,则后边的参数必须用关键字传参。
-
例如:
位置参数和关键字参数
3. 默认参数
默认参数:默认参数指的是在形参中为参数赋缺省值。在实参传参时,若未给默认参数传值,则使用缺省值;若为默认参数传值,则使用实参的值。
注意:默认参数必须位于所有非默认形参之后。
-
例如:
默认参数
4. 非固定参数(不定长参数)
① 定义
非固定参数:又称不定长参数。当定义函数时无法预估需要传入多少个实参时,可以使用非固定参数来接受参数的传递,由于无法预知参数的个数,因此这种参数也称为不定长参数。
② 类型
元组型:形参名前有1个星号(*) 的形参即为元组类型的不定长参数。加了星号(*)的变量名会存放所有未命名的变量参数,即在传参时,若传入多个参数,这些参数将会是一个元组;若未传入参数,则这个参数为一个空元组。
字典型:形参名前有2个星号(**)的形参即为字典类型的不定长参数,也称关键字类型不定长参数。类似于元组型不定长参数,字典型不定长参数在传参时,可以传入任意个参数,但传递参数的方式只能是关键字传参,即
实参1=值1, 实参2=值2, ..., 实参N=值N。传递的参数将是一个由“键值对”构成的字典,其中,“键”即是实参名,“值”即是为实参赋的值。
③ 注意
元组型不定长参数和字典型不定长参数在星号之后的形参名可以自定义为任意名称。但我们习惯把元组型用
*args,把字典型用**kwargs表示,分别为“arguments”和“keyword arguments”的缩写。元组型不定长参数和字典型不定长参数可以和普通参数结合使用,其位置顺序应当遵循:普通参数,默认参数,元组型不定长参数,字典型不定长参数。在上述位置顺序中,不建议使用默认参数。
元组型不定长参数和字典型不定长参数既可以单独使用,也可以结合使用,但字典型不定长参数必须放在元组型不定长参数之后。
④ 举例
三、变量
1. 全局变量
① 定义
在函数外部定义的变量称为全局变量。
② 作用域
全局变量是在整个 .py 文件中声明的,作用于整个 .py 程序,全局范围内都可以访问。
2. 局部变量
① 定义
在函数内部定义的变量称为局部变量。
② 作用域
局部变量是在某个函数中声明的,只能在该函数中调用它。
3. 全局变量与局部变量举例
4. global 与 nonlocal
① 使用场景和语法
在 .py 程序中,当函数内部定义的局部变量与某个全局变量重名时,是无法直接修改全局变量的,Python将会把函数内的局部变量视为新定义的变量。如果想实现在函数内部修改全局变量,需要在函数内部使用 global 变量名 语法来声明。
同样,如果函数1中嵌套了函数2,函数2中存在于函数1中重名的变量。虽然函数1中的变量相对于函数2来说类似“全局变量”,但严格意义上,它还是局部变量,因此不能直接在函数2中使用 global 语法声明并对变量进行修改。若想要修改变量,需要使用 nonlocal 变量名 语法来声明。
② nonlocal的特别说明
nonlocal只存在在Python 3.x的版本当中,在Python 2.x的版本中无法使用。
③ 举例
5. Python的变量作用域
① 类型
在Python中,变量作用域一共有4种,分别是:
- L(Local):局部作用域。
- E(Enclosing):闭包函数外的函数中。
- G(Global):全局作用域。
- B(Built-in):内建作用域。
② 变量查找规则
Python的变量查找规则为:L → E → G → B。
即:当Python无法在局部中找到变量时,便会查找局部外的局部中找(如闭包函数外的函数中),如果还找不到,则会查找全局,最后查找内建。
③ 查看内建名称空间的内容
import builtins
dir(builtins)
④ 闭包
⑴ 定义
函数中嵌套了一个函数。最外层的函数我们称为“外部函数”,嵌套在内的函数我们称为“内部函数”。内部函数中引用了外部函数的变量,但不能引用全局变量,且外部函数的返回值为内部函数的函数名。此时,便构成了一个闭包。
简言之,当函数满足以下结构时,我们可以将其视为闭包。
def outer_function():
"""
外部函数
"""
outer_var = value # 定义变量 outer_var,value可以是任何值
def inner_function():
"""
内部函数
"""
print('引用变量:', outer_var) # 引用外部函数的变量
return inner_function # 外部函数的返回值为内部函数名
⑵ 必需条件
必须存在函数嵌套。
内部函数必须引用外部函数的变量。
内部函数必须不能引用全局变量。
外部函数的返回值必须是内部函数的函数名。
⑶ 变量内存的释放
通常情况下,当一个函数运行结束,函数内部的所有东西都会释放掉,还给内存,函数的局部变量也会因此消失。然而,闭包是一种特殊情况,如果外部函数在结束时发现其变量会在内部函数中被使用,就会把这个变量绑定给内部函数,然后再结束自己的运行。
⑷ 简单闭包的举例
⑸ 闭包的特有属性
只要是闭包,都有 __closure__ 属性。该属性返回闭包应用外围作用域(即外部函数中)的变量内存地址,结果是一个元组。语法为:外部函数().__closure__ 。
如果函数不是闭包,则 __closure__ 返回“None”。
可以通过打印 外部函数().__closure__[数字].cell_contents 来获取外部函数变量的值。其中,“数字”即为元组元素的索引,从0开始。
例如:
四、return
1. 作用
return 返回值 用于获取函数的执行结果。
2. 注意
① 在函数的执行过程中,遇到 return 即停止运行函数并返回 return 的值。return 后如果还有代码,则不会再执行。因此,return 也意味着当前函数的结束。
② 当函数没有定义 return 语句时,Python在执行函数时默认将返回值设为“None”,等同于 return None 。
3. 举例
五、匿名函数——lambda
六、装饰器
1. 定义
装饰器是用于装饰其他函数,为其他函数增加附加功能的函数。
2. 本质
装饰器的本质是函数。
3. 原则
① 不能修改被装饰函数的源代码。
② 不能修改被装饰函数的调用方式。
4. 装饰器的构成
高阶函数 + 嵌套函数 ⇒ 装饰器
5. 变量和函数的内存存储方式
如图所示,内存中有着若干“房间”用于存放数据。当为一个变量赋值后,赋的值将被存放在内存中,生成固定的内存地址,而变量名便成了存放该值的“房间”的“门牌号”。只有被赋予变量的值,才会保留在内存当中;如果内存中的值没有赋予变量,或被赋予变量后被删除了变量,Python的内存回收机制会自动将该值的内存地址清理掉。
例如: a = 1 中,“a”为变量名,“1”是赋予变量“a”的值。因此,“a”即为“1”的“门牌号”。此时,“1”拥有独一无二的内存地址,而变量“a”只是指向该内存地址。“1”也可以被赋给其他变量,方式可以是多种的,如 b = 1 或 b = a,这些均表示变量“b”指向“1”的内存地址。因此,当引用“a”或“b”时,其实是Python查找其指向的内存地址,从而找到“1”的。如果想删除变量,可以使用 del 变量名,如 del a,此时,“a”将会被删除,如果再删除“b”(del b),那么“1”的内存地址将会被Python回收。
同理,函数也可被视为“变量”。
由于函数的基本语法结构为:
def 函数名():
函数体
这等同于 函数名 = 函数体 这样的“变量”赋值,不同之处在于,变量可以被直接引用,而函数需要通过 函数名() 的方式被调用。
如果函数为匿名函数,那么整个匿名函数将被分配一个内存地址,当使用完毕后,其内存地址将被Python回收。若想保留其内存地址,可以将匿名函数整体赋给一个变量,此时,变量名即为这个匿名函数的“门牌号”,匿名函数的内存地址也因此将被保留下来。
总而言之,只有当值(函数体)被赋予变量(具有函数名)时,其内存地址才将会保留下来,否则将会被Python的内存回收机制回收。通俗地讲,只有具有“门牌号”的“房间”才会被保留“地址”。
6. 高阶函数
① 高阶函数的必需条件
把一个函数(函数1)的函数名作为实参传递给另一个函数(函数2)。 可以实现在不修改被装饰函数源代码的前提下为其增加功能。
函数2的返回值是函数1的函数名。 可以实现不修改原函数的调用方式。
② 高阶函数举例
7. 嵌套函数
① 定义
顾名思义,嵌套函数就是在一个函数的函数体内定义另一个函数。
② 嵌套函数举例
③ 注意
嵌套函数中,不能直接调用被包含的函数,需要在外部的函数体内调用被包含的函数,然后在整个函数外对外部函数进行调用。
8. 装饰器
① 基础版——原函数无参数且无return
# 定义装饰器
def decorator(function):
def body():
函数体
function()
return body
# 使用装饰器
@decorator
def function():
函数体
上述函数名均可自定义。
@decorator ⇒ function = decorator(function) = body-
举例:
装饰器基础版
② 进阶版——原函数有参数且有return
# 定义装饰器
def decorator(function):
def body(*args, **kwargs):
函数体
ret = function(*args, **kwargs)
return ret
return body
# 使用装饰器
@decorator
def function(参数1, 参数2, ..., 参数N):
函数体
return 返回值
上述函数名均可自定义。
@decorator ⇒ function = decorator(function) = bodyprint(function(参数1, 参数2, ..., 参数N))既执行了原函数function,又执行了为原函数增加的功能body函数,同时也打印了原函数function的返回值。原函数名function将作为实参传入decorator函数;原函数的参数将作为实参传入body函数。
-
举例:
装饰器进阶版
③ 高阶版——装饰器和原函数都有参数
# 定义装饰器
def decorator(*dec_args, **dec_kwargs):
def function(func):
def body(*func_args, **func_kwargs):
函数体
return func(*func_args, **func_kwargs)
return body
return function
# 使用装饰器
@decorator(参数1, 参数2, ..., 参数N)
func(参数1, 参数2, ..., 参数N)
上述函数名均可自定义。
装饰器参数将作为实参传给decorator函数;原函数名func将作为实参传给function函数;原函数的参数将作为实参传入body函数。
body函数的返回值为原函数func及其参数,因此,可以调用并打印原函数的返回值。
具体应用场景:页面登录。
-
举例:
装饰器高阶版
七、可迭代对象、迭代器和生成器
0. 容器、可迭代对象、迭代器和生成器关系图
1. 可迭代对象(Iterable)
① 定义
可以直接用for循环的对象被称为可迭代对象(Iteralbe)。
② 类型
可迭代对象主要包括:
容器:字符串(str)、列表(list)、字典(dict)、集合(set)。
生成器(generator)以及带yiled字段的函数。
③ 判断方法
from collections import Iterable
isinstance(object, Iterable)
注意:
- “Iterable”首字母须大写。
- “object”是需要被判断的对象。
2. 迭代器(Iterator)
① 定义
可以被 next() 函数调用(或具有 __next__() 方法)并不断返回下一个值的对象被称为迭代器(Iterator)。
注意:所有的迭代器均为可迭代对象;但不是所有的可迭代对象都是迭代器。
② 判断方法
from collections import Iterator
isinstance(object, Iterator)
注意:
- “Iterator”首字母须大写。
- “object”是需要被判断的对象。
③ 可迭代对象转换为迭代器
iter(object)
- 注意:“object”必须是可迭代对象。
④ 读取迭代器的内容
读取迭代器的方法有2个:
next()或__next__()for循环遍历
注意:当使用 next() 或 __next__() 读取迭代器内容时,每次只能读取1个值,且下一次读取将从下一个值读起,无法读取前边的值。当所有值都被读取完毕,再运行 next() 或 __next__() 将会抛出“StopIteration”异常。
3. 生成器(Generator)
① 定义
生成器是一种特殊的迭代器,用于惰性地生产数据。生成器一定是迭代器和可迭代对象,反之不一定成立。
生成器均可用 next() 或 __next__() 以及 for循环来读取值。
② 类型
生成器表达式(Generator Expression):类似于列表推导式(也称列表生成式),生成器表达式是将列表推导式的“[]”换成“()”。
生成器函数(Generator Function):顾名思义,生成器函数类似于函数。凡是函数体中带有
yield字段的函数,均为生成器函数。需要注意的是,普通函数的结束标志是return 返回值,而生成器函数的中断标志是yield,当下一次读取值时,将继续从上一次的yiled处开始往下读取。
八、Python的内置函数
1. Python内置函数汇总表
2. 内置函数详解
菜鸟教程:Python内置函数
3. ASCII码表
九、递归
1. 递归的定义
若在函数内部调用这个函数自身,则该函数被称为递归函数。
2. 递归的特性
① 必须有一个明确的结束条件。
② 每次进入更深一层递归时,问题规模相比上次递归都应有所减少。
③ 相邻两次重复之间有紧密的联系,前一次要为后一次做准备,通常前一次的输出就作为后一次的输入。
④ 递归效率不高,递归层次过多会导致栈溢出。在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出。因此,递归又被称为“用空间换时间”。
3. 递归的优势
递归函数的优点是定义简单,逻辑清晰。理论上,所有的递归函数都可以写成循环的方式,但循环的逻辑不如递归清晰。
4. 递归的最大次数及上限修改
递归的最大次数在1000次左右,根据问题的复杂度不同,递归次数上限也有浮动。当超过递归次数上限时,Python将会抛出异常:“RuntimeError: maximum recursion depth exceeded”。
递归次数上限的修改:
import sys
sys.setrecursionlimit(num)
其中,“num”为自定义递归次数的上限值。
需要注意的是,递归次数的上限并不是无限大的,sys.setrecursionlimit(num) 只是修改解释器在解释时允许的最大递归次数,此外,限制最大递归次数的还和操作系统有关。
非常不建议修改递归次数的上限值。
5. 举例
- 猴子吃桃问题:猴子摘下若干桃子。第1天吃桃子总数的一半,然后又多吃1个,第2天吃剩下桃子的一半,然后又多吃1个,并在以后的每一天都吃剩下桃子的一半多1个。第10天,只剩下1个桃子。求第一天共摘桃子多少个?

一、定义
1. 模块
本质:模块的本质是
.py结尾的Python文件。用途:从逻辑上组织Python代码(变量、函数、类、逻辑),为了实现一个功能。
名称:文件名为
name.py的文件其模块名为name。
2. 包
本质:包的本质是一个目录,但必须带有一个
__init__.py文件。用途:从逻辑上组织模块。
二、导入模块
1. 导入单个模块
import module_name
- 注意:“module_name”不加“.py”后缀
2. 导入多个模块
import module_name1, module_name2, module_nameN
- 注意:“module_name”之间以英文半角逗号隔开。
3. 导入模块的所有内容
from module_name import *
- 注意:不建议使用这个方法。当“module_name”中的方法(函数)名与当前文件的方法(函数)名相同时,若调用重名方法(函数)时,需视情况而决定调用哪个方法(函数)。
⓪ 例:名为“module_test”的模块内容
def greeting():
print("Welcome to Module_test File!")
① 调用当前文档的方法(函数)
- 导入模块之前调用重名方法(函数)
def greeting():
print("Welcome to Main File!")
greeting()
from module_test import *
运行结果为:
Welcome to Main File!
- 导入模块后,在当前文档的重名方法(函数)之后调用重名方法(函数)
from module_test import *
def greeting():
print("Welcome to Main File!")
greeting()
运行结果为:
Welcome to Main File!
② 调用导入模块的方法(函数)
- 导入模块之后在当前文件的重名方法(函数)之前调用重名方法(函数)
from module_test import *
greeting()
def greeting():
print("Welcome to Main File!")
运行结果为:
Welcome to Module_test File!
- 在当前文件的重名方法(函数)之后导入模块,并调用重名方法(函数)
def greeting():
print("Welcome to Main File!")
from module_test import *
greeting()
运行结果为:
Welcome to Module_test File!
4. 导入模块的特定内容
from module_name import function_name
- 注意:
- “module_name”为引入的模块名。
- “function_name”为从模块中引入的方法(函数)名。
- 如果引入的方法(函数)名与当前文件的方法(函数)名重复,则可以使用as来命名别名。即:
from module_name import function_name as alias, 其中“alias”可以被自定义的任意名称所替换。
5. 导入包中的模块
因为导入包的本质是执行包中的 __init__ 文件,因此,如果要导入包中的其他模块,需要在包中的 __init__ 文件中先导入模块,再在当前文档中导入包即可。
- 注意:
直接在
__init__文件中导入包中的模块会报错,即import module_name的语法会报错,需要使用from . import module_name。其中,“.” 指的是__init__文件所在的当前目录。若当前文件与包不在同一级目录,则需要先将包所在的目录路径添加在环境变量(路径列表)中。具体方法参照“三、import本质(路径搜索和搜索路径)”中的“3. 导入模块的搜索路径”
三、import本质
1. 导入模块的本质
就是把模块的Python文件解释一遍,获取模块中的所有代码。
2. 导入包的本质
就是执行包中的__init__.py文件。
3. 导入模块的搜索路径
- 该部分主要说明Python在导入模块时,搜索模块的路径有哪些;如何获取这些路径;以及如何添加路径以便跨目录导入模块。
① Python搜索模块的路径列表
⑴ 查看路径列表
导入模块时,要注意保证模块与当前文件处于同一级目录;如果模块与当前文件不在同一级目录,则需要把被导入模块的路径添加到Python搜索模块的路径列表当中。Python在导入模块时,是会根据一定的路径集来对每个路径逐个进行搜索。路径集是 sys 模块下的 path 属性,即可以通过打印 sys.path 来查看。 sys.path 是元素为路径的列表,Python将会按照该列表的元素(路径)顺序对模块进行搜索。
⑵ 追加路径
添加路径到路径列表当中可以使用 sys.path.append(路径) 实现,其中“路径”指的是被导入模块的绝对路径,这个语法将会把路径追加到列表的最后。
⑶ 在指定位置添加路径
由于Python搜索模块时是按照路径列表的元素顺序进行搜索的,因此为了避免期间有其他的重名模块被导入,可以使用sys.path.insert(0, 路径)对列表的第1个元素进行路径添加。其中“0”是列表第1个元素的索引,“路径”是被导入模块的绝对路径。
② 当前文件名(相对路径)
通过打印
__file__可以获取包含当前文件相对路径的文件名,即:print(__file__)。PyCharm中执行此命令则会获取包含当前文件绝对路径的文件名。因此建议使用vim编辑器来测试。
③ 当前文件名(绝对路径)
通过使用 os 模块中 path.abspath 属性可以获取包含当前文件绝对路径的文件名,语法为 print(os.path.abspath(__file__))。
④ 当前文件所在目录名(相对路径)
通过使用
os模块中path.dirname属性可以获取包含当前文件相对路径的文件名,语法为print(os.path.dirname(__file__))。注意:其输出结果取决于执行Python文件命令时所处位置。例如:名为
test.py的Python文件其内容为print(os.path.dirname(__file__),且该Python文件的绝对路径为~/Desktop/test.py。那么如果在~/Desktop/位置中执行文件,则结果为空;如果在~/中执行文件,则结果为Desktop。以此类推。-
例:
当前文件所在目录名(相对路径)
⑤ 当前文件所在目录名(绝对路径)
通过结合第③步和第④步可以获取含有当前文件所在目录绝对路径的目录名。即 print(os.path.dirname(os.path.abspath(__file__)))
四、导入优化
import module_name 可导入“module_name”模块中的所有方法(函数)。在当前文件中对模块中方法(函数)的调用,其执行顺序为:
查找名为“module_name”的Python文件。
在“modul_name”文件中查找被调用的方法(函数)。
执行被调用的方法(函数)。
如果在当前文件中多次调用,且调用次数达到相当数量时,每次调用都会执行1-3步,这种执行效率很低。
那么,为了提高执行效率,可以使用 from module_name import function_name 或 from module_name import function_name as alias。此时,当前文件调用模块中名为“function_name”的方法(函数)时,其执行顺序为:
查找名为“module_name”的Python文件。
在“modul_name”文件中查找被调用的“function_name”方法(函数)。
执行“function_name”方法(函数)。
看似与上面步骤相同,但其实第1步和第2步仅在导入模块的方法(函数)时执行,在调用方法(函数)时,仅执行第3步。因此,多次调用方法(函数)其实是多次执行第3步,因为在完成第1、2步之后,被调用的方法(函数)已经被加载到当前文件中。执行效率会明显提高。
五、模块的分类
1. 标准库
Python标准库也称为Python的内置模块,是Python内置的、供开发者选择性使用的、有助于提升Python移植性和扩展性的模块。
内置模块用C语言编写,提供了使用系统功能的接口;另一些用Python编写的模块能够为日常编程中遇到的问题提供标准解决方案。 ——Python标准库官方文档
2. 开源模块
开源模块也称第三方模块,是他人为了实现某种功能而自己编写的模块,并将模块代码共享到互联网可供任何人下载并使用的模块。
3. 自定义模块
自定义模块是自己在编程过程中编写的、方便自己调用的模块。
六、time 和 datetime 模块
1. 时间的格式
① 格式化字符串
⑴ 格式及含义
| 格式 | 含义 | 解释 |
|---|---|---|
| %y | 年 | 两位数年 |
| %Y | 年 | 四位数年 |
| %m | 月 | 01到12 |
| %d | 日 | 01到31 |
| %H | 时 | 00到23(24时计时法) |
| %M | 分 | 00到59 |
| %S | 秒 | 00到61(60和61为闰秒) |
| %z | 时区 | +为东时区,-为西时区 |
| %a | 星期 | 英文缩写 |
| %A | 星期 | 英文全称 |
| %b | 月份 | 英文缩写 |
| %B | 月份 | 英文全称 |
| %c | 当地最合适的日期时间表示方法 | 如:Thu Jan 25 14:17:55 2018 |
| %I | 时 | 01到12(12小时计时法) |
| %p | 上午或下午 | AM 或 PM |
⑵ 例
- 执行代码:
import time
struct_time = time.localtime()
time_str = time.strftime("%Y-%m-%d %H:%M:%S 时区:%z, 星期缩写:%a, 星期全称:%A, 月份简称:%b, 月份全称:%B, 当地时间日期表示法:%c, 12小时计时法:%I, 上午或下午:%p", struct_time)
print(time_str)
- 输出结果:
'2018-01-25 14:26:56 时区:+0800, 星期缩写:Thu, 星期全称:Thursday, 月份简称:Jan, 月份全称:January, 当地时间日期表示法:Thu Jan 25 14:26:56 2018, 12小时计时法:02, 上午或下午:PM'
② 时间戳
⑴ 定义
时间戳是当前时间距离1970年1月1日0点相差的以秒为单位的浮点小数。
⑵ 语法
import time
timestamp = time.time()
print(timestamp)
③ 时间元组
⑴ 定义
用一个9个元素的元组表示时间,该元组称为 struct_time 元组。
⑵ 语法
import time
local_time = time.localtime()
print(local_time)
- 注意:
time.localtime()括号中应填写数字,该数字表示秒。执行原理为:计算括号中的数字(秒)表示的时间,1970年1月1日0时0分0秒为0。若获取当前时间,可以将括号留空,其等价于括号内填写time.time(),即time.localtime() ⇔ time.localtime(time.time())
⑶ 解释
| 索引序号 | 属性 | 含义 | 解释 |
|---|---|---|---|
| 0 | tm_year | 4位数年 | 2008 |
| 1 | tm_mon | 月 | 1 到 12 |
| 2 | tm_mday | 日 | 1到31 |
| 3 | tm_hour | 小时 | 0到23 |
| 4 | tm_min | 分钟 | 0到59 |
| 5 | tm_sec | 秒 | 0到59 |
| 6 | tm_wday | 一周的第几日 | 0到6 (0是周一) |
| 7 | tm_yday | 一年的第几日 | 1到366 (儒略历) |
| 8 | tm_isdst | 夏令时 | -1, 0, 1, -1是决定是否为夏令时的旗帜 |
⑷ 提取时间元组信息
在第⑶部分的表格中,“属性”一栏是提取时间元组信息的重要信息,语法为 时间元组.属性
- 例:
- 执行代码:
import time struct_time = time.localtime() print(struct_time) print("年:", struct_time.tm_year, "\n月:", struct_time.tm_mon, "\n日:", struct_time.tm_mday, "\n时:", struct_time.tm_hour, "\n分:", struct_time.tm_min, "\n秒:", struct_time.tm_sec, "\n一周天数(从0起):", struct_time.tm_wday, "\n一年的天数(从1起):", struct_time.tm_yday)- 输出结果:
time.struct_time(tm_year=2018, tm_mon=1, tm_mday=25, tm_hour=14, tm_min=48, tm_sec=26, tm_wday=3, tm_yday=25, tm_isdst=0) 年: 2018 月: 1 日: 25 时: 14 分: 48 秒: 26 一周天数(从0起): 3 一年的天数(从1起): 25- 注意:提取信息时,没有“isdst”(夏令时)属性。
2. time模块常用属性
| 属性 | 功能 | 备注 |
|---|---|---|
| time.time() | 查看时间戳 | 不需要参数。 |
| time.sleep(sec_num) | 睡眠几秒 | 必须有1个参数,参数为数字,表示睡眠的秒数。 |
| time.gmtime([sec_num]) | 将秒转化为0时区的时间元组 | 参数为数字,表示秒;参数为空则默认当前时间。 |
| time.localtime([sec_num]) | 将秒转化为本地时区的时间元组 | 参数为数字,表示秒;参数为空则默认当前时间。 |
| time.mktime(struct_time) | 将本地时区的时间元组转化为秒 | 必须有1个参数,参数为struct_time时间元组。 |
| time.strftime(format, struct_time) | 将时间元组转化为自定义字符串格式的时间 | 必须有2个参数,第1个参数为自定义格式;第2个参数为时间元组。 |
| time.strptime(string, format) | 将自定义字符串格式的时间转化为时间元组 | 必须有2个参数,第1个参数为时间字符串;第2个参数为时间自定义格式。 |
| time.asctime([struct_time]) | 将时间元组转化为字符串格式的时间 | 参数为时间元组;参数为空则默认当前时间。结果格式为:%a %b %d %H:%M:%S %Y |
| time.ctime([sec_num]) | 将时间戳转化为字符串格式的时间 | 参数为数字,表示时间戳(秒);参数为空则默认为当前时间。结果格式为:%a %b %d %H:%M:%S %Y |
- 注意:
参数有方括号“[]”的表示参数可有可无;否则必须有参数或必须没有参数。
调用属性语法:
time.属性名()
3. 时间戳、时间元组、时间格式化字符串的相互转换
4. time模块举例
5. datetime模块常用属性
| 语法 | 所属类 | 功能 | 备注 |
|---|---|---|---|
| datetime.date(year_num, month_num, day_num) | date | 设定日期 | 必须有3个参数。第1个参数为4位数字,表示年;第2个参数为1-2位数字,表示月;第3个参数为1-2位数字,表示日。 |
| datetime.date.today() | date | 获取当前日期 | 不需要参数。格式为:YYYY-MM-DD |
| datetime.date.fromtimestamp(sec_num) | date | 以1970年1月1日为基准,获取给定时间的日期 | 必须有1个参数。参数为数字,表示秒。意为:1970年1月1日往后sec_num秒的日期。格式为:YYYY-MM-DD |
| datetime.time([hour_num], [minute_num], [second_num]) | time | 设定时间 | 位置传参。若无参数,则表示00:00:00;hour_number表示给定小时数;minute_num表示给定分钟数;second_num表示给定秒数。 |
| datetime.time([hour=], [minute=], [second=]) | time | 设定时间 | 关键字传参。若无参数,则表示00:00:00;"hour/minute/second="跟数字,表示给定的"时/分/秒"。 |
| datetime.time.min | time | 获取最小时间 | 执行结果为:00:00:00 |
| datetime.time.max | time | 获取最大时间 | 执行结果为:23:59:59.999999 |
| datetime.time([hour], [min], [sec]).replace([hour], [minute], [second]) | time | 修改时间 | time和replace的参数均可有可无。若replace没有参数,则不修改时间;replace既可以使用关键字(hour=, minute=, second=)传参,也可以使用位置传参。 |
| datetime.time([hour], [min], [sec]).strftime(format) | time | 修改时间的格式 | time的参数可有可无,strftime必须有1个参数,且为格式化字符串。%H对应小时,%M对应分钟,%S对应秒。 |
| datetime.datetime.now() | datetime | 获取当前日期和时间 | 不需要参数。获取的日期和时间格式为:YYYY-MM-DD HH:MM:SS.SS |
| datetime.datetime(year, month, day, [hour, minute, second]) | datetime | 设定日期时间 | 必须有3个参数,且参数均为数字。参数可使用位置传参,也可以使用关键字传参。参数按位置分别表示年、月、日、时、分、秒、微秒。 |
| datetime.datetime.combine(datetime.date, datetime.time) | datetime | 组合日期和时间 | 必须有2个参数。第1个参数为date类;第2个参数为time类。 |
| datetime.datetime(parameter).replace([year, month, day, hour, minute, second]) | datetime | 修改日期时间 | datetime必须有3个参数,replace的参数可有可无。若replace没有参数则不作修改;replace的参数可以位置传参也可以使用关键字传参。 |
| datetime.datetime(parameter).strftime(format) | datetime | 修改日期时间的格式 | datetime必须有3个参数,strftime必须有1个参数且为格式化字符串。参照"六、time与datetime模块"中的"1. 时间的格式"中的"① 格式化字符串"。 |
| datetime.timedelta([day_num], [sec_num]) | timedelta | 两个日期时间的差值 | 此属性不单独使用。第1个参数为数字,表示天数,+表示未来,-表示过去;第2个参数为数字,表示秒,+表示未来,-表示过去;若无参数,则无差值。 |
| datetime.timedelta([days=], [hours=], [minutes=], [seconds=]) | timedelta | 两个日期时间的差值 | 含义同上一个属性。使用关键字传参,对特定天数、小时、分钟和秒传参,+表示未来,-表示过去。 |
6. datetime模块举例
7. datetime模块常见用法
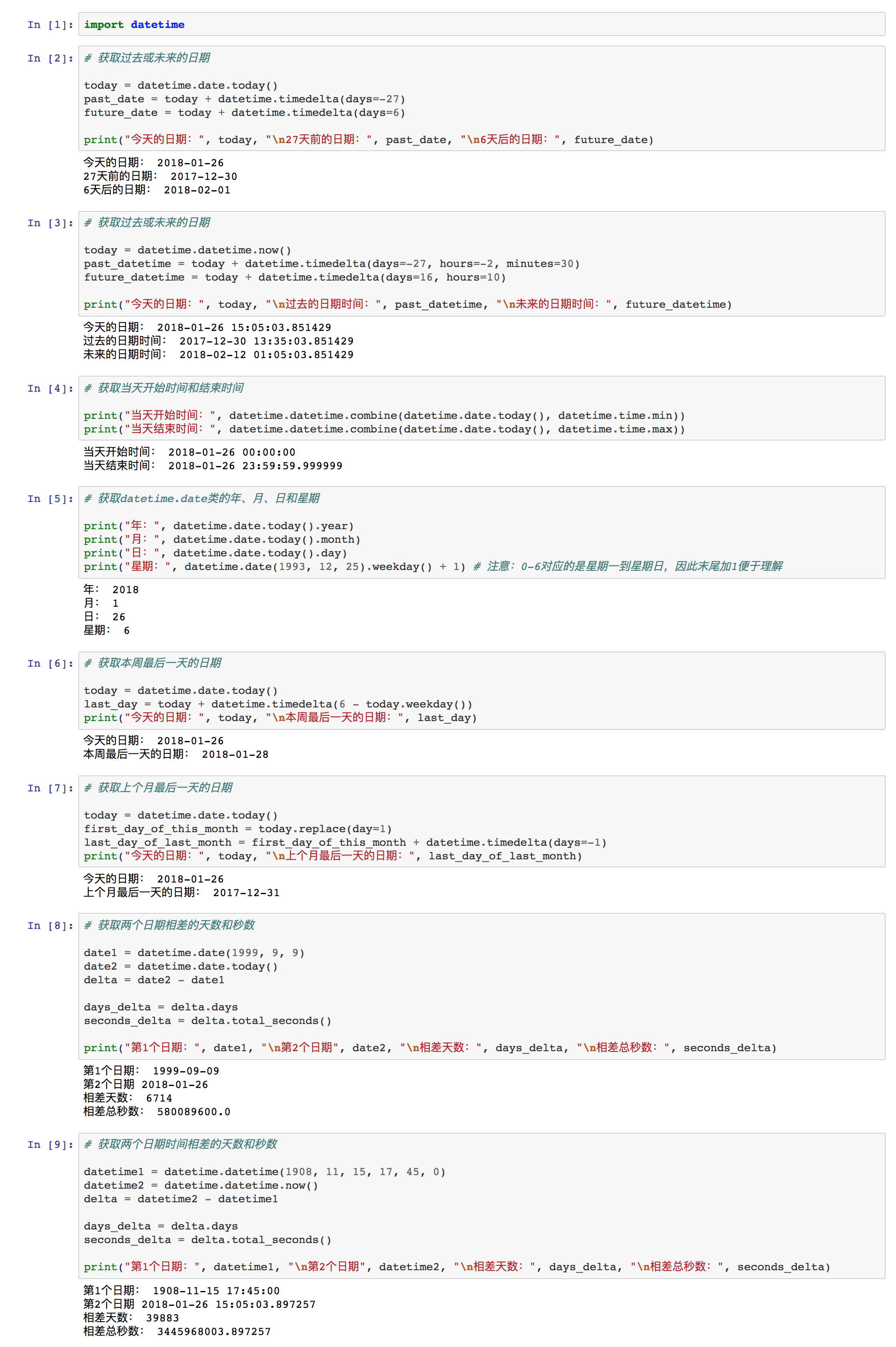
① 获取过去或未来的日期
import datetime
datetime.date.today() + datetime.timedelta([days=])
- 注意:
“days=”为关键字传参,“=”后跟数字,意为天数。“+”表示未来的天数;“-”表示过去的天数。
“[]”表示参数可有可无,在实际传参中不需要写方括号“[]”。若没有参数,表示日期不偏移。
② 获取过去或未来的日期和时间
import datetime
datetime.datetime.now() + datetime.timedelta([days=], [hours=], [minutes=], [seconds=], [microseconds=])
- 注意:
“datetime.timedelta()”为关键字传参,“=”后跟数字,意为天数/小时数/分钟数/秒数/微秒数。“+”表示未来的偏移;“-”表示过去的偏移。
“[]”表示参数可有可无,在实际传参中不需要写方括号“[]”。若没有参数,表示日期时间不偏移。
③ 获取当天开始时间和结束时间
⑴ 当天开始时间
import datetime
datetime.datetime.combine(datetime.date.today(), datetime.time.min)
⑵ 当天结束时间
import datetime
datetime.datetime.combine(datetime.date.today(), datetime.time.max)
④ 获取datetime.date类的年、月、日和星期
⑴ 年
import datetime
datetime.date(year_num, month_num, day_num).year
⑵ 月
import datetime
datetime.date(year_num, month_num, day_num).month
⑶ 日
import datetime
datetime.date(year_num, month_num, day_num).day
⑷ 星期
import datetime
datetime.date(year_num, month_num, day_num).weekday()
- 注意:结果为0-6的数字,分别表示星期一到星期日。
⑤ 获取本周最后一天的日期
import datetime
last_day_of_this_week = datetime.date.today() + datetime.timedelta(6 - datetime.date.today())
print(last_day_of_this_week)
思路:将今天的日期加上今天距离本周日的天数。
-
注意:
6表示星期日。
为了便于理解变量的含义,此处的变量名比较长。
⑥ 获取上个月最后一天的日期
import datetime
today = datetime.date.today()
first_day_of_this_month = datetime.date(today.year, today.month, 1)
last_day_of_last_month = first_day_of_this_month - datetime.timedelta(days=1)
print(last_day_of_last_month)
思路:获取当前月份第一天的日期,然后向过去推移1天。
注意:为了便于理解变量的含义,此处的变量名比较长。
⑦ 获取两个日期(或时间日期)相差的天数、秒数
⑴ 日期
import datetime
date1 = datetime.date(year1, month1, day1)
date2 = datetime.date(year2, month2, day2)
delta = date1 - date2
day_delta = delta.days
seconds_delta = delta.total_seconds()
print(day_delta, seconds_delta)
⑵ 日期时间
import datetime
date_time1 = datetime.datetime(year1, month1, day1, hour1, minute1, second1)
date_time2 = datetime.datetime(year2, month2, day2, hour2, minute2, second2)
delta = date_time1 - date_time2
day_delta = delta.days
seconds_delta = delta.total_seconds()
print(day_delta, seconds_delta)
⑶ 注意
“day_delta”的值为两个日期相差的天数。运用了属性
.days,这个属性只有计算差时(datetime模块中的timedelta类中)才可以使用。“seconds_delta”的值为两个日期相差的总秒数。运用了属性
.total_seconds(),这个属性只有计算差时(datetime模块中的timedelta类中)才可以使用。如果使用了seconds属性,则结果为0。因为该属性只计算两个日期的秒的差。
8. datetime模块常见用法举例
七、calendar模块
该模块中的函数均为日历相关操作和处理的模块。
1. calendar模块常见用法
| 语法 | 功能 | 备注 |
|---|---|---|
| calendar.calendar(year,w=2,l=1,c=6, m=3) | 返回一个多行字符串格式的 year年年历 | year为年数,w为每日宽度的间隔字符数,l为每个星期的行间距,c为每个月份之间的间隔字符数,m为并行的月份个数。 |
| calendar.firstweekday( ) | 返回当前每周起始日期的设置 | 默认情况下,首次载入caendar模块时返回0,即星期一。 |
| calendar.isleap(year) | 判断year年是否是闰年 | year年是闰年则返回True,平年则返回False。 |
| calendar.leapdays(year1,year2) | 计算year1和year2之间有几个闰年 | 判断的区间是前闭后开,即包括year1但不包括year2。 |
| calendar.month(year,month,w=2,l=1) | 返回year年month月的月历 | year为年数,month为月数,w为每日宽度的间隔字符数,l为每个星期的行间距。 |
| calendar.monthcalendar(year,month) | 以列表的形式返回year年month月的月历 | 列表的元素仍是列表,子列表的个数即为当月周数的合计。子列表的元素为星期一至星期日对应的月份日期,非该月月份的日期为0。 |
| calendar.monthrange(year,month) | 返回一个2个元素的元组 | 第一个元素为year年month月第一天的星期数,0到6分别代表星期一到星期日;第二个元素为year年month月的总天数 |
| calendar.prcal(year,w=2,l=1,c=6, m=3) | 返回一个多行字符串格式的 year年年历 | 相当于"print(calendar.calendar(year, w=2, l=1, c=6, m=3))",但类型为NoneType。 |
| calendar.prmonth(year,month,w=2,l=1) | 返回year年month月的月历 | 相当于"print(calendar.month(year, month, w=2, l=1, c=6))",但类型为NoneType。 |
| calendar.setfirstweekday(weekday) | 设置每周起始日期数字 | 0到6分别代表星期一到星期日。 |
| calendar.timegm(struct_time) | 返回时间戳 | 与time.gmtime()相反,该函数接收一个时间元组,返回该时间的时间戳。 |
| calendar.weekday(year,month,day) | 返回year年month月day日的星期数 | year为年,month为月,day为日,返回结果为一个0到6的数字,分别代表星期一到星期日。 |
2. 三目运算符判断平年闰年
使用场景:在编程过程中不导入calendar模块判断年份为平年还是闰年。
优势:此方法可以根据需要返回自定义值,而calendar.isleap()的返回值只能是True或False。
代码:
def isLeapYear(year):
return 自定义值1 if year % 4 == 0 and year % 100 != 0 or year % 400 == 0 else 自定义值2
当“自定义值1”为True且“自定义值2”为False时,其功能与 calendar.isleap() 完全一致。
3. 获取本月的最后一天
import calendar, datetime
today = datetime.date.today()
last_day_num = calendar.monthrange(today.year, today.month)[1]
last_day_date = datetime.date(today.year, today.month, last_day_num)
print(last_day_date)
4. calendar模块常见用法举例
八、random模块
该模块用于获取随机数。
1. random模块常见用法
| 语法 | 功能 | 备注 |
|---|---|---|
| random.random() | 随机一个0到1的浮点数 | |
| random.randint(num1, num2) | 在num1和num2之间随机一个整数 | 随机数的范围为:num1≤随机数≤num2 |
| random.randrange(num1, num2[, step]) | 在num1和num2之间随机一个整数,步长为step | 随机数的范围为:num1≤随机数<num2,步长默认为1。 |
| random.choice(sequence) | 在给出的序列中随机一个值 | 参数必须为序列,即:字符串、列表或元组。 |
| random.sample(sequence, num) | 在给出的序列中随机num个值 | 第1个参数必须为序列,即:字符串、列表或元组。第2个参数为随机值的个数。 |
| random.uniform(num1, num2) | 在num1和num2之间随机一个浮点数 | num1和num2可以是浮点数。 |
| random.shuffle(list) | 把list列表的元素顺序打乱 | 需要先定义列表,然后把列表作为参数传入,之后打印列表即可得乱序后的列表。 |
2. random模块常见用法举例
九、os模块
os模块主要用于处理文件和目录。
1. os模块常见用法
| 语法 | 功能 | 备注 |
|---|---|---|
| os.curdir | 当前目录的标识符 | 结果为"." |
| os.pardir | 上级目录的标识符 | 结果为".." |
| os.sep | 输出当前操作系统特定的路径分隔符 | Windows:\ Linux & Mac:/ |
| os.linesep | 输出当前操作系统特定的换行符 | Windows:\t\n Linux & Mac:\n |
| os.pathsep | 输出当前操作系统特定的环境变量分隔符 | Windows:; Linux & Mac:: |
| os.environ | 输出当前系统的环境变量 | |
| os.name | 输出当前系统的名称 | Windows:'nt' Linux & Mac:'posix' |
| os.getcwd() | 获取当前目录的绝对路径 | |
| os.chdir(abs_path) | 切换路径 | 参数为目标位置的绝对路径 |
| os.makedirs(abs_path, mode) | 递归创建目录并赋权限 | 第1个参数是需要递归创建目录的绝对路径;第2个参数是创建的目录的权限数字。若创建的目录已存在,则报错。 |
| os.removedirs(abs_path) | 递归删除空目录 | 若目录为空则删除该目录;递归至上一级目录,若上一级目录也为空,则也删除。以此类推。 |
| os.mkdir(abs_path) | 创建目录 | 参数为创建目录的绝对路径,若路径中含有不存在目录,则报错。 |
| os.rmdir(abs_path) | 删除单级空目录 | 参数为需删除目录的绝对路径。被删除目录必须为空,否则无法删除且报错。 |
| os.listdir(abs_path) | 以列表形式返回目录下的所有文件 | |
| os.remove(path) | 删除一个文件 | 参数为需要删除文件的路径。 |
| os.rename("old_name", "new_name") | 重命名 | 第1个参数是需被重命名的原文件名(字符串格式);第2个参数是新文件名(字符串格式)。 |
| os.stat('file_name') | 查看文件的详细信息 | |
| os.system('command') | 执行系统命令 | 参数为系统命令的字符串。 |
| os.path.abspath('file_name') | 获取文件的绝对路径 | 参数为文件名,字符串格式。 |
| os.path.split(path) | 返回包含路径和文件名的二元组 | 参数为包含文件名的路径,路径可不存在。结果返回为2个元素的元组。第1个元素为目录的路径;第2个元素为文件名。 |
| os.path.dirname(path) | 获取目录名 | 参数为路径,结果返回为目录名,字符串格式。目录可不存在。 |
| os.path.basename(path) | 获取文件名 | 参数为路径,结果返回为文件名,字符串格式。目录和文件可不存在。 |
| os.path.exists(path) | 判断路径是否存在 | 参数为路径,结果为True或False。 |
| os.path.isabs(path) | 判断路径是否为绝对路径 | 参数为绝对路径,结果为True或False。路径中家目录若用"~"则结果为False。路径可不存在。 |
| os.path.isfile(path) | 判断是否为文件 | 参数为路径,结果为True或False。若文件不存在,则结果也为False。路径中家目录若用"~"则结果为False。 |
| os.path.isdir(path) | 判断是否为目录 | 参数为路径,结果为True或False。若目录不存在,则结果也为False。路径中家目录若用"~"则结果为False。 |
| os.path.join(path1, path2,...,pathN) | 将多个路径组合返回一个完整路径 | 参数个数不限,但都须为字符串格式。若每个路径中没有'/'符号则会自动补全;根目录符号"/"前的所有参数将会被忽略。 |
| os.path.getatime('file_name') | 返回文件或目录的最后存取时间的时间戳 | 参数为含有目录或文件名的路径,字符串格式。 |
| os.path.getmtime('file_name') | 返回文件或目录的最后修改时间的时间戳 | 参数为含有目录或文件名的路径,字符串格式。 |
2. 用户权限
由于 os.makedirs(abs_path, mode) 函数中涉及到为目录赋权限,因此,该部分将结合Linux & Mac系统对用户权限做详细说明。仅了解权限数字部分已经可以使用 os.makedirs(abs_path, mode) ,因此可以直接跳转至“权限数字”部分进行阅读。
① 用户的分类
每个用户都有一个唯一标识符(UID:用户ID)
| 用户类别 | 用途 | UID取值 |
|---|---|---|
| 普通用户 | 用于登录使用 | UID ≥ 1000 |
| 系统用户 | 用于系统服务使用(不允许登录) | 0 < UID < 1000 |
| 超级管理员用户 | UID = 0 |
② 用户组
用户组:将多个用户定义组,方便管理权限,用GID表示用户组唯一标识符。
③ 用户配置文件
| 配置文件类型 | 路径 |
|---|---|
| 用户信息配置文件 | /etc/passwd |
| 用户密码信息配置文件 | /etc/shadow |
| 用户组信息配置文件 | /etc/group |
| 用户组密码信息配置文件 | /etc/gshadow |
④ 用户管理命令
注意:用户信息修改必须超级管理员用户操作。
| 用途 | 命令 |
|---|---|
| 获取当前登录用户的信息 | id |
| 获取指定用户的信息 | id 用户名 |
| 临时切换用户 | su 用户名 |
| 添加用户 | adduser |
| 删除用户信息 | userdel 用户名 |
| 删除用户信息及用户家目录 | userdel -r 用户名 |
| 修改密码 | passwd |
⑤ sudo命令
root用户可以给其它普通用户授权, 授权后普通用户具备执行超级管理员的命令,但不能直接执行,必须使用 sudo 去执行, 对所有操作做二次确认,减少误操作。
sudo 只能运行外部命令。 sudo 执行的命令执行权限为root。
-
授权:
步骤 命令 作用 ① su root 切换root ② visudo 输入命令 ③ root ALL = (ALL:ALL) ALL 搜索记录 ④ 用户名 ALL = (ALL:ALL) ALL 添加权限
⑥ 权限
⑴ 查看权限命令
ls -l 或 ls -d
⑵ 举例解释
若权限为:rw-rw-r--
⒜ 分段
以三个字符为一段,分成三段
| 序号 | 字符 | 含义 |
|---|---|---|
| ① | rw- | 代表所属用户对此文件的操作权限(u) |
| ② | rw- | 第二段代表所属用户组对此文件的操作权限(g) |
| ③ | r-- | 第三段代表其它用户对此文件的操作权限(o) |
⒝ r:读
* 针对文件:有r权限代表对此文件可以打开和获取文件内容。
* 针对目录:有r权限代表对此目录可以遍历(ls)。
⒞ w:写
* 针对文件:有w权限代表对此文件可以编辑。
* 针对目录:有w权限代表对此目录可以新建子目录和文件。
⒟ x:执行
* 针对文件:有x权限代表对此文件可以运行。
* 针对目录:有x权限代表可以进入此目录(cd)。
⑶ 修改权限
除了root用户外,其他用户只能修改所属用户是自己的文件。
- 语法:
chmod 权限修改内容 文件
⑷ 举例解释不同权限修改方法
| 序号 | 语法示例 | 含义 |
|---|---|---|
| ① | chmod u=rw- file | 对file文件修改用户权限,具有读、写权限但不具备执行权限。(此方法可以修改u, g, o任意权限) |
| ② | chmod u=rwx,g=---,o=--- file | 修改file文件用户、用户组和其他人的权限(即修改了所有权限) |
| ③ | chmod 0 file | 取消file文件的所有权限 |
| ④ | chmod o+w file | 为file文件中其他人(o)增加写的权限 |
| ⑤ | chmod o-x,g+w file | 为file文件中其他人(o)减少执行权限,为用户组(g)增加写的权限 |
| ⑥ | chmod 755 file | file文件中用户(u)具有读、写、执行权限,用户组(g)具有读和执行权限,其他人(o)具有读和执行权限 |
⑸ 权限数字
| 字符 | 二进制 | 十进制 |
|---|---|---|
| --- | 000 | 0 |
| --x | 001 | 1 |
| -w- | 010 | 2 |
| -wx | 011 | 3 |
| r-- | 100 | 4 |
| r-x | 101 | 5 |
| rw- | 110 | 6 |
| rwx | 111 | 7 |
⑹ 修改所属用户和组
语法:chown 用户名:组名 文件
⑺ 为目录及目录所有文件及子目录修改用户和组
语法:chown 用户名:组名 目录 -R
⑻ 粘贴位
粘贴位一般用在目录上,用在文件上起不到作用。
粘贴位只对所有权限(777或rwxrwxrwx)的目录的其它用户权限设置。
⒜ 粘贴位写法
将所有权限(rwxrwxrwx)的目录中其他(o)权限的x位置上改为t。e.g.:(dir为自定义目录)
chmod drwxrwxrwt dir
将所有权限(777)的目录权限前添加1。e.g.:(dir为自定义目录)
chmod 1777 dir
⒝ 粘贴位设置的目的
防止其他用户操作其他(另外)用户文件。
⑼ 特权位
⒜ 语法
| 类别 | 语法 |
|---|---|
| 用户特权 | chmod u+s 文件 |
| 用户组特权 | chmod g+s 文件 |
⒝ 特权位写法
为用户权限添加特权位:把用户(u)权限x替换成s。
为用户组权限添加特权位:把用户组(g)权限x替换成s。
⒞ 注意
为用户权限添加特权位(u+s):只能针对可执行文件(命令和程序)来设定。
为用户组权限添加特权位(g+s):既可以对可执行文件(命令和程序)来设定,也可以对目录进行设定。如果g+s对目录来设定,那么在该目录下直接创建文件、创建目录,这些文件或者目录的所有组就会自动继承该目录的所有组。
⒟ 特权位设置的作用
当命令文件被设定了特权位,无论什么用户执行该命令或操作该文件,进程的有效身份都是该命令或文件本身的所属用户(u)或者拥有组(g)身份一样,与执行者(o)权限无关。
十、其他模块
由于现阶段的学习进度限制无法花更多的精力在其他模块的学习上,在此先将打算学习的模块列出(我的学习优先级由上至下),日后再研究学习并完善该部分内容。
- sys
- re
- json & pickle
- thread
- threading
- Queue
- xml
- ConfigParser
- shutil
- shelve
- logging
- subprocess
- PyYAML
- hashlib
- hmac
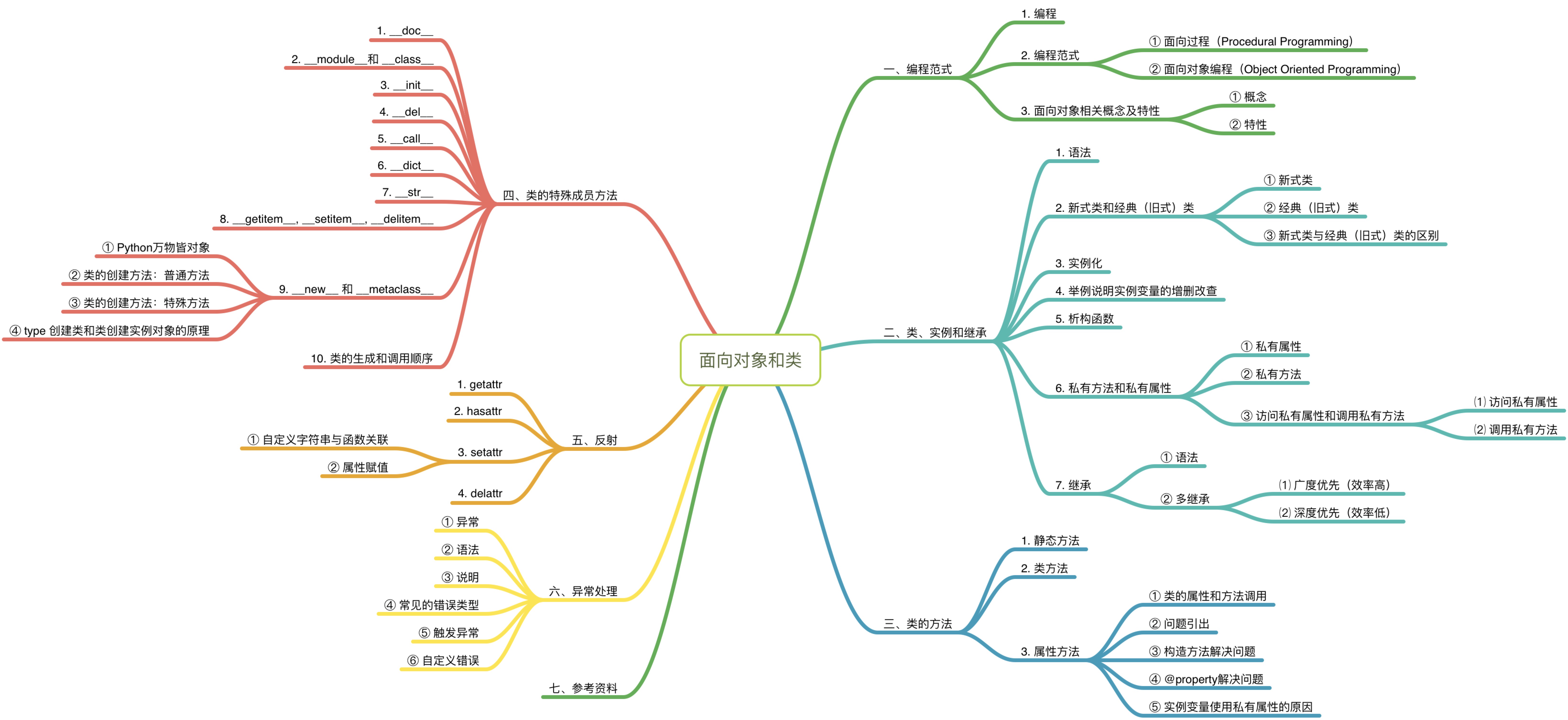
一、编程范式
1. 编程
编程是编写程序的中文简称,就是让计算机代为解决某个问题,对某个计算体系规定一定的运算方式,是计算体系按照该计算方式运行,并最终得到相应结果的过程。为了使计算机能够理解人的意图,人类就必须将需解决的问题的思路、方法和手段通过计算机能够理解的形式告诉计算机,使得计算机能够根据人的指令一步一步去工作,完成某种特定的任务。这种人和计算体系之间交流的过程就是编程。——百度百科
简而言之,编程就是程序员通过 特定语法 + 数据结构 + 算法 与计算机交流的过程。
2. 编程范式
指计算机编程的基本风格或典范模式。编程范式是对不同编程方式特点的归纳和总结。编程范式统括为:面向对象编程、面向过程编程、函数式编程。其中,面向对象编程和面向过程编程是最为重要的两种编程范式。
① 面向过程(Procedural Programming)
Procedural programming uses a list of instructions to tell the computer what to do step-by-step.
解释:面向过程是一种以过程为中心的编程思想。解决问题的思路是针对问题分析所需要的步骤,然后按步实现。
设计思路:top-down language,即程序从上到下按步执行。
弊端:凡是对程序的修改,都需要对修改部分有依赖的部分进行修改,维护难度大。
使用场景:写简单脚本;任务是一次性的。
② 面向对象编程(Object Oriented Programming)
世界万物,皆可分类。世界万物,皆为对象。
解释:面向对象是一种以事物(对象)为中心的编程思想。通过“类”和“对象”创建各种模型来实现对真实世界的描述。因为世间万物只要是对象,就肯定属于某种品类;只要是对象,就肯定有属性。
-
优点:
- 程序的维护和扩展变得简单。
- 提高开发效率。
- 更容易理解代码逻辑。
使用场景:任务复杂;需要不断迭代和维护。
3. 面向对象相关概念及特性
① 概念
类(Class):对一类具有相同属性对象的抽象,且定义了该类对象都具备的属性(Variables(data))以及共同的方法。
对象(Object):一个类实例化后的实例。
② 特性
封装(Encapsulation):类中对数据的赋值、内部的调用对外部用户是透明的。
继承(Inheritance):类可以派生子类,父类定义的属性、方法自动被子类继承。
多态(Polymorphism):一个接口,多种实现。
二、类、实例和继承
1. 语法
class 类名(object): # 类名通常首字母大写
变量名 = value # 类变量
def __init__(self, 参数1, 参数2, ..., 参数n):
"""
构造函数:实例化时所做的类的初始化工作
self.参数:实例变量(静态属性)。作用于为实例本身。
"""
self.参数1 = 参数1
self.参数2 = 参数2
...
self.参数n = 参数n
def 方法名(self):
"""
类的方法,功能(动态属性)
"""
函数体
2. 新式类和经典(旧式)类
① 新式类
class 类名(object):
pass
② 经典(旧式)类
class 类名:
pass
③ 新式类与经典(旧式)类的区别
如上图所示,第1幅图可以明显地展示出新式类与经典类的区别,其运行环境是Python 2.7版本;然而,在Python 3.6版本中,这个区别已经不再存在,如第2幅图所示。
新式类都从object类继承,而经典类不需要。
新式类相同父类只执行一次构造函数,经典类重复执行多次。
在多继承方面,新式类的基类搜索顺序与经典类存在较大区别,详见“二、类、实例和继承”中“7. 继承”中“ ②多继承”。
3. 实例化
把一个类变成一个具体对象的过程,称为实例化。
对象名 = 类名()
例如:
class Student(object):
def __init__(self, name, age):
self.name = name
self.age = age
def registration(self):
print("%s registers successfully! %s is %s years old." % (self.name, self.name, self.age))
raxxie = Student('Raxxie', 18)
其中,Student是学生类,而raxxie就是Student类的一个实例化对象。
4. 举例说明实例变量的增删改查
5. 析构函数
在实例释放和销毁的时候执行,通常用于做一些收尾工作。如:关闭一些数据库连接,关闭已打开的临时文件,等。
def __del__(self):
函数体
当对象在内存中被释放时,自动触发执行。
- 注意:此方法一般无须定义,因为Python是一门高级语言,程序员在使用时无需关心内存的分配和释放,因为此工作都是交给Python解释器来执行,所以析构函数的调用是由解释器在进行垃圾回收时自动触发执行的。
6. 私有方法和私有属性
① 私有属性
self.__属性名(变量名) = value
② 私有方法
def __方法名(self):
函数体
③ 访问私有属性和调用私有方法
⑴ 访问私有属性
- 私有属性是无法从外部直接访问的,如下图:
访问私有属性有两种方法:
- 方法一:在类的内部构造方法进行内部访问私有属性,并在外部调用方法。如下图:
- 方法二:在外部通过
对象名._类名__私有属性名的方法访问私有属性。如下图:
⑵ 调用私有方法
- 私有方法是无法从外部直接调用的,如下图:
- 调用私有方法可以通过
对象名._类名__私有方法名()的方法调用私有方法。如下图:
7. 继承
① 语法
class A(object):
def __init__(self, name, age):
self.name = name
self.age = age
class B(A):
def __init__(self, name, age, addr, gender):
A.__init__(self, name, age) # 也可写为 super(B, self).__init__(name, age) # 新式类
self.addr = addr
self.gender = gender
上面代码为新式类,object类是A类的基类,A类是B类的基类,B类继承了A类,因此在B类的 __init__ 方法当中,直接继承了A类的 __init__ 同时增加了B类 __init__ 方法的自有属性“addr”和“gender”。
② 多继承
类是支持多继承的,即一个类可以有多个基类,即继承多个类。但在经典类和新式类中,基类的搜索顺序(Method Resolution Order)是不同的。基类的搜索顺序分为“广度优先”和“深度优先”
⑴ 广度优先(效率高)
- Python 2.x的新式类
- Python 3.x的经典类和新式类
# 【广度优先】Python 2.x 和 Python 3.x的新式类
class A(object):
pass
class B(A):
pass
class C(A):
pass
class D(B, C):
pass
以及
# 【广度优先】Python 3.x的经典类
class A:
pass
class B(A):
pass
class C(A):
pass
class D(B, C):
pass
- D类中缺少的函数方法将从基类继承,其基类的搜索顺序为:B → C → A
⑵ 深度优先(效率低)
- Python 2.x的经典类
# 【深度优先】Python 2.x的经典类
class A:
pass
class B(A):
pass
class C(A):
pass
class D(B, C):
pass
D类中缺少的函数方法将从基类继承,其基类的搜索顺序为:B → A → C
注意:如果C类的基类不是A而是其他类,则基于上述顺序,搜索C之后再搜索C的基类。
三、类的方法
1. 静态方法
@staticmethod
静态方法与类无关,仅相当于一个单纯的函数。静态方法名义上是归类管理的,但实际上在静态方法里访问不了类或实例中的任何属性。
使用场景:属于该类,但不需要被复用的函数,可以考虑使用静态方法。
-
注意:
静态方法的参数中不需要写“self”,在调用静态方法时,实参个数必须与形参个数相等。
调用静态方法既可以使用类名调用,也可以使用实例名调用。
2. 类方法
@classmethod
类方法只能访问类变量,不能访问实例变量。当在类方法中访问实例变量时将报错,如下图所示:
因此,类方法只能访问类变量。
3. 属性方法
@property
顾名思义,类的属性方法是将类的方法转换成以属性的形式进行修改和调用。
该部分主要参考的是“Python 之 @property”的讲解。该部分内容是根据我的理解进行重新整理,供参考。
① 类的属性和方法调用
类的属性调用:
实例名.属性名类的方法调用:
实例名.方法名()
② 问题引出
# 创建类
class Student(object):
def __init__(self,name,score):
self.name = name
self.score = score
# 实例化
s1 = Student('Lily', 9999)
上述代码的实例对象s1的name属性和score属性分别为 s1.name = 'Lily' , s1.score = 9999。代码逻辑是完全成立的,但业务逻辑中,成绩为9999显然是不合理的,因此:通过属性的调用和修改是无法进行参数检查的。
③ 构造方法解决问题
# 构造get_score方法和set_score方法
class Student(object):
def __init__(self, name, score):
'''
类的初始化
'''
self.name = name
self.score = score
def get_score(self):
'''
获取score
'''
return self.score
def set_score(self, score):
'''
设置score并进行参数检查
'''
if not isinstance(score, int):
raise ValueError("Invalid score!")
if score < 0 or score > 100:
raise ValueError("Score must be between 0 and 100!")
self.score = score
上述代码通过构造“get_score”方法来获取score;通过构造“set_score”方法来设置或修改score的值,同时进行参数检查。
此时,当通过实例对象调用“set_score”方法时,将会对score的值进行检查。看似问题得到了解决,但仍然存在2个缺陷:
第一,只有通过调用“set_score”方法才能进行score的检验;如果通过属性的赋值,仍然无法检验score;在实例化时,无法对score的值进行检验。
第二,想要在检查score输入合法性的前提下修改score不能够通过修改属性的方法,必须通过调用“set_score”方法,尽管复杂度较低,但也客观地增加了复杂度。
④ @property解决问题
class Student(object):
def __init__(self, name, score):
self.__name = name
self.__score = score
@property # 读取__score值
def score(self):
return self.__score
@score.setter # 设置/修改__score值
def score(self, score):
if not isinstance(score, int):
raise ValueError("Invalid score!")
if score < 0 or score > 100:
raise ValueError("Score must be between 0 and 100!")
self.__score = score
@score.deleter # 删除__score属性
def score(self):
del self.__score
@property # 读取__name值
def name(self):
return self.__name
代码说明:
实例变量由“name”和“score”改变为“__name”和“__score”,均为私有属性。
@property:读取值。装饰的方法可以直接以调用属性名的方法查看值。如:实例名.方法名而非实例名.方法名()。@方法名.setter:设置/修改值。装饰的方法可以直接以修改属性值的方法修改值。如:实例名.方法名 = 值而非实例名.方法名(值)。@方法名.deleter:删除方法(属性)。装饰的方法可以直接以删除属性值的方法删除方法。如:del 实例名.方法名。
注意:
# 实例化
s1 = Student('Mory', 90)
s1.name = 'Raxxie'
s1.score = 100
执行实例化代码后,
s1.name = 'Raxxie'会出现编译错误:“AttributeError: can’t set attribute”。因为这里只为“name”提供了读取方法(@property),没有提供@name.setter,故无法对值进行设置和修改。当然,由于没有@name.deleter,想要删除“name”也是无法实现的。充满好奇心又细心的你或许会发现,如果直接使用
s1.__name = 'Raxxie'是可以通过编译的。但是,这并不是修改了我们在初始化方法__init__中的“__name”,可以通过print(s1.__dict__)来查看“s1”实例的属性。不难发现,私有属性是“_Student__name”和“_Student__score”,而“__name”则是新的属性。因此,通过实例名.__属性名 = 值的方法无法修改值,只是创建了新的属性。
⑤ 实例变量使用私有属性的原因
class Student(object):
def __init__(self,name,score):
self.name = name
self.score = score
@property
def score(self):
return self.score
@score.setter
def score(self,score):
if not isinstance(score,int):
raise ValueError("Invalid score!")
if score < 0 or score > 100:
raise ValueError("Score must be between 0 and 100!")
self.score = score
@property
def name(self):
return self.name
def func(self):
self.score = score
上述代码存在2个错误,且无法定义Student类的任何实例:
第一,@property 把“score”和“name”两个成员函数可以当作成员变量来访问。那么在定义实例时,调用 __init__ 方法时,执行self.name = name 语句,Python会将左端的“self.name”当作函数调用,然而上述代码并未给“name”定义set函数,即 @name.setter ,于是错误信息为:“AttributeError: can’t set attribute.”
第二,若注释掉 @property 装饰的 name 方法,即:
class Student(object):
def __init__(self,name,score):
self.name = name
self.score = score
@property
def score(self):
return self.score
@score.setter
def score(self,score):
if not isinstance(score,int):
raise ValueError("Invalid score!")
if score < 0 or score > 100:
raise ValueError("Score must be between 0 and 100!")
self.score = score
# @property
# def name(self):
# return self.name
def func(self):
self.score = score
上述代码仍会报错,因为 __init__ 函数中,执行 self.score = score 时,由于已经定义了“score”的set函数,即 @score.setter , 因此“self.score”将调用 @score.setter 装饰的“score”方法。当执行到“score”方法中的 self.score = score 时,等号的左边还是 @score.setter 装饰的“score”方法的调用。 如此往复,最终以函数递归深度达到上限退出程序。
解决方法:
尽量不要让方法(函数)名与实例变量(静态属性)同名。因此,建议将方法(函数)名命名为常被调用的名称,而实例变量(静态函数)名直接在方法(函数)名前加双下划线(“__”),变为私有属性。
四、类的特殊成员方法
1. __doc__
打印类的描述信息(注释信息)。
2. __module__和 __class__
__module__:打印对象所属模块的模块名。
__class__:打印对象所属类的类名。
3. __init__
构造方法,通过类创建对象时,自动触发执行。
语法:
class Test(object):
def __init__(self):
pass
test = Test() # 执行__init__方法
4. __del__
在实例释放和销毁的时候执行,通常用于做一些收尾工作。如:关闭一些数据库连接,关闭已打开的临时文件,等。
def __del__(self):
函数体
当对象在内存中被释放时,自动触发执行。
- 注意:此方法一般无须定义,因为Python是一门高级语言,程序员在使用时无需关心内存的分配和释放,因为此工作都是交给Python解释器来执行,所以析构函数的调用是由解释器在进行垃圾回收时自动触发执行的。
5. __call__
实例化之后再调用,触发执行。即: 类名()() 或 实例对象名()
语法:
class Test(object):
def __init__(self):
pass
def __call__(self):
pass
test = Test() # 执行__init__方法
test() # 执行__call__方法
Test()() # 执行__init__方法后再执行__call__方法
6. __dict__
类调用,打印类中的所有属性;实例调用,打印当前实例的所有属性。
7. __str__
在类中定义 def \_\_str__(self) 方法,打印实例化对象(名)时可以打印出该方法的返回值。
8. __getitem__, __setitem__, __delitem__
用于索引操作,如字典。 __getitem__ 用于获取数据; __setitem__ 用于设置数据; __delitem__ 用于删除数据。
9. __new__ 和 __metaclass__
① Python万物皆对象
用于创建实例的,先于__init__执行,默认已写好,不需要写。
上述代码中,obj 是通过 Foo 类实例化的对象。其实,不仅 obj 是一个对象,Foo 类本身也是一个对象,因为在Python中一切皆对象。
所以可得如下结论:obj 对象是通过执行 Foo 类的构造方法创建;那么 Foo 类对象应该也是通过执行某个类的 构造方法而创建。而根据上述代码的执行结果来看,Foo 应为 type 类的实例对象,即:Foo类对象 是通过type类的构造方法创建。
② 类的创建方法:普通方法
③ 类的创建方法:特殊方法
类的特殊构造方法的作用和功能以及调用方式与普通构造方法相同,只是构造语法存在区别。
- 类的特殊构造方法语法:
def 函数名1(self):
函数体
def 函数名2(self):
函数体
...
def 函数名N(self):
函数体
类名 = type('类名', (object,), {'方法名1': 函数名1, '方法名2': 函数名2, ..., '方法名N': 函数名N})
- 注意:
语法中加引号的为字符串类型,没有引号的直接写相应内容即可。
-
type 函数的参数:
- 参数1:类名,字符串格式。
- 参数2:当前类的基类,元组格式,只有1个基类则需要有逗号。
- 参数3:类的成员,字典格式,键为类的方法名(字符串格式),值为对应的函数。
④ type 创建类和类创建实例对象的原理
类中有一个属性 __metaclass__ ,其用来表示该类由“谁”来实例化创建,所以,我们可以为 __metaclass__ 设置一个 type 类的派生类,从而查看类创建的过程。
10. 类的生成和调用顺序
__new__ → __init__ → __call__
五、反射
1. getattr
getattr(实例名, 属性/方法名[, 默认值])
调用实例当中的属性/方法。若属性存在,则打印属性值;若方法存在,则打印方法的内存地址。默认值可有可无,若设定默认值,则当属性/方法不存在时,返回默认值。
- 注意:实例名不加引号;属性/方法名和默认值加引号。
2. hasattr
hasattr(实例名, 属性/方法名)
判断对象中是否含有指定的属性/方法。有,返回True;没有,返回False。
- 注意:实例名不加引号,属性名加引号。
class Dog(object):
def __init__(self, name):
self.name = name
def eat(self):
print("%s is eating..." % self.name)
dog = Dog('Jackie')
choice = input(">>:").strip()
print(hasattr(dog, choice))
3. setattr
① 自定义字符串与函数关联
setattr(实例名, 字符串, 函数名)
意为:实例名.字符串 = 函数名
通过字符串设置新的属性。
- 注意:实例名和函数名不加引号,字符串加引号。
def dancing(self):
print('%s is dancing...' % self.name)
class Dog(object):
def __init__(self, name):
self.name = name
def eating(self):
print("%s is eating..." % self.name)
dog = Dog('Jackie')
setattr(dog, 'dance', dancing) # 即 dog.dance = dancing
print(dog.dance(dog)) # 即 dancing(dog)
- 注意:由于
dancing函数没有在Dog类中,因此它的参数“self”需要手动传入。
② 属性赋值
setattr(实例名, 属性名, 值)
给对象的属性赋值,若属性存在,则修改值;若属性不存在,则先创建属性再为属性赋值。
4. delattr
delattr(实例名, 属性名)
删除实例的指定属性。
六、异常处理
① 异常
简单来说,异常即错误。在Python无法正常处理程序时就会发生一个异常。
当发生异常时,程序会终止执行,因此,对异常的捕获和处理有助于我们在运行代码时规避错误而使代码正常执行。
② 语法
try:
<代码>
except <错误类型>: # try代码执行时如出现了异常(<错误类型>)则执行该代码
<代码>
else: # try代码执行没有异常时执行该代码
<代码>
finally: # 无论try代码执行是否有异常都会执行该代码
<代码>
③ 说明
异常处理的代码执行顺序为:执行try代码,若try代码能够正常执行,则直接执行后,执行else代码,最后执行finally代码;若try代码执行发生异常,且错误类型为except后指定的错误类型,则终止try代码的执行,执行except代码,最后执行finally代码。
finally语句可有可无,非必需。但finally语句和except语句必有其一。
except语句可以有多个,Python将按照except语句的顺序依次匹配异常,若异常被处理,则不再检索后续except语句。
-
捕捉错误信息:
except <错误类型> as e: print('错误信息:', e)其中,e表示错误日志,可以是任何字母或单词。as可以由英文逗号代替。
-
except可以处理多个错误类型,错误类型之间以英文逗号隔开需将所有错误类型用括号括起:
except (<错误类型1>, <错误类型2>, ..., <错误类型N>) as e: print('错误信息:', e) -
捕获所有异常:
except Exception as e: print('错误信息:', e)Exception须首字母大写。
-
不捕获错误信息的所有异常处理:
try: <代码> except: <代码> else: <代码>当try代码能够正常执行时,随后执行else代码;当try代码执行抛出异常时,无论什么异常(未指定错误类型),都执行except代码。
④ 常见的错误类型
| 错误类型 | 解释 |
|---|---|
| ArithmeticError | 所有数值计算错误的基类 |
| AssertionError | 断言语句失败 |
| AttributeError | 对象没有这个属性 |
| BaseException | 所有异常的基类 |
| DeprecationWarning | 关于被弃用的特征的警告 |
| EnvironmentError | 操作系统错误的基类 |
| EOFError | 没有内建输入,到达EOF 标记 |
| Exception | 常规错误的基类 |
| FloatingPointError | 浮点计算错误 |
| FutureWarning | 关于构造将来语义会有改变的警告 |
| GeneratorExit | 生成器(generator)发生异常来通知退出 |
| ImportError | 导入模块/对象失败 |
| IndentationError | 缩进错误 |
| IndexError | 序列中没有此索引(index) |
| IOError | 输入/输出操作失败 |
| KeyboardInterrupt | 用户中断执行(通常是输入^C) |
| KeyError | 映射中没有这个键 |
| LookupError | 无效数据查询的基类 |
| MemoryError | 内存溢出错误(对于Python 解释器不是致命的) |
| NameError | 未声明/初始化对象 (没有属性) |
| NotImplementedError | 尚未实现的方法 |
| OSError | 操作系统错误 |
| OverflowError | 数值运算超出最大限制 |
| OverflowWarning | 旧的关于自动提升为长整型(long)的警告 |
| PendingDeprecationWarning | 关于特性将会被废弃的警告 |
| ReferenceError | 弱引用(Weak reference)试图访问已经垃圾回收了的对象 |
| RuntimeError | 一般的运行时错误 |
| RuntimeWarning | 可疑的运行时行为(runtime behavior)的警告 |
| StandardError | 所有的内建标准异常的基类 |
| StopIteration | 迭代器没有更多的值 |
| SyntaxError | Python 语法错误 |
| SyntaxWarning | 可疑的语法的警告 |
| SystemError | 一般的解释器系统错误 |
| SystemExit | 解释器请求退出 |
| TabError | Tab 和空格混用 |
| TypeError | 对类型无效的操作 |
| UnboundLocalError | 访问未初始化的本地变量 |
| UnicodeDecodeError | Unicode 解码时的错误 |
| UnicodeEncodeError | Unicode 编码时错误 |
| UnicodeError | Unicode 相关的错误 |
| UnicodeTranslateError | Unicode 转换时错误 |
| UserWarning | 用户代码生成的警告 |
| ValueError | 传入无效的参数 |
| Warning | 警告的基类 |
| WindowsError | 系统调用失败 |
| ZeroDivisionError | 除(或取模)零 (所有数据类型) |
⑤ 触发异常
根据需要,可以使用raise语句自行触发异常,即自己报错。
语法:
raise <错误类型>
自定义错误信息:
raise Exception(错误信息)
⑥ 自定义错误
class 自定义错误名(Exception): # Exception为基类
def __init__(self, message): # message为错误信息
self.message = message
def __str__(self): # 打印e即调用的此方法。返回值为self.message,因此实例化时定义的错误原因就是显示的错误原因。由于Exception基类中已经有了__str__,因此除非需要额外增加内容,否则不必再写__str__方法。
return self.message
try:
raise 自定义错误名("错误原因")
except 自定义错误名 as e:
print(e) # 打印错误原因
第五部分:参考资料
Python 官方文档:PEP 8 -- Style Guide for Python Code
菜鸟教程:Python 编码规范(Google)
菜鸟教程:Python3 基本数据类型
菜鸟教程:Python 字典
菜鸟教程:Python3 条件控制
菜鸟教程:Python3 循环语句
菜鸟教程:Python 函数
Python官方文档:Built-in Functions
菜鸟教程:Python内置函数
python 最大递归次数 RuntimeError: maximum recursion depth exceeded
菜鸟教程:Python 日期和时间
菜鸟教程:Python OS 文件/目录方法
百度百科:编程
菜鸟教程:Python 异常处理
