目标
爬取知乎用户信息,并作简要分析。所爬的对象是关注者≥10的用户,因为:
- 关注者数量<10的用户,很多的僵尸用户、不活跃用户
- 我爬虫的目的也不是大而全,高质量用户更有分析意义
整体思路
JDK 环境
JDK 1.7
存储结构:redis
为什么使用 redis?
- 基于内存的存储,速度快,同时又具有持久性
- 开发非常简单
- 多种数据结构,自带排序功能
- 断电、异常时能保存结果
爬虫框架:webmagic
官方网站:http://webmagic.io/。
为什么使用 webmagic?
基于 Java 的 webmagic,开发极其简单,这个知乎爬虫的代码主体就几行,而且只要专注提取数据就行了(其实是因为我也不知道其它 Java 的爬虫框架)。
代理 IP
没有使用代理 IP,经测试开20个线程爬知乎会被封IP,我就开了3个线程。
爬取速度
30小时爬取了3w用户(关注者数量≥10的用户),确实慢了点(部分原因是知乎的网站结构,下面分析)。
分析知乎的网站结构
以一个我关注的知乎大佬为例,url 是:https://www.zhihu.com/people/warfalcon/answers
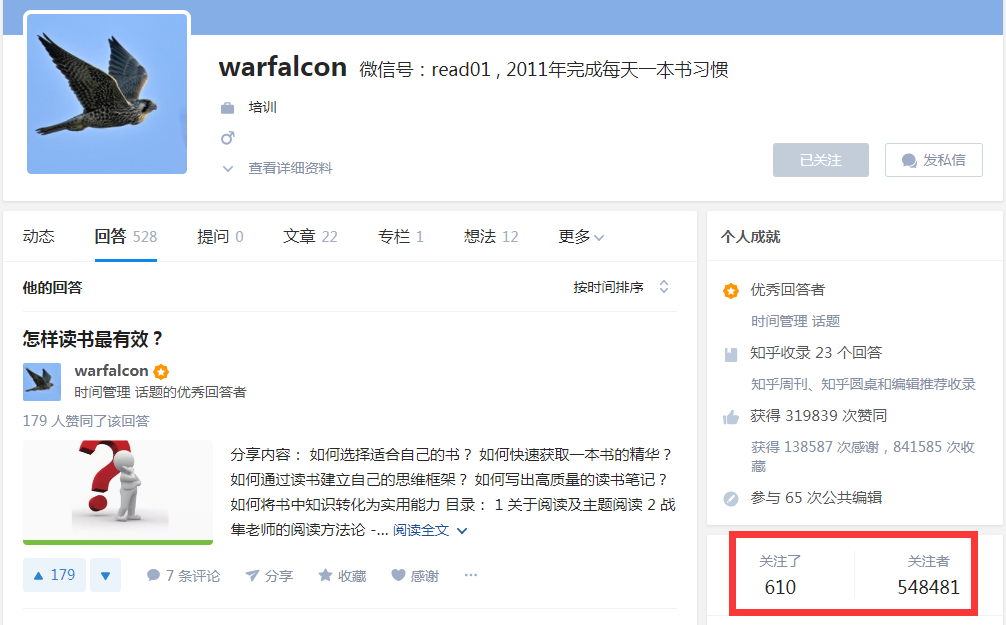
点击「关注者」,url 变成了:https://www.zhihu.com/people/warfalcon/followers,界面是这样的:
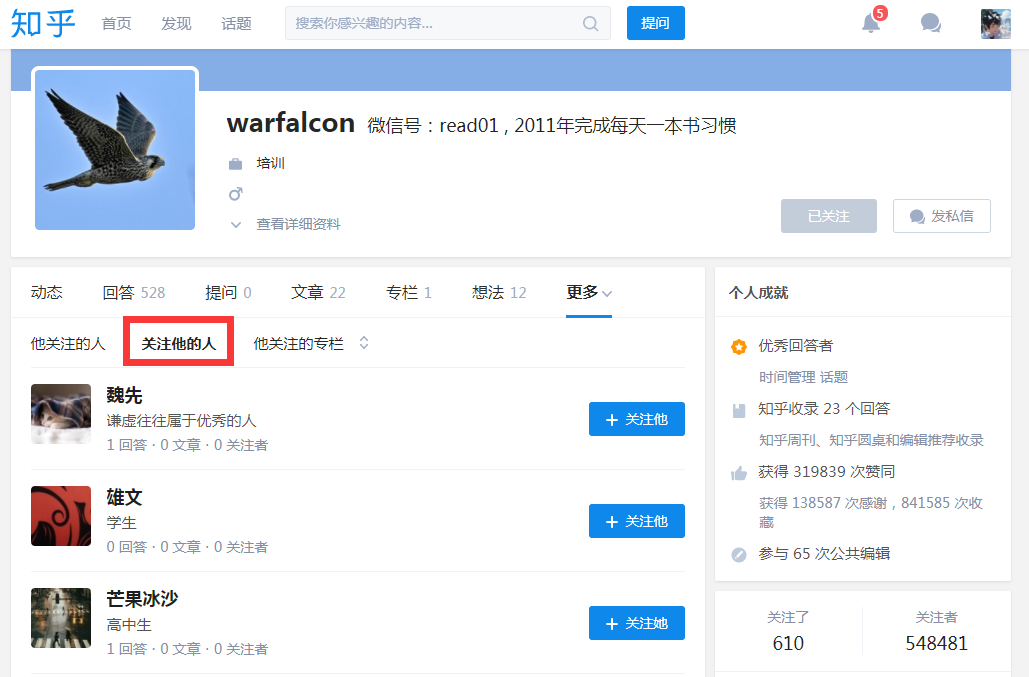
而点击「关注了」,url 变成了:https://www.zhihu.com/people/warfalcon/following,界面是这样的:
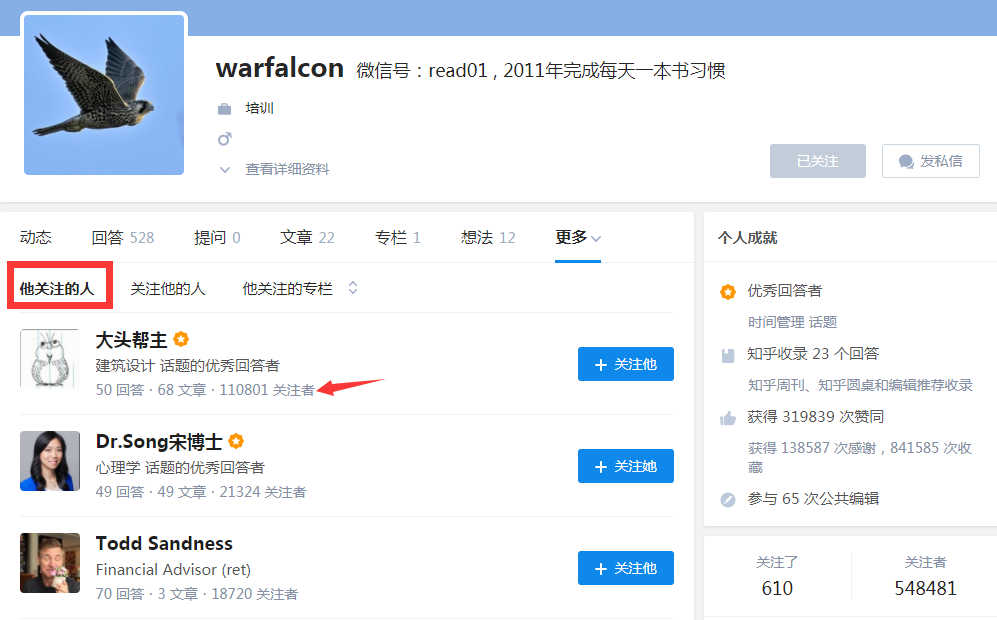
通过对比上面的3个 url,我们发现结构可能是下面这样的:
- https://www.zhihu.com是域名
- /people 代表是个人账号,美团的知乎账号是这样的:https://www.zhihu.com/org/mei-tuan-dian-ping-ji-shu-tuan-dui/activities,发现 /org 是企业账号
- 接下来的warfalcon是用户的唯一标识,和用户显示的名称是不一样的
- /answers是该用户回答的问题;/followers是关注了他的人;/following是他关注了的人。
而一般来说,一个用户「关注了」的人,比关注了这个用户的人更有价值:被关注的人更有可能是大V。对比上面的图片,发现warfalcon关注的人的关注者都是上万的,而关注他的人——至少前三个——都是0关注者。
确定爬虫的规则
warfalcon 关注的列表第一个用户是:大头帮主,在https://www.zhihu.com/people/warfalcon/following这里看到的网页结构是下面这样的:

但是爬虫出来的结果是没有这个div的,在整个 response 中搜索「大头帮主」,会发现存在于//div[@id='data']/@data-state结构中,将其所有的 "都替换成引号,就可以发现下面的 json 结构:
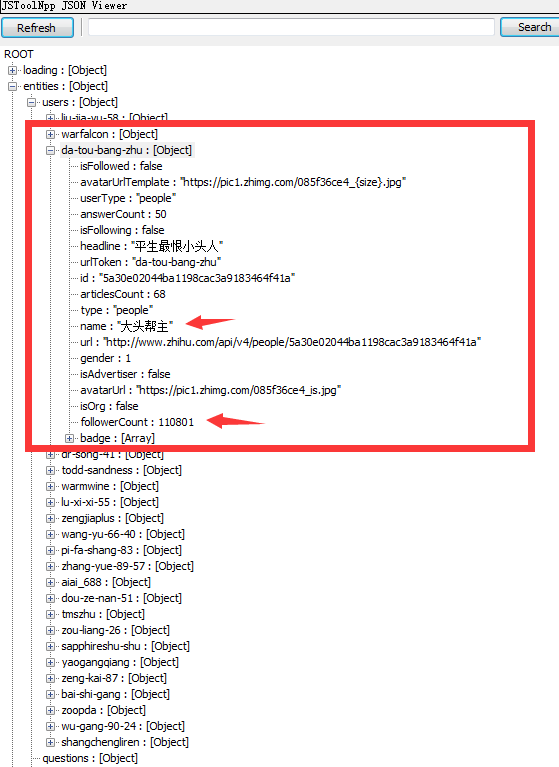
发现这里的 name 是「大头帮主」,其关注者数量和上面的截图一致,确认查找是正确的。这个json的常用字段:
isFollowed:对方是否关注了自己(猜测)
userType:用户类型,有 用户、企业等
answerCount:回答问题的数量
isFollowing:自己是否关注了对方(猜测)
urlToken:用户的唯一标识,url中用的就是这个字段
id:用户的id,唯一标识,不利于记忆,所以才有上面的urlToken,应该是一一对应的
name:用户的名称,可以自定义,所以可以重复
gender:1是男,0是女,-1表示未填写
isOrg:是否为企业账号,和上面的userType有一点冗余
followerCount:被关注者的数量
bedge:行业
但是这里缺少了一些信息:教育程度、居住地点呢?因为抓取的url是https://www.zhihu.com/people/warfalcon/following,分析他的json数据:
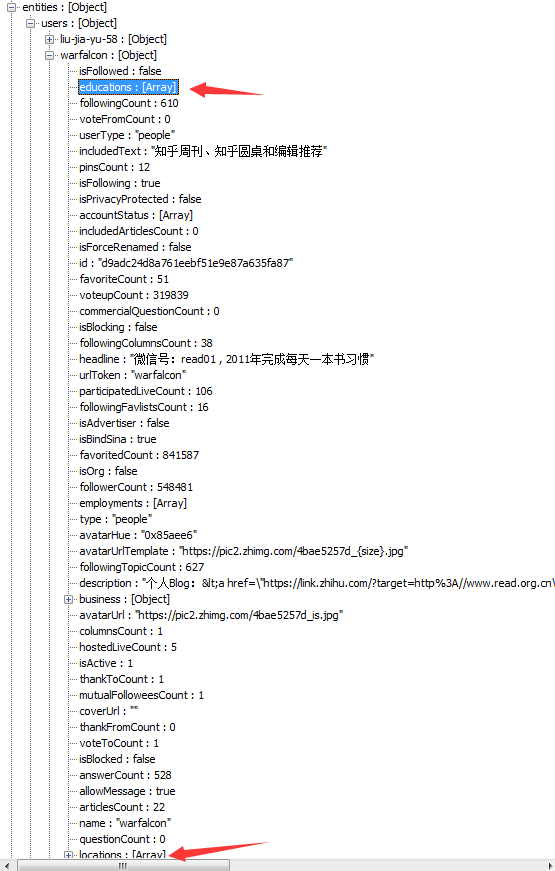
发现只有在访问对应的 urlToken 的用户时,才有教育程度、居住地点等信息,测试其它账号也是一样的(另,还有一个返回比较全的信息是个人信息)。
爬虫分页
该用户关注了610人,每页显示20人,正好需要31页。
发现第2页的 url 是:https://www.zhihu.com/people/warfalcon/following?page=2,只需要在原来的网址上加上参数 page 即可。
策略分析
我们需要爬取一个用户所关注的所有用户吗?我觉得并不需要。因为:
- 单个用户可能关注了1000人,且有1000人关注了他。这是一个复杂的网络,我觉得取用户关注的前两页(即40人),就足够了。
- 按照上面的分析,也没有必要将关注了他的用户放入待爬虫的列表。
- 仅followerCount>10的用户,才加入待爬虫列表。
- 仅在访问对应的urlToken时,才会将这个用户的信息存入redis中(因为仅此时才有教育信息、地点信息)。
- 如果redis中已经有了这个人的信息,则将其排除掉,也不要将其关注者放入待爬虫列表,否则会导致非常巨大的冗余,爬了一些人之后就会非常慢
分析爬虫结果
代码贴在文章结尾处(很短,核心就50行左右)。先分析下爬虫结果(仅爬到了3w数据,第一次想分析数据时,误删了所有爬虫数据……现在又爬了一遍,写博客的时候才爬到3w,就这样吧~),「粉丝用户最多的用户」、「回答数最多的用户」就不分析了。
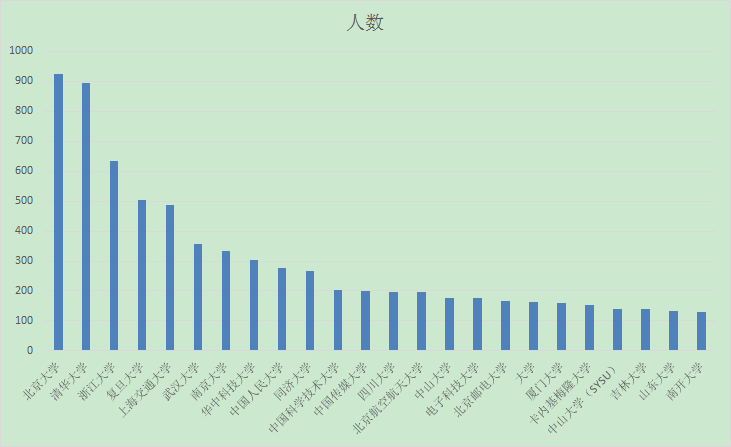
知乎用户高校排名
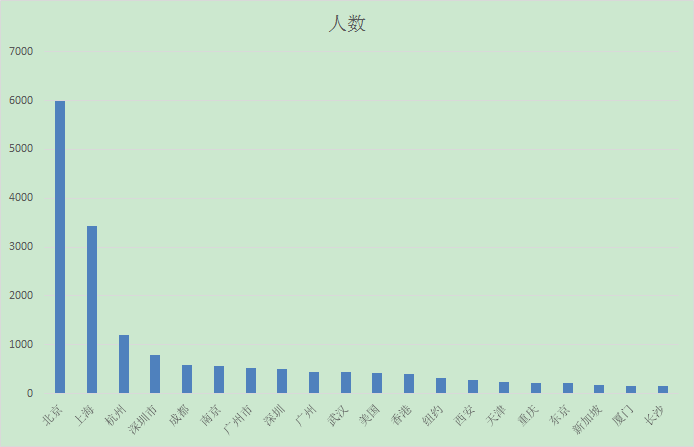
城市排名
代码
pom 文件
需要爬虫框架 webmagic。
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>0.7.3</version>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.7.3</version>
</dependency>
用户信息类
仅列出字段,get和set方法未列出。
public class ZhihuUserDo {
private boolean org;
private String type;
private int answerCount;
private int articlesCount;
private String name;
private int gender;
private String urlToken;
private int followerCount;
private int followingCount;
private String edu; // 仅自己才有
private String loc; // 仅自己才有
核心爬虫类
没有启动 web 服务,直接写的 main 函数运行。核心逻辑就是 process 函数,如果不获取第二页数据会简洁许多,对结果应该也不会造成影响。
public class ZhihuUserProcessor implements PageProcessor {
private Site site = Site.me().setCycleRetryTimes(1).setRetryTimes(1).setSleepTime(200).setTimeOut(3 * 1000)
.setUserAgent(
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36")
.addHeader("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8")
.addHeader("Accept-Language", "zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3").setCharset("UTF-8");
private static Jedis jedis = RedisUtil.getJedis();
private static final String MAP_KEY = "zhihu_user";
private static final int THRES_HOLD = 10;
private static final int USERS_ONE_PAGE = 20;
@Override
public void process(Page page) {
String dataJson = page.getHtml().xpath("//div[@id='data']/@data-state").all().get(0);
String urlString = page.getUrl().toString();
String urlToken = urlString.substring(START_LANGTH, urlString.lastIndexOf("/"));
JSONObject entities = (JSONObject) JSONObject.parseObject(dataJson).get("entities");
JSONObject users = entities.getJSONObject("users");
for (String key : users.keySet()) {
JSONObject object = users.getJSONObject(key);
ZhihuUserDo zhihuUserDo = JSONObject.parseObject(object.toString(), ZhihuUserDo.class);
/**
* 1. following 和 followers 都有自己的信息,只需要用一个即可 2. 仅自己,仅有edu 和 loc 信息
*/
if (zhihuUserDo.getUrlToken().equals(urlToken) && !urlString.contains("?page=")) {
if (jedis.hexists(MAP_KEY, urlToken)) {
continue;
}
// educations
Object educations = object.get("educations");
if (educations != null) {
JSONObject school = (JSONObject) JSON.parseArray(educations.toString()).get(0);
if (school != null) {
zhihuUserDo.setEdu(((JSONObject) school.get("school")).getString("name"));
}
}
// locations
Object locations = object.get("locations");
if (locations != null) {
JSONObject loc = (JSONObject) JSON.parseArray(locations.toString()).get(0);
if (loc != null) {
zhihuUserDo.setLoc(loc.getString("name"));
}
}
// 「关注了」需要分页,仅在本人信息中才有该字段
if (zhihuUserDo.getFollowingCount() > USERS_ONE_PAGE) {
int pagesTotal = zhihuUserDo.getFollowingCount() / USERS_ONE_PAGE + 1;
pagesTotal = Math.min(4, pagesTotal); // 防止「关注了」过多
List<String> urls = new ArrayList<>();
for (int i = 2; i <= pagesTotal; i++) {
urls.add(new StringBuilder(URL_START).append(urlToken).append(URL_FOLLOWING).append("?page=")
.append(i).toString());
}
page.addTargetRequests(urls);
}
jedis.hset(MAP_KEY, urlToken, JSON.toJSONString(zhihuUserDo));
} else {
// 如果被关注者>=10人,则加入爬虫队列
if (zhihuUserDo.getFollowerCount() >= THRES_HOLD
&& !jedis.hexists(MAP_KEY, zhihuUserDo.getUrlToken())) {
page.addTargetRequest(URL_START + zhihuUserDo.getUrlToken() + URL_FOLLOWING);
}
}
}
}
private static final String URL_START = "https://www.zhihu.com/people/";
private static final String URL_FOLLOWING = "/following";
private static final int START_LANGTH = URL_START.length();
public static void main(String[] args) {
start();
}
public static void start() {
List<String> urls = new ArrayList<>();
urls.add("https://www.zhihu.com/people/warfalcon/following");
urls.add("https://www.zhihu.com/people/warfalcon/followers");
Spider.create(new ZhihuUserProcessor()).addUrl(urls.get(0), urls.get(1)).thread(3).run();
}
@Override
public Site getSite() {
return site;
}
}
总结
- 爬虫结束后,想把 redis 数据从一台电脑转移到另一台电脑,小手一抖就给删除了……浪费了很长时间
- 仅开3个线程,是不需要代理IP的;爬取时也不需要随机休眠一段时间
- redis 存储用户信息使用的 json 格式,可能有些大。但是想想一个用户大概170字节,3w用户也就不到10M。
- 线程池、超时重试什么的都没管,都是 webmagic 框架做的
- 通过分析发现,知乎用户都是清北的,而且除了北上广深,居住在国外的用户也能占据30%
- 数据不准确,所爬的对象是
关注者≥10的用户 - 学校、居住地的分析并不严谨,因为地点
北京市海淀区并没有包括在北京中,学校也同理
