The Python Data Model
If you learned another object-oriented language before Python, you may have found it strange to use len(collection) instead of collection.len().
的确,面向对象语言一般使用object.method,而在这里python更像是函数式语言。
The Python interpreter invokes special methods to perform basic object operations, often triggered by special syntax. The special method names are always written with leading and trailing double underscores (i.e., __getitem__).
Special methods是理解Python语言的关键之一。例如,__getitem__特殊方法用来支持obj[key]。因此,当实现my_collection[key],解释器实际上调用的是my_collection.__getitem__(key)。
The term magic method is slang for special method. The special methods are also known as dunder methods.
A Pythonic Card Deck
The following is a very simple example, but it demonstrates the power of implementing just two special methods, __getitem__ and __len__.
import collections
Card = collections.namedtuple('Card', ['rank', 'suit'])
class FrenchDeck:
ranks = [str(n) for n in range(2, 11)] + list('JQKA')
suits = 'spades diamonds clubs hearts'.split()
def __init__(self):
self._cards = [Card(rank, suit) for suit in self.suits
for rank in self.ranks]
def __len__(self):
return len(self._cards)
def __getitem__(self, position):
return self._cards[position]
>>> beer_card = Card('7', 'diamonds')
>>> beer_card
Card(rank='7', suit='diamonds')
>>> deck = FrenchDeck()
>>> len(deck)
52
>>> deck[0]
Card(rank='2', suit='spades')
>>> deck[-1]
Card(rank='A', suit='hearts')
-
namedtuple
Here namedtuple can be used to build classes of objects that are just bundles of attributes with no custom methods, like a database record.
Python的collections模块是对基础container的拓展,其中包括namedtuple。
EmployeeRecord = namedtuple('EmployeeRecord', 'name, age, title, department, paygrade')
Should we create a method to pick a random card? No need. Python already has a function to get a random item from a sequence: random.choice.
>>> from random import choice
>>> choice(deck)
Card(rank='3', suit='hearts')
>>> choice(deck)
Card(rank='K', suit='spades')
>>> choice(deck)
Card(rank='2', suit='clubs')
We’ve just seen two advantages of using special methods to leverage the Python data model:
The users of your classes don’t have to memorize arbitrary method names for standard operations (“How to get the number of items? Is it .size(), .length(), or what?”).
It’s easier to benefit from the rich Python standard library and avoid reinventing the wheel, like the random.choice function.
这里提到Python Data Model的优点在于两点:利用special method构建类的统一方法,便于记忆;可以充分利用丰富的python标准库。
But it gets better. Just by implementing the __getitem__ special method, our deck is also iterable:
>>> for card in deck: # doctest: +ELLIPSIS
... print(card)
Card(rank='2', suit='spades')
Card(rank='3', suit='spades')
Card(rank='4', suit='spades')
...
>>> for card in reversed(deck): # doctest: +ELLIPSIS
... print(card)
Card(rank='A', suit='hearts')
Card(rank='K', suit='hearts')
Card(rank='Q', suit='hearts')
...
有趣的是,通过实现__getitem__特殊方法,我们的类是可迭代的。
Iteration is often implicit. If a collection has no __contains__ method, the in operator does a sequential scan.
>>> Card('Q', 'hearts') in deck
True
>>> Card('7', 'beasts') in deck
False
特殊方法__contains__是用来进行in检验的。
How about sorting? A common system of ranking cards is by rank (with aces being highest), then by suit in the order of spades (highest), then hearts, diamonds, and clubs (lowest). Here is a function that ranks cards by that rule, returning 0 for the 2 of clubs and 51 for the ace of spades:
suit_values = dict(spades=3, hearts=2, diamonds=1, clubs=0)
def spades_high(card):
rank_value = FrenchDeck.ranks.index(card.rank)
return rank_value * len(suit_values) + suit_values[card.suit]
>>> for card in sorted(deck, key=spades_high):
... print(card)
Card(rank='2', suit='clubs')
Card(rank='2', suit='diamonds')
Card(rank='2', suit='hearts')
... (46 cards ommitted)
Card(rank='A', suit='diamonds')
Card(rank='A', suit='hearts')
Card(rank='A', suit='spades')
Although FrenchDeck implicitly inherits from object, its functionality is not inherited, but comes from leveraging the data model and composition.
By implementing the special methods __len__ and __getitem__, our FrenchDeck behaves like a standard Python sequence, allowing it to benefit from core language features (e.g., iteration and slicing) and from the standard library, as shown by the examples using random.choice, reversed, and sorted.
How Special Methods Are Used
The first thing to know about special methods is that they are meant to be called by the Python interpreter, and not by you.
More often than not, the special method call is implicit. For example, the statement for i in x: actually causes the invocation of iter(x), which in turn may call x.__iter__() if that is available.
Normally, your code should not have many direct calls to special methods. Unless you are doing a lot of metaprogramming, you should be implementing special methods more often than invoking them explicitly.
The only special method that is frequently called by user code directly is __init__, to invoke the initializer of the superclass in your own __init__ implementation.
If you need to invoke a special method, it is usually better to call the related built-in function (e.g., len, iter, str, etc). These built-ins call the corresponding special method, but often provide other services and—for built-in types—are faster than method calls.
这段的内涵需要好好领会。
Emulating Numeric Types
We will implement a class to represent two-dimensional vectors—that is Euclidean vectors like those used in math and physics
from math import hypot
class Vector:
def __init__(self, x=0, y=0):
self.x = x
self.y = y
def __repr__(self):
return 'Vector(%r, %r)' % (self.x, self.y)
def __abs__(self):
return hypot(self.x, self.y)
def __bool__(self):
return bool(abs(self))
def __add__(self, other):
x = self.x + other.x
y = self.y + other.y
return Vector(x, y)
def __mul__(self, scalar):
return Vector(self.x * scalar, self.y * scalar)
>>> v1 = Vector(2, 4)
>>> v2 = Vector(2, 1)
>>> v1 + v2
Vector(4, 5)
>>> v = Vector(3, 4)
>>> abs(v)
5.0
>>> v * 3
Vector(9, 12)
>>> abs(v * 3)
15.0
String Representation
The __repr__ special method is called by the repr built-in to get the string representation of the object for inspection. If we did not implement __repr__, vector instances would be shown in the console like <Vector object at 0x10e100070>.
Speaking of the % operator and the str.format method, you will notice I use both in this book, as does the Python community at large. I am increasingly favoring the more powerful str.for mat, but I am aware many Pythonistas prefer the simpler %, so we’ll probably see both in Python source code for the foreseeable future.
这里讨论了两种字符串表达方式%和str.fromat。这里作者混用了。
Contrast __repr__ with __str__, which is called by the str() constructor and implicitly used by the print function. __str__ should return a string suitable for display to end users.
对于__repr__和__str__的不同之处。前者是用来给开发者看的,而后者被print函数隐性调用,用来显示给终端用户。如果你只实现其中的一种,选择前者。因为如果用户没有实现后者,那么Python会调用前者作为回馈。
Arithmetic Operators
Here implements two operators: + and *, to show basic usage of __add__ and __mul__. Note that in both cases, the methods create and return a new instance of Vector, and do not modify either operand—self or other are merely read.
This is the expected behavior of infix operators: to create new objects and not touch their operands.
注意返回的类型。
Boolean Value of a Custom Type
To determine whether a value x is truthy or falsy, Python applies bool(x), which always returns True or False.
By default, instances of user-defined classes are considered truthy, unless either __bool__ or __len__ is implemented. Basically, bool(x) calls x.__bool__() and uses the result. If __bool__ is not implemented, Python tries to invoke x.__len__(), and if that returns zero, bool returns False. Otherwise bool returns True.
特殊方法__bool__用来实现用户类实例的布尔值。
Overview of Special Methods


Why len Is Not a Method
The answer was a quote from The Zen of Python: “practicality beats purity.” I described how len(x) runs very fast when x is an instance of a built-in type.
In other words, len is not called as a method because it gets special treatment as part of the Python data model, just like abs. But thanks to the special method __len__, you can also make len work with your own custom objects. This is a fair compromise between the need for efficient built-in objects and the consistency of the language. Also from The Zen of Python: “Special cases aren’t special enough to break the rules.”
这里说明了special方法的初衷,在效率和语言的一致性间的妥协处理。
Chapter Summary
By implementing special methods, your objects can behave like the built-in types, enabling the expressive coding style the community considers Pythonic.
Further Reading
The “Data Model” chapter of The Python Language Reference is the canonical source for the subject of this chapter and much of this book.
Python in a Nutshell, 2nd Edition (O’Reilly) by Alex Martelli has excellent coverage of the data model.
David Beazley has two books covering the data model in detail in the context of Python 3: Python Essential Reference, 4th Edition (Addison-Wesley Professional), and Python Cookbook, 3rd Edition (O’Reilly), coauthored with Brian K. Jones.
The Art of the Metaobject Protocol (AMOP, MIT Press) by Gregor Kiczales, Jim des Rivieres, and Daniel G. Bobrow explains the concept of a metaobject protocol (MOP), of which the Python data model is one example.
An Array of Sequences
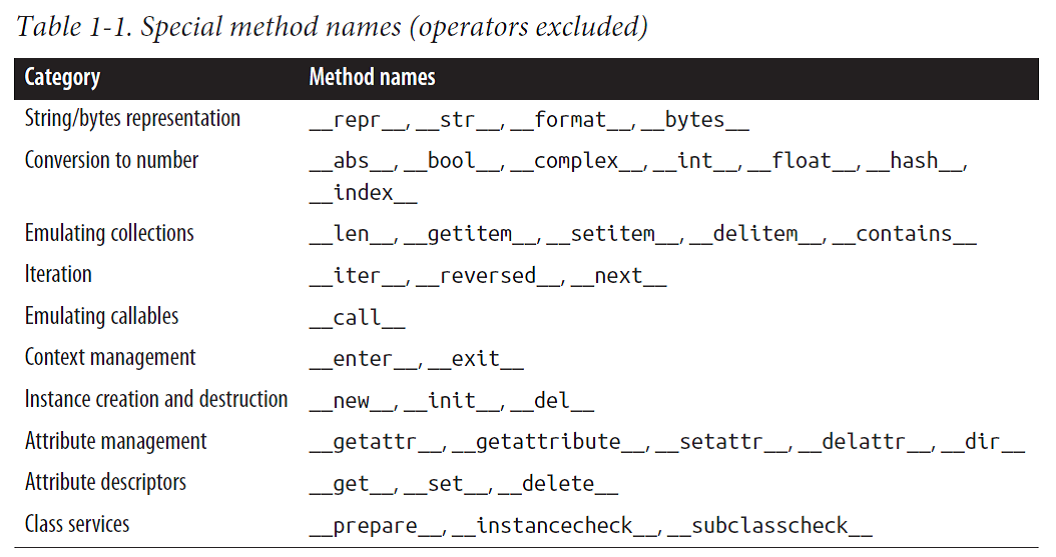
Overview of Built-In Sequences
Container sequences:list, tuple, and collections.deque can hold items of different types.
Flat sequences:str, bytes, bytearray, memoryview, and array.array hold items of one type.
Container sequences hold references to the objects they contain, which may be of any type, while flat sequences physically store the value of each item within its own memory space, and not as distinct objects. Thus, flat sequences are more compact, but they are limited to holding primitive values like characters, bytes, and numbers.
这两类的差别在于,前者变量储存的是引用,后者储存的是值。
Another way of grouping sequence types is by mutability(可变性):
Mutable sequences:list, bytearray, array.array, collections.deque, and memoryview
Immutable sequences:tuple, str, and bytes
Note that the built-in concrete sequence types do not actually subclass the Sequence and MutableSequence abstract base classes (ABCs) depicted, but the ABCs are still useful as a formalization of what functionality to expect from a full-featured sequence type.
List Comprehensions and Generator Expressions
A quick way to build a sequence is using a list comprehension (if the target is a list) or a generator expression (for all other kinds of sequences).
For brevity, many Python programmers refer to list comprehensions as listcomps, and generator expressions as genexps. I will use these words as well.
List Comprehensions and Readability
A listcomp is meant to do one thing only: to build a new list.
>>> symbols = '$¢£¥€¤'
>>> codes = [ord(symbol) for symbol in symbols]
>>> codes
[36, 162, 163, 165, 8364, 164]
If the list comprehension spans more than two lines, it is probably best to break it apart or rewrite as a plain old for loop.
In Python code, line breaks are ignored inside pairs of [], {}, or (). So you can build multiline lists, listcomps, genexps, dictionaries and the like without using the ugly \ line continuation escape.
Generator Expressions
To initialize tuples, arrays, and other types of sequences, you could also start from a listcomp, but a genexp saves memory because it yields items one by one using the iterator protocol instead of building a whole list just to feed another constructor.
genexp更能够节约内存。
Genexps use the same syntax as listcomps, but are enclosed in parentheses rather than brackets.
>>> symbols = '$¢£¥€¤'
>>> tuple(ord(symbol) for symbol in symbols)
(36, 162, 163, 165, 8364, 164)
>>> import array
>>> array.array('I', (ord(symbol) for symbol in symbols))
array('I', [36, 162, 163, 165, 8364, 164])
Tuples Are Not Just Immutable Lists
Tuples do double duty: they can be used as immutable lists and also as records with no field names.
Tuples as Records
Here shows tuples being used as records. Note that in every expression, sorting the tuple would destroy the information because the meaning of each data item is given by its position in the tuple.
>>> lax_coordinates = (33.9425, -118.408056)
>>> city, year, pop, chg, area = ('Tokyo', 2003, 32450, 0.66, 8014)
>>> traveler_ids = [('USA', '31195855'), ('BRA', 'CE342567'),
... ('ESP', 'XDA205856')]
>>> for passport in sorted(traveler_ids):
... print('%s/%s' % passport)
...
BRA/CE342567
ESP/XDA205856
USA/31195855
>>> for country, _ in traveler_ids:
... print(country)
...
USA
BRA
ESP
Tuple Unpacking
Tuple unpacking works with any iterable object. The most visible form of tuple unpacking is parallel assignment; that is, assigning items from an iterable to a tuple of variables.
>>> lax_coordinates = (33.9425, -118.408056)
>>> latitude, longitude = lax_coordinates # tuple unpacking
>>> latitude
33.9425
>>> longitude
-118.408056
>>> b, a = a, b
Another example of tuple unpacking is prefixing an argument with a star when calling a function.
>>> divmod(20, 8)
(2, 4)
>>> t = (20, 8)
>>> divmod(*t)
(2, 4)
>>> quotient, remainder = divmod(*t)
>>> quotient, remainder
(2, 4)
>>> import os
>>> _, filename = os.path.split('/home/luciano/.ssh/idrsa.pub')
>>> filename
'idrsa.pub'
Using * to grab excess items
Defining function parameters with *args to grab arbitrary excess arguments is a classic Python feature.
>>> a, b, *rest = range(5)
>>> a, b, rest
(0, 1, [2, 3, 4])
>>> a, b, *rest = range(3)
>>> a, b, rest
(0, 1, [2])
>>> a, b, *rest = range(2)
>>> a, b, rest
(0, 1, [])
>>> a, *body, c, d = range(5)
>>> a, body, c, d
(0, [1, 2], 3, 4)
>>> *head, b, c, d = range(5)
>>> head, b, c, d
([0, 1], 2, 3, 4)
Nested Tuple Unpacking
metro_areas = [
('Tokyo', 'JP', 36.933, (35.689722, 139.691667)),
('Delhi NCR', 'IN', 21.935, (28.613889, 77.208889)),
('Mexico City', 'MX', 20.142, (19.433333, -99.133333)),
('New York-Newark', 'US', 20.104, (40.808611, -74.020386)),
('Sao Paulo', 'BR', 19.649, (-23.547778, -46.635833)),
]
print('{:15} | {:^9} | {:^9}'.format('', 'lat.', 'long.'))
fmt = '{:15} | {:9.4f} | {:9.4f}'
for name, cc, pop, (latitude, longitude) in metro_areas:
if longitude <= 0:
print(fmt.format(name, latitude, longitude))
there is a missing feature when using them as records: sometimes it is desirable to name the fields. That is why the namedtuple function was invented.
Named Tuples
The collections.namedtuple function is a factory that produces subclasses of tuple enhanced with field names and a class name—which helps debugging.
>>> from collections import namedtuple
>>> City = namedtuple('City', 'name country population coordinates')
>>> tokyo = City('Tokyo', 'JP', 36.933, (35.689722, 139.691667))
>>> tokyo
City(name='Tokyo', country='JP', population=36.933, coordinates=(35.689722,139.691667))
>>> tokyo.population
36.933
>>> tokyo.coordinates
(35.689722, 139.691667)
>>> tokyo[1]
'JP'
>>> City._fields
('name', 'country', 'population', 'coordinates')
>>> LatLong = namedtuple('LatLong', 'lat long')
>>> delhi_data = ('Delhi NCR', 'IN', 21.935, LatLong(28.613889, 77.208889))
>>> delhi = City._make(delhi_data)
>>> delhi._asdict()
OrderedDict([('name', 'Delhi NCR'), ('country', 'IN'), ('population', 21.935), ('coordinates', LatLong(lat=28.613889, long=77.208889))])
>>> for key, value in delhi._asdict().items():
print(key + ':', value)
name: Delhi NCR
country: IN
population: 21.935
coordinates: LatLong(lat=28.613889, long=77.208889)
_fields is a tuple with the field names of the class.
_make() allow you to instantiate a named tuple from an iterable; City(*del hi_data) would do the same.
_asdict() returns a collections.OrderedDict built from the named tuple instance. That can be used to produce a nice display of city data.
Slicing
A common feature of list, tuple, str, and all sequence types in Python is the support of slicing operations, which are more powerful than most people realize.
Slice Objects
>>> s = 'bicycle'
>>> s[::3]
'bye'
>>> s[::-1]
'elcycib'
>>> s[::-2]
'eccb'
>>> deck[12::13]
[Card(rank='A', suit='spades'), Card(rank='A', suit='diamonds'), Card(rank='A', suit='clubs'), Card(rank='A', suit='hearts')]
The notation a:b:c is only valid within [ ] when used as the indexing or subscript operator, and it produces a slice object: slice(a, b, c).
To evaluate the expression seq[start:stop:step], Python calls seq.__getitem__(slice(start, stop, step)).
Even if you are not implementing your own sequence types, knowing about slice objects is useful because it lets you assign names to slices, just like spreadsheets allow naming of cell ranges. For example,SKU = slice(0, 6).
Multidimensional Slicing and Ellipsis
The [ ] operator can also take multiple indexes or slices separated by commas. For instance, in the external NumPy package, where items of a two-dimensional numpy.ndarray can be fetched using the syntax a[i, j] and a two-dimensional slice obtained with an expression like a[m:n, k:l].
The __getitem__ and __setitem__ special methods that handle the [ ] operator simply receive the indices in a[i, j] as a tuple. In other words, to evaluate a[i, j], Python calls a.__getitem__((i, j)).
The built-in sequence types in Python are one-dimensional, so they support only one index or slice, and not a tuple of them.
The ellipsis—written with three full stops (...) and not … (Unicode U+2026)—is recognized as a token by the Python parser. As such, it can be passed as an argument to functions and as part of a slice specification, as in f(a, ..., z) or a[i:...]. NumPy uses ... as a shortcut when slicing arrays of many dimensions; for example, if x is a fourdimensional array, x[i, ...] is a shortcut for x[i, :, :, :,].
Assigning to Slices
Mutable sequences can be grafted, excised, and otherwise modified in place using slice notation on the left side of an assignment statement or as the target of a del statement.
>>> l = list(range(10))
>>> l
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> l[2:5] = [20, 30]
>>> l
[0, 1, 20, 30, 5, 6, 7, 8, 9]
>>> del l[5:7]
>>> l
[0, 1, 20, 30, 5, 8, 9]
>>> l[3::2] = [11, 22]
>>> l
[0, 1, 20, 11, 5, 22, 9]
>>> l[2:5] = 100
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: can only assign an iterable
>>> l[2:5] = [100]
>>> l
[0, 1, 100, 22, 9]
Using + and * with Sequences
Python programmers expect that sequences support + and *. Both + and * always create a new object, and never change their operands.
>>> l = [1, 2, 3]
>>> l * 5
[1, 2, 3, 1, 2, 3, 1, 2, 3, 1, 2, 3, 1, 2, 3]
>>> 5 * 'abcd'
'abcdabcdabcdabcdabcd'
Building Lists of Lists
The best way of doing so is with a list comprehension.
>>> board = [['_'] * 3 for i in range(3)]
>>> board
[['_', '_', '_'], ['_', '_', '_'], ['_', '_', '_']]
>>> board[1][52] = 'X'
>>> board
[['_', '_', '_'], ['_', '_', 'X'], ['_', '_', '_']]
>>> weird_board = [['_'] * 3] * 3
>>> weird_board
[['_', '_', '_'], ['_', '_', '_'], ['_', '_', '_']]
>>> weird_board[1][62] = 'O'
>>> weird_board
[['_', '_', 'O'], ['_', '_', 'O'], ['_', '_', 'O']]
Augmented Assignment with Sequences
The special method that makes += work is __iadd__ (for “in-place addition”). However, if __iadd__ is not implemented, Python falls back to calling __add__.
>>> l = [1, 2, 3]
>>> id(l)
4311953800
>>> l *= 2
>>> l
[1, 2, 3, 1, 2, 3]
>>> id(l)
4311953800
>>> t = (1, 2, 3)
>>> id(t)
4312681568
>>> t *= 2
>>> id(t)
4301348296
list.sort and the sorted Built-In Function
The list.sort method sorts a list in place—that is, without making a copy. It returns None to remind us that it changes the target object, and does not create a new list.
This is an important Python API convention: functions or methods that change an object in place should return None to make it clear to the caller that the object itself was changed, and no new object was created.
In contrast, the built-in function sorted creates a new list and returns it.
>>> fruits = ['grape', 'raspberry', 'apple', 'banana']
>>> sorted(fruits)
['apple', 'banana', 'grape', 'raspberry']
>>> fruits
['grape', 'raspberry', 'apple', 'banana']
>>> sorted(fruits, reverse=True)
['raspberry', 'grape', 'banana', 'apple']
>>> sorted(fruits, key=len)
['grape', 'apple', 'banana', 'raspberry']
>>> sorted(fruits, key=len, reverse=True)
['raspberry', 'banana', 'grape', 'apple']
>>> fruits
['grape', 'raspberry', 'apple', 'banana']
>>> fruits.sort()
>>> fruits
['apple', 'banana', 'grape', 'raspberry']
Once your sequences are sorted, they can be very efficiently searched.
Managing Ordered Sequences with bisect
The bisect module offers two main functions—bisect and insort—that use the binary search algorithm to quickly find and insert items in any sorted sequence.
Searching with bisect
import bisect
import sys
HAYSTACK = [1, 4, 5, 6, 8, 12, 15, 20, 21, 23, 23, 26, 29, 30]
NEEDLES = [0, 1, 2, 5, 8, 10, 22, 23, 29, 30, 31]
ROW_FMT = '{0:2d} @ {1:2d} {2}{0:<2d}'
def demo(bisect_fn):
for needle in reversed(NEEDLES):
position = bisect_fn(HAYSTACK, needle)
offset = position * ' |'
print(ROW_FMT.format(needle, position, offset))
if __name__ == '__main__':
if sys.argv[-1] == 'left':
bisect_fn = bisect.bisect_left
else:
bisect_fn = bisect.bisect
print('DEMO:', bisect_fn.__name__) # <5>
print('haystack ->', ' '.join('%2d' % n for n in HAYSTACK))
demo(bisect_fn)
An interesting application of bisect is to perform table lookups by numeric values — for example, to convert test scores to letter grades.
>>> def grade(score, breakpoints=[60, 70, 80, 90], grades='FDCBA'):
... i = bisect.bisect(breakpoints, score)
... return grades[i]
...
>>> [grade(score) for score in [33, 99, 77, 70, 89, 90, 100]]
['F', 'A', 'C', 'C', 'B', 'A', 'A']
Inserting with bisect.insort
Sorting is expensive, so once you have a sorted sequence, it’s good to keep it that way. insort(seq, item) inserts item into seq so as to keep seq in ascending order.
import bisect
import random
SIZE = 7
random.seed(1729)
my_list = []
for i in range(SIZE):
new_item = random.randrange(SIZE*2)
bisect.insort(my_list, new_item)
print('%2d ->' % new_item, my_list)
When a List Is Not the Answer
If you need to store 10 million floating-point values, an array is much more efficient, because an array does not actually hold full-fledged float objects, but only the packed bytes representing their machine values—just like an array in the C language.
On the other hand, if you are constantly adding and removing items from the ends of a list as a FIFO or LIFO data structure, a deque (double-ended queue) works faster.
If your code does a lot of containment checks (e.g., item in my_collection), consider using a set for my_collection, especially if it holds a large number of items.
这里讨论选择不同的数据结构的优劣,其中包括list,array,deque以及set。
Arrays
If the list will only contain numbers, an array.array is more efficient than a list. It supports all mutable sequence operations (including .pop, .insert, and .extend), and additional methods for fast loading and saving such as .frombytes and .tofile.
A Python array is as lean as a C array. When creating an array, you provide a typecode, a letter to determine the underlying C type used to store each item in the array.
>>> from array import array
>>> from random import random
>>> floats = array('d', (random() for i in range(10**7)))
>>> floats[-1]
0.07802343889111107
>>> fp = open('floats.bin', 'wb')
>>> floats.tofile(fp)
>>> fp.close()
>>> floats2 = array('d')
>>> fp = open('floats.bin', 'rb')
>>> floats2.fromfile(fp, 10**7)
>>> fp.close()
>>> floats2[-1]
0.07802343889111107
>>> floats2 == floats
True
Another fast and more flexible way of saving numeric data is the pickle module for object serialization.
As of Python 3.4, the array type does not have an in-place sort method like list.sort(). If you need to sort an array, use the sorted function to rebuild it sorted:
a = array.array(a.typecode, sorted(a))
To keep a sorted array sorted while adding items to it, use the bisect.insort function.
Memory Views
The built-in memorview class is a shared-memory sequence type that lets you handle slices of arrays without copying bytes. memoryview.cast returns yet another memoryview object, always sharing the same memory.
>>> numbers = array.array('h', [-2, -1, 0, 1, 2])
>>> memv = memoryview(numbers)
>>> len(memv)
5
>>> memv[0]
-2
>>> memv_oct = memv.cast('B')
>>> memv_oct.tolist()
[254, 255, 255, 255, 0, 0, 1, 0, 2, 0]
>>> memv_oct[5] = 4
NumPy and SciPy
For advanced array and matrix operations, NumPy and SciPy are the reason why Python became mainstream in scientific computing applications.
Deques and Other Queues
Inserting and removing from the left of a list (the 0-index end) is costly because the entire list must be shifted.
The class collections.deque is a thread-safe double-ended queue designed for fast inserting and removing from both ends. It is also the way to go if you need to keep a list of “last seen items” or something like that, because a deque can be bounded.
>>> from collections import deque
>>> dq = deque(range(10), maxlen=10)
>>> dq
deque([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], maxlen=10)
>>> dq.rotate(3)
>>> dq
deque([7, 8, 9, 0, 1, 2, 3, 4, 5, 6], maxlen=10)
>>> dq.rotate(-4)
>>> dq
deque([1, 2, 3, 4, 5, 6, 7, 8, 9, 0], maxlen=10)
>>> dq.appendleft(-1)
>>> dq
deque([-1, 1, 2, 3, 4, 5, 6, 7, 8, 9], maxlen=10)
>>> dq.extend([11, 22, 33])
>>> dq
deque([3, 4, 5, 6, 7, 8, 9, 11, 22, 33], maxlen=10)
>>> dq.extendleft([10, 20, 30, 40])
>>> dq
deque([40, 30, 20, 10, 3, 4, 5, 6, 7, 8], maxlen=10)
The append and popleft operations are atomic, so deque is safe to use as a LIFO queue in multithreaded applications without the need for using locks.
Besides deque, other Python standard library packages implement queues:
queue: This provides the synchronized (i.e., thread-safe) classes Queue, LifoQueue, and PriorityQueue.
multiprocessing: Implements its own bounded Queue, very similar to queue.
Further Reading
Chapter 1, “Data Structures” of Python Cookbook, 3rd Edition (O’Reilly) by David Beazley and Brian K. Jones has many recipes focusing on sequences.
The official Python Sorting HOW TO has several examples of advanced tricks for using sorted and list.sort.
Eli Bendersky’s blog post "Less Copies in Python with the Buffer Protocol and memoryviews" includes a short tutorial on memoryview.
There are numerous books covering NumPy in the market, even some that don’t mention “NumPy” in the title. Wes McKinney’s Python for Data Analysis (O’Reilly) is one such title.
Dictionaries and Sets
Module namespaces, class and instance attributes, and function keyword arguments are some of the fundamental constructs where dictionaries are deployed. The built-in functions live in __builtins__.__dict__.
Because of their crucial role, Python dicts are highly optimized. Hash tables are the engines behind Python’s high-performance dicts.
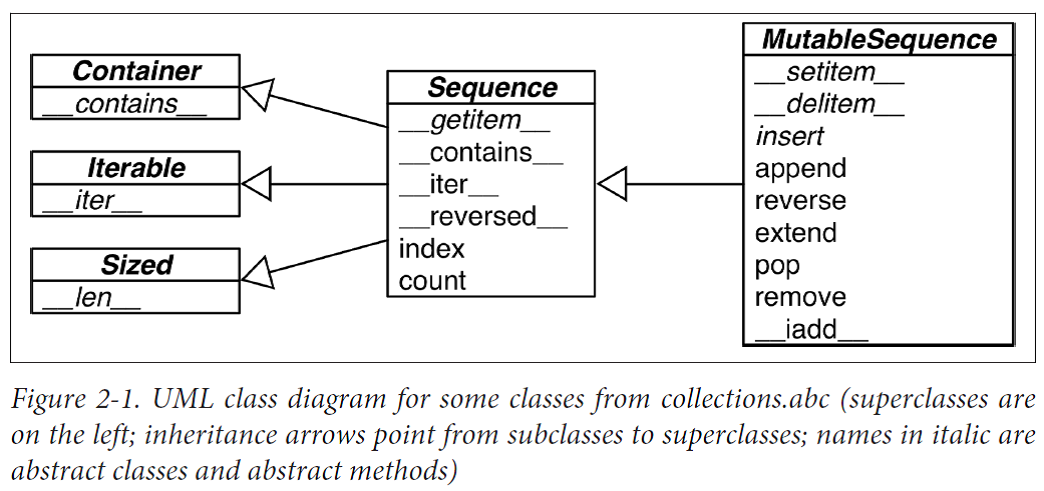
Generic Mapping Types
The collections.abc module provides the Mapping and MutableMapping ABCs to formalize the interfaces of dict and similar types
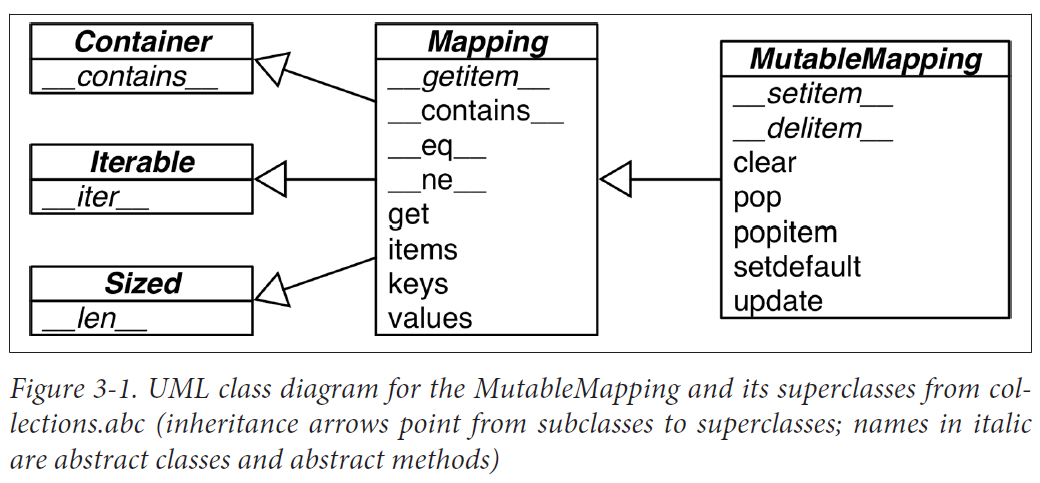
Implementations of specialized mappings often extend dict or collections.User Dict, instead of these ABCs. The main value of the ABCs is documenting and formalizing the minimal interfaces for mappings, and serving as criteria for isinstance tests in code that needs to support mappings in a broad sense.
>>> my_dict = {}
>>> isinstance(my_dict, abc.Mapping)
True
All mapping types in the standard library use the basic dict in their implementation, so they share the limitation that the keys must be hashable (the values need not be hashable, only the keys).
What Is Hashable? An object is hashable if it has a hash value which never changes during its lifetime (it needs a __hash__() method), and can be compared to other objects (it needs an __eq__() method). Hashable objects which compare equal must have the same hash value.
The atomic immutable types (str, bytes, numeric types) are all hashable. A frozen set is always hashable, because its elements must be hashable by definition. A tuple is hashable only if all its items are hashable.
>> tt = (1, 2, (30, 40)) >> hash(tt)
8027212646858338501
tl = (1, 2, [30, 40])
hash(tl)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'list'
tf = (1, 2, frozenset([30, 40]))
hash(tf)
-4118419923444501110User-defined types are hashable by default because **their hash value is their id()** and they all compare not equal. If an object implements a custom **\_\_eq\_\_** that takes into account its internal state, it may be hashable only if all its attributes are immutable.
Given these ground rules, you can build dictionaries in several ways.
>>> a = dict(one=1, two=2, three=3)
>>> b = {'one': 1, 'two': 2, 'three': 3}
>>> c = dict(zip(['one', 'two', 'three'], [1, 2, 3]))
>>> d = dict([('two', 2), ('one', 1), ('three', 3)])
>>> e = dict({'three': 3, 'one': 1, 'two': 2})
>>> a == b == c == d == e
True
Handling Missing Keys with setdefault
In line with the fail-fast philosophy, dict access with d[k] raises an error when k is not an existing key. Every Pythonista knows that d.get(k, default) is an alternative to d[k] whenever a default value is more convenient than handling KeyError.
However, when updating the value found (if it is mutable), using either __getitem__ or get is awkward and inefficient.
import sys
import re
WORD_RE = re.compile('\w+')
index = {}
with open(sys.argv[1], encoding='utf-8') as fp:
for line_no, line in enumerate(fp, 1):
for match in WORD_RE.finditer(line):
word = match.group()
column_no = match.start()+1
location = (line_no, column_no)
index.setdefault(word, []).append(location) # <1>
# print in alphabetical order
for word in sorted(index, key=str.upper):
print(word, index[word])
Here the line
my_dict.setdefault(key, []).append(new_value)
…is the same as running…
if key not in my_dict:
my_dict[key] = []
my_dict[key].append(new_value)
Mappings with Flexible Key Lookup
Sometimes it is convenient to have mappings that return some made-up value when a missing key is searched. There are two main approaches to this: one is to use a default dict instead of a plain dict. The other is to subclass dict or any other mapping type and add a missing method.
defaultdict: Another Take on Missing Keys
When instantiating a defaultdict, you provide a callable that is used to produce a default value whenever __getitem__ is passed a nonexistent key argument.
For example, given an empty defaultdict created as dd = defaultdict(list), if 'new-key' is not in dd, the expression dd['new-key'] does the following steps:
- Calls list() to create a new list.
- Inserts the list into dd using 'new-key' as key.
- Returns a reference to that list.
import sys
import re
import collections
WORD_RE = re.compile('\w+')
index = collections.defaultdict(list)
with open(sys.argv[1], encoding='utf-8') as fp:
for line_no, line in enumerate(fp, 1):
for match in WORD_RE.finditer(line):
word = match.group()
column_no = match.start()+1
location = (line_no, column_no)
index[word].append(location)
# print in alphabetical order
for word in sorted(index, key=str.upper):
print(word, index[word])
The default_factory of a defaultdict is only invoked to provide default values for __getitem__ calls, and not for the other methods. For example, if dd is a defaultdict, and k is a missing key, dd[k] will call the default_factory to create a default value, but dd.get(k) still returns None.
The __missing__ Method
Underlying the way mappings deal with missing keys is the apply named __missing__ method.
This method is not defined in the base dict class, but dict is aware of it: if you subclass dict and provide a __missing__ method, the standard dict.__getitem__ will call it whenever a key is not found, instead of raising KeyError.
Note: The __missing__ method is just called by __getitem__ (i.e., for the d[k] operator).
Example 3-6. When searching for a nonstring key, StrKeyDict0 converts it to str when it is not found
class StrKeyDict0(dict):
def __missing__(self, key):
if isinstance(key, str):
raise KeyError(key)
return self[str(key)]
def get(self, key, default=None):
try:
return self[key]
except KeyError:
return default
def __contains__(self, key):
return key in self.keys() or str(key) in self.keys()
>>> d = StrKeyDict0([('2', 'two'), ('4', 'four')])
>>> d['2']
'two'
>>> d[1]
Traceback (most recent call last):
...
KeyError: '1'
>>> d.get('2')
'two'
>>> d.get(4)
'four'
>>> d.get(1, 'N/A')
'N/A'
>>> 2 in d
True
>>> 1 in d
False
A search like k in my_dict.keys() is efficient in Python 3 even for very large mappings because dict.keys() returns a view, which is similar to a set, and containment checks in sets are as fast as in dictionaries.
Variations of dict
we summarize the various mapping types included in the collec
tions module of the standard library, besides defaultdict.
collections.OrderedDict: Maintains keys in insertion order, allowing iteration over items in a predictable order. The popitem method of an OrderedDict pops the first item by default, but if called as my_odict.popitem(last=True), it pops the last item added.
collections.ChainMap: Holds a list of mappings that can be searched as one.
import builtins
pylookup = ChainMap(locals(), globals(), vars(builtins))
- collections.Counter: A mapping that holds an integer count for each key.
>>> ct = collections.Counter('abracadabra')
>>> ct
Counter({'a': 5, 'b': 2, 'r': 2, 'c': 1, 'd': 1})
>>> ct.update('aaaaazzz')
>>> ct
Counter({'a': 10, 'z': 3, 'b': 2, 'r': 2, 'c': 1, 'd': 1})
>>> ct.most_common(2)
[('a', 10), ('z', 3)]
- collections.UserDict: A pure Python implementation of a mapping that works like a standard dict.
Subclassing UserDict
The main reason why it’s preferable to subclass from UserDict rather than from dict is that the built-in has some implementation shortcuts that end up forcing us to override methods that we can just inherit from UserDict with no problems.
Note that UserDict does not inherit from dict, but has an internal dict instance, called data, which holds the actual items.
Thanks to UserDict, StrKeyDict is actually shorter than StrKeyDict0, but it does more.
Example 3-8. StrKeyDict always converts non-string keys to str—on insertion, update, and lookup.
import collections
class StrKeyDict(collections.UserDict):
def __missing__(self, key):
if isinstance(key, str):
raise KeyError(key)
return self[str(key)]
def __contains__(self, key):
return str(key) in self.data
def __setitem__(self, key, item):
self.data[str(key)] = item
Immutable Mappings
The mapping types provided by the standard library are all mutable.
Since Python 3.3, the types module provides a wrapper class called MappingProxy Type, which, given a mapping, returns a mappingproxy instance that is a read-only but dynamic view of the original mapping.
Example 3-9. MappingProxyType builds a read-only mappingproxy instance from a dict.
>>> from types import MappingProxyType
>>> d = {1: 'A'}
>>> d_proxy = MappingProxyType(d)
>>> d_proxy
mappingproxy({1: 'A'})
>>> d_proxy[1]
'A'
>>> d_proxy[2] = 'x'
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'mappingproxy' object does not support item assignment
>>> d[2] = 'B'
>>> d_proxy
mappingproxy({1: 'A', 2: 'B'})
>>> d_proxy[2]
'B'
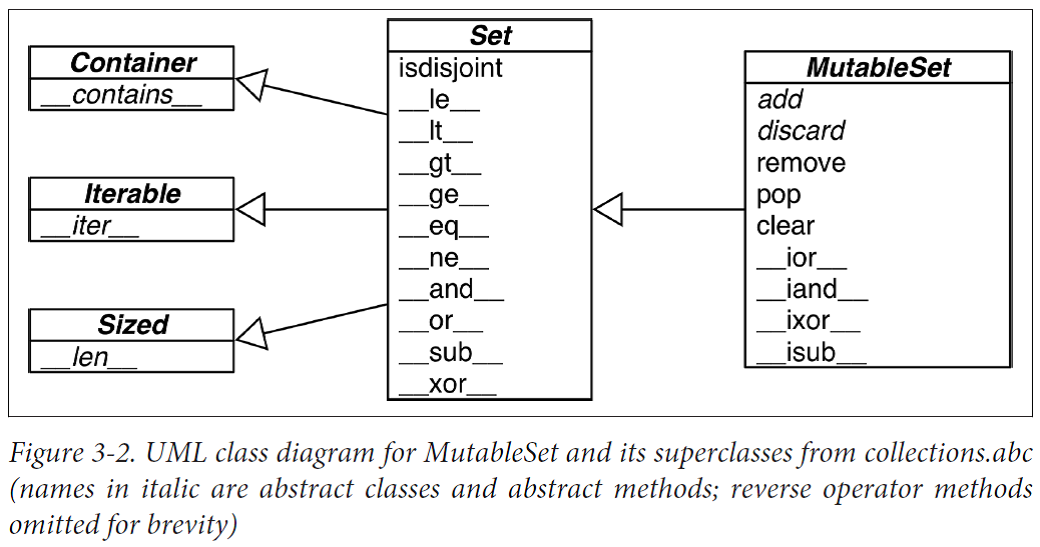
Set Theory
A set is a collection of unique objects. A basic use case is removing duplication.
>>> l = ['spam', 'spam', 'eggs', 'spam']
>>> set(l)
{'eggs', 'spam'}
>>> list(set(l))
['eggs', 'spam']
Set elements must be hashable. The set type is not hashable, but frozenset is, so you can have frozenset elements inside a set.
Example 3-12. Count occurrences of needles in a haystack; these lines work for any iterable types.
found = len(set(needles) & set(haystack))
# another way:
found = len(set(needles).intersection(haystack))
set Literals
Literal set syntax like {1, 2, 3} is both faster and more readable than calling the constructor (e.g., set([1, 2, 3])).
There is no special syntax to represent frozenset literals—they must be created by calling the constructor.
>>> frozenset(range(10))
frozenset({0, 1, 2, 3, 4, 5, 6, 7, 8, 9})
Set Operations
dict and set Under the Hood
Practical Consequences of How dict Works
An object is hashable if all of these requirements are met.
It supports the hash() function via a hash() method that always returns the same value over the lifetime of the object.
It supports equality via an eq() method.
If a == b is True then hash(a) == hash(b) must also be True.
User-defined types are hashable by default because their hash value is their id() and they all compare not equal.
If you implement a class with a custom __eq__ method, you must also implement a suitable __hash__, because you must always make sure that if a == b is True then hash(a) == hash(b) is also True.
Notes:
- Key search is very fast
- Key ordering depends on insertion order
- Adding items to a dict may change the order of existing keys
Further Reading
The Python source code for the module Lib/collections/init.py is a great reference for anyone who wants to create a new mapping type or grok the logic of the existing ones.
Written by A.M. Kuchling—a Python core contributor and author of many pages of the official Python docs and how-tos—Chapter 18, “Python’s Dictionary Implementation: Being All Things to All People, in the book Beautiful Code (O’Reilly) includes a detailed explanation of the inner workings of the Python dict.
Text versus Bytes
Humans use text. Computers speak bytes.
Character Issues
In 2015, the best definition of “character” we have is a Unicode character. The items you get out of a Python 3 str are Unicode characters.
The Unicode standard explicitly separates the identity of characters from specific byte representations:
The identity of a character—its code point—is a number from 0 to 1,114,111 (base 10), shown in the Unicode standard as 4 to 6 hexadecimal digits with a “U+” prefix. For example, the code point for the letter A is U+0041, the Euro sign is U+20AC.
The actual bytes that represent a character depend on the encoding in use. An encoding is an algorithm that converts code points to byte sequences and vice versa. The code point for A (U+0041) is encoded as the single byte \x41 in the UTF-8 encoding, or as the bytes \x41\x00 in UTF-16LE encoding.
Converting from code points to bytes is encoding; converting from bytes to code points is decoding.
Example 4-1. Encoding and decoding
>>> s = 'café'
>>> len(s)
4
>>> b = s.encode('utf8')
>>> b
b'caf\xc3\xa9'
>>> len(b)
5
>>> b.decode('utf8')
'café'
Byte Essentials
There are two basic built-in types for binary sequences: the immutable bytes type introduced in Python 3 and the mutable bytearray, added in Python 2.6. Each item in bytes or bytearray is an integer from 0 to 255. However, a slice of a binary sequence always produces a binary sequence of the same type—including slices of length 1.
Example 4-2. A five-byte sequence as bytes and as bytearray
>>> cafe = bytes('café', encoding='utf_8')
>>> cafe
b'caf\xc3\xa9'
>>> cafe[0]
99
>>> cafe[:1]
b'c'
>>> cafe_arr = bytearray(cafe)
>>> cafe_arr
bytearray(b'caf\xc3\xa9')
>>> cafe_arr[-1:]
bytearray(b'\xa9')
Both bytes and bytearray support every str method except those that do formatting (format, format_map) and a few others that depend on Unicode data.
This means that you can use familiar string methods like endswith, replace, strip, translate, upper, and dozens of others with binary sequences—only using bytes and not str arguments. In addition, the regular expression functions in the re module also work on binary sequences, if the regex is compiled from a binary sequence instead of a str.
Basic Encoders/Decoders
The Python distribution bundles more than 100 codecs (encoder/decoder) for text to byte conversion and vice versa. Each codec has a name, like 'utf_8', and often aliases, such as 'utf8', 'utf-8', and 'U8', which you can use as the encoding argument in functions like open(), str.encode(), bytes.decode(), and so on.
Example 4-5. The string “El Niño” encoded with three codecs producing very different byte sequences.
>>> for codec in ['latin_1', 'utf_8', 'utf_16']:
... print(codec, 'El Niño'.encode(codec), sep='\t')
...
latin_1 b'El Ni\xf1o'
utf_8 b'El Ni\xc3\xb1o'
utf_16 b'\xff\xfeE\x00l\x00 \x00N\x00i\x00\xf1\x00o\x00'
Understanding Encode/Decode Problems
Although there is a generic UnicodeError exception, the error reported is almost always more specific: either a UnicodeEncodeError (when converting str to binary sequences) or a UnicodeDecodeError (when reading binary sequences into str).
Coping with UnicodeEncodeError
Most non-UTF codecs handle only a small subset of the Unicode characters. When converting text to bytes, if a character is not defined in the target encoding, UnicodeEncodeError will be raised, unless special handling is provided by passing an errors argument to the encoding method or function.
Example 4-6. Encoding to bytes: success and error handling.
>>> city = 'São Paulo'
>>> city.encode('utf_8')
b'S\xc3\xa3o Paulo'
>>> city.encode('utf_16')
b'\xff\xfeS\x00\xe3\x00o\x00 \x00P\x00a\x00u\x00l\x00o\x00'
>>> city.encode('iso8859_1')
b'S\xe3o Paulo'
>>> city.encode('cp437')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/.../lib/python3.4/encodings/cp437.py", line 12, in encode
return codecs.charmap_encode(input,errors,encoding_map)
UnicodeEncodeError: 'charmap' codec can't encode character '\xe3' in
position 1: character maps to <undefined>
>>> city.encode('cp437', errors='ignore')
b'So Paulo'
>>> city.encode('cp437', errors='replace')
b'S?o Paulo'
>>> city.encode('cp437', errors='xmlcharrefreplace')
b'São Paulo'
Coping with UnicodeDecodeError
Not every byte holds a valid ASCII character, and not every byte sequence is valid UTF-8 or UTF-16; therefore, when you assume one of these encodings while converting a binary sequence to text, you will get a UnicodeDecodeError if unexpected bytes are found.
On the other hand, many legacy 8-bit encodings like 'cp1252', 'iso8859_1', and 'koi8_r' are able to decode any stream of bytes, including random noise, without generating errors. Therefore, if your program assumes the wrong 8-bit encoding, it will silently decode garbage.
Example 4-7 illustrates how using the wrong codec may produce gremlins or a UnicodeDecodeError.
>>> octets = b'Montr\xe9al'
>>> octets.decode('cp1252')
'Montréal'
>>> octets.decode('iso8859_7')
'Montrιal'
>>> octets.decode('koi8_r')
'MontrИal'
>>> octets.decode('utf_8')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xe9 in position 5:
invalid continuation byte
>>> octets.decode('utf_8', errors='replace')
'MontrÜal'
SyntaxError When Loading Modules with Unexpected Encoding
To fix this problem, add a magic coding comment at the top of the file.
# coding: cp1252
print('Olá, Mundo!')
How to Discover the Encoding of a Byte Sequence
How do you find the encoding of a byte sequence? Short answer: you can’t. You must be told.
Chardet is a Python library that you can use in your programs, but also includes a command-line utility, chardetect.
Handling Text Files
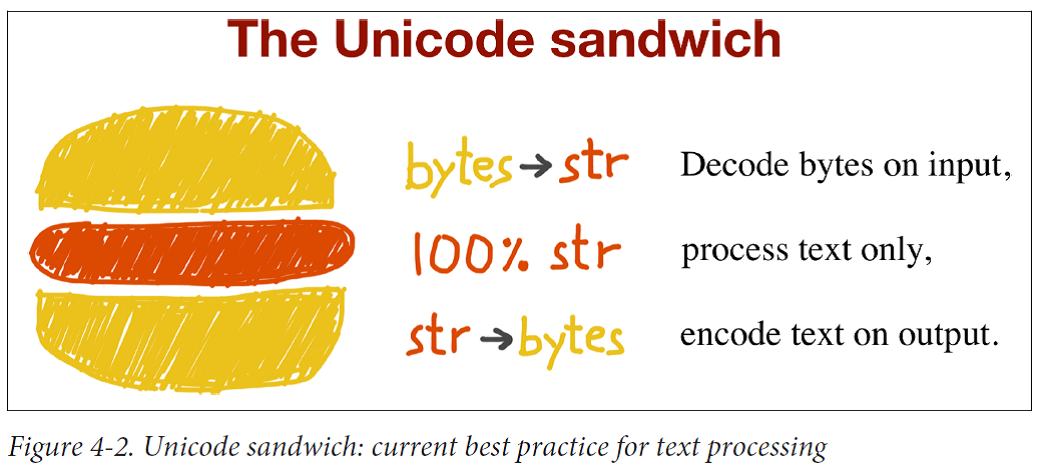
The best practice for handling text is the “Unicode sandwich”. This means that bytes should be decoded to str as early as possible on input (e.g., when opening a file for reading). The “meat” of the sandwich is the business logic of your program, where text handling is done exclusively on str objects. You should never be encoding or decoding in the middle of other processing. On output, the str are encoded to bytes as late as possible.
Example 4-9. A platform encoding issue (if you try this on your machine, you may or may not see the problem)
>>> open('cafe.txt', 'w', encoding='utf_8').write('café')
4
>>> open('cafe.txt').read()
'café'
The bug: I specified UTF-8 encoding when writing the file but failed to do so when reading it, so Python assumed the system default encoding—Windows 1252—and the trailing bytes in the file were decoded as characters 'é' instead of 'é'.
Code that has to run on multiple machines or on multiple occasions should never depend on encoding defaults. Always pass an explicit encoding= argument when opening text files, because the default may change from one machine to the next, or from one day to the next.
Example 4-10. Closer inspection of Example 4-9 running on Windows reveals the bug and how to fix it
>>> fp = open('cafe.txt', 'w', encoding='utf_8')
>>> fp
<_io.TextIOWrapper name='cafe.txt' mode='w' encoding='utf_8'>
>>> fp.write('café')
4
>>> fp.close()
>>> import os
>>> os.stat('cafe.txt').st_size
5
>>> fp2 = open('cafe.txt')
>>> fp2
<_io.TextIOWrapper name='cafe.txt' mode='r' encoding='cp1252'>
>>> fp2.encoding
'cp1252'
>>> fp2.read()
'café'
>>> fp3 = open('cafe.txt', encoding='utf_8')
>>> fp3
<_io.TextIOWrapper name='cafe.txt' mode='r' encoding='utf_8'>
>>> fp3.read()
'café'
>>> fp4 = open('cafe.txt', 'rb')
>>> fp4
<_io.BufferedReader name='cafe.txt'>
>>> fp4.read()
b'caf\xc3\xa9'
The Unicode Database
The Unicode standard provides an entire database—in the form of numerous structured text files—that includes not only the table mapping code points to character names, but also metadata about the individual characters and how they are related.
For example, the Unicode database records whether a character is printable, is a letter, is a decimal digit, or is some other numeric symbol.
Example 4-21. Demo of Unicode database numerical character metadata (callouts describe each column in the output)
import unicodedata
import re
re_digit = re.compile(r'\d')
sample = '1\xbc\xb2\u0969\u136b\u216b\u2466\u2480\u3285'
for char in sample:
print('U+%04x' % ord(char),
char.center(6),
're_dig' if re_digit.match(char) else '-',
'isdig' if char.isdigit() else '-',
'isnum' if char.isnumeric() else '-',
format(unicodedata.numeric(char), '5.2f'),
unicodedata.name(char),
sep='\t')
Further Reading
Ned Batchelder’s 2012 PyCon US talk “Pragmatic Unicode — or — How Do I Stop the Pain?” was outstanding.
Chapter 4, “Strings”, of Mark Pilgrim’s awesome book Dive into Python 3 also provides a very good intro to Unicode support in Python 3.
Armin Ronacher’s blog post “The Updated Guide to Unicode
on Python” is deep and highlights some of the pitfalls of Unicode in Python 3.
